




 本文探讨HashMap的设计原理,从为何需要HashMap开始,分析其通过hash函数将key映射到存储位置的思路,以及如何处理hash碰撞。介绍拉链法解决冲突,并讨论HashMap的构造函数、扩容机制和红黑树的应用,帮助读者深入理解HashMap的内部运作。
本文探讨HashMap的设计原理,从为何需要HashMap开始,分析其通过hash函数将key映射到存储位置的思路,以及如何处理hash碰撞。介绍拉链法解决冲突,并讨论HashMap的构造函数、扩容机制和红黑树的应用,帮助读者深入理解HashMap的内部运作。
知其然也要知其所以然,很多人讲 HashMap 都是看下源码,分析下,然后知道了什么拉链法,桶,红黑树,看了一圈,好像懂了,又好像没懂。本着死苛的精神,我来尝试谈下我对 HashMap 理解,个人只见,有错误之处,欢迎批评指出。
为什么要设计 HashMap?
Map 我们都很好理解,就是 key,value 的容器。用来存储和获取以键值对存在的数据结构。比如统计每个人有多少 money:
| 张三 | 100 |
| 李四 | 90 |
| 王二 | 80 |
按照正常的简单需求,我们一般对需要数据进行增删改查,无论是增、删、改、查,在计算机中对数据访问最重要的是更快的查到数据正确的存储位置。怎样来设计这种key、value 数据结构的存储,使得增删改查都比较高效呢?下面我们就来整理思路,并尝试理解 HashMap 的设计思路及实现细节。
首先,我们针对上面的数据实体抽象出一个实体类
class Entry{
String key;
int value;
}
现在我们用最简单的思路顺序存储或者链式存储,把这些数据存起来,如下图:

按照上面的存储方式,给定 key 值,我们想要查询一个 Entry,需要对比遍历看 key 值是否相等,才能查到。显然 map 用这两种方式实现都是很低效的。
理想状态下,我们想要实现的是给定 key 值,就能直接得到存储位置,这样查找效率就很高。要想实现这样的目的,很显然,key 值要和具体的地址产生对应关系。而这种对应关系,就是 hash 函数。那么怎么来构造这种对应关系呢?
因为链式存储即使知道存储的相对位置也许要多次查找,所以这种实现必然是和顺序存储相关的。
所以,我们可以这样设计对应关系:
首先任意长度的字符序列都能由固定的 hash 算法生成一串 hashcode ,所以每个 key 都有自己的 hashcode。我们把这个 hashcode 看做一个二进制数。当然这些二进制数很大,要想使他们映射到一个连续的较小的顺序存储的下标,最简单的办法就是对这些数求余数啦。
假设:
张三的 hashcode = 101000111000(二进制)
李四的 hashcode = 100000001101(二进制)
王二的 hashcode = 100000111110(二进制)
为了方便求余计算,HashMap 容量为 100(二进制)
得出:
张三:100000001101%100 = 0
李四:100000001101%100 = 1
王二:100000111110%100 = 2
所以HashMap 中这三个 Entry 的存储图如下:
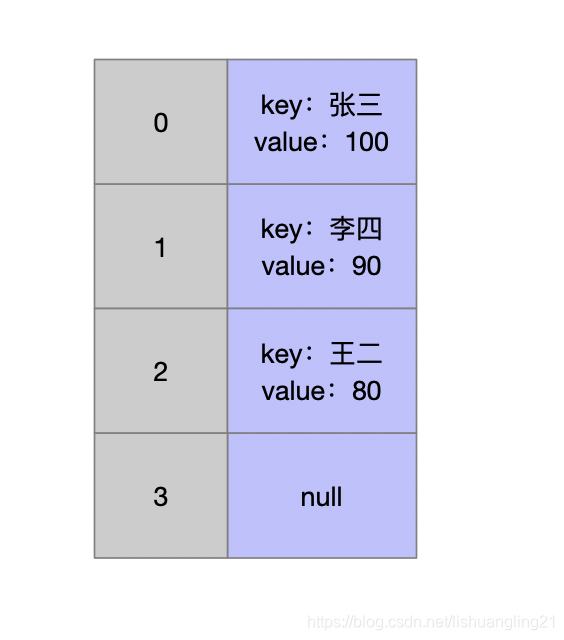
这样的数据结构就满足了高效率的要求。根据 key 的 hashcode 进行求余就可以找到对应 HashMap 中的位置进行增删改查了。
现在还存在这样一个问题,如果刘五有 70 块钱,这个数据我们也想存进 HashMap:
刘五的 hashcode = 111110111101 对 100 求余得 1,可是1 的位置已经存入了李四的数据,这时候该怎么办呢?
这种情况,其实就是 hash 碰撞,又叫 hash 冲突。我们把求余看做是 hash 函数的计算公式,只要存入的数据多于 HashMap 的容量,就必然有重复,必然有冲突。其实就算一个很大的 HashMap,只存入两个Entry,也有冲突的可能(hashcode 余数相同)。
针对这种 hash 碰撞,我们该如何处理呢?其实也很好解决,可以用下图的方式解决:
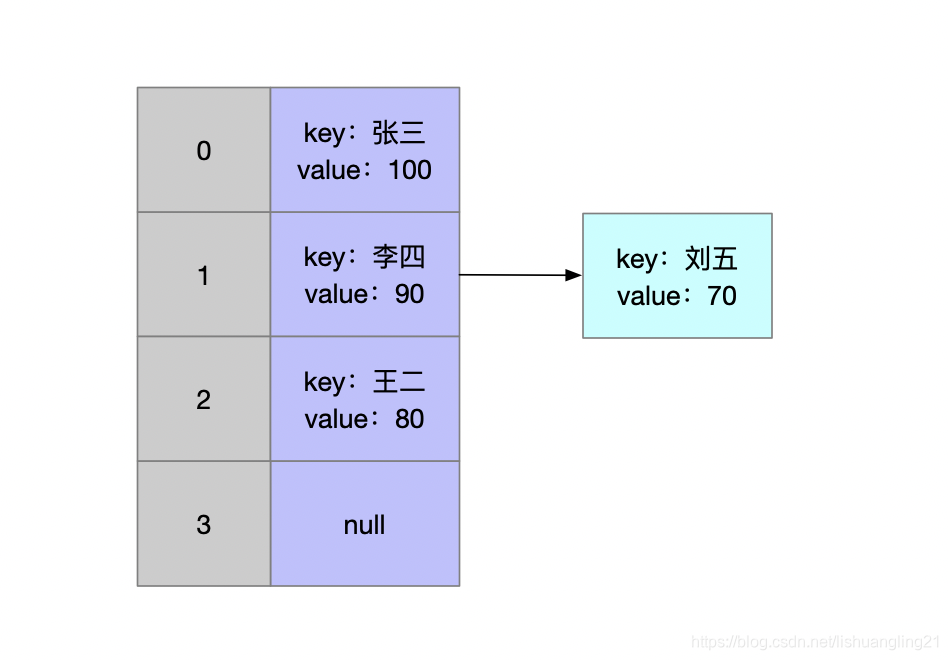
这就是拉链法,先根据 key 的 hashcode 进行求余,得到数组下标,然后再比较 key 值,确定要增删改查的 Entry,这也就意味着Entry 的数据结构需要再增加一个 next 指针:
class Entry{
String key;
int value;
Entry next;
}
到这里 HashMap 我们已经设计的差不多了,其实源码里也就这点东西。下面跟一下源码,对一些概念做下补充。
首先来看 HashMap 的构造函数:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
initialCapacity 初始容量
loadFactor 加载因子
HashMap 创建的时候可以设置一个初始容量(没有设置则默认为 16),上面我们已经讲了,这个容量是用来求余计算桶下标的。如果容量过小,而存储的数据过多,就会出现大量的碰撞:
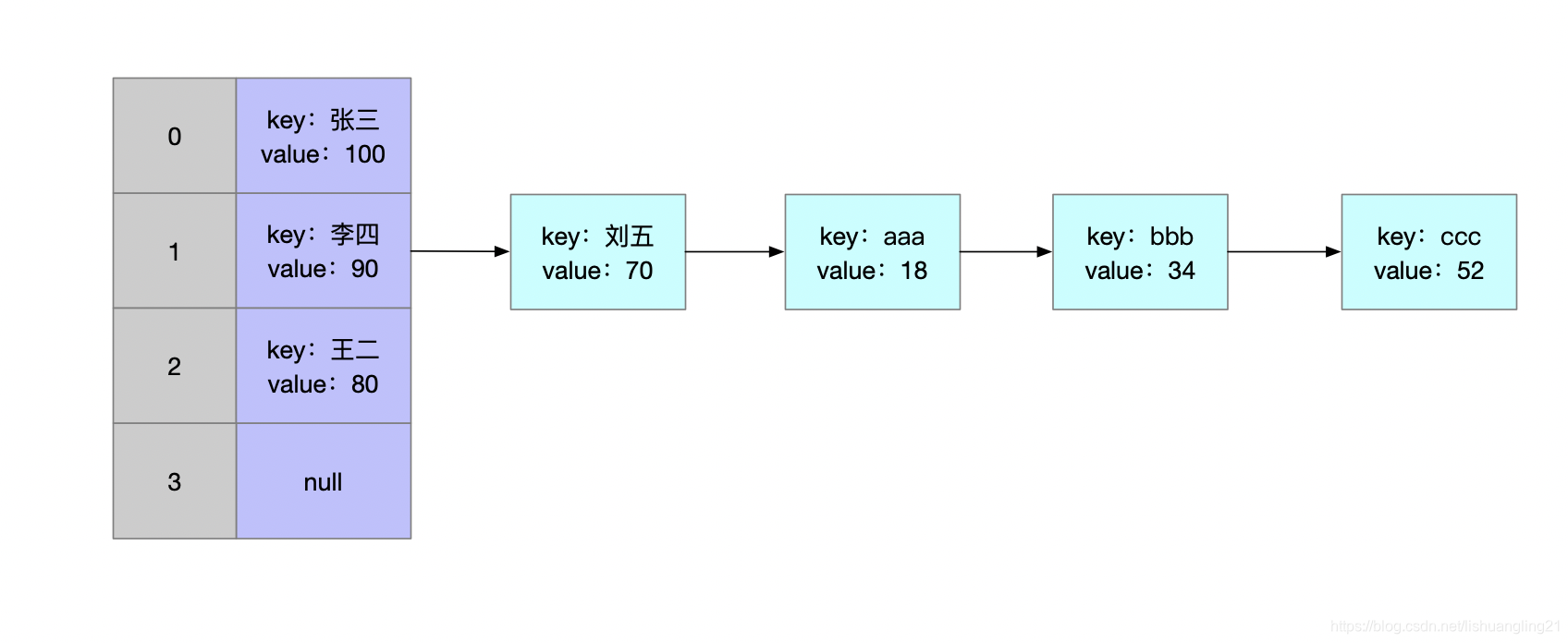
如上图:桶 1 的位置已经有 5 个 Entry 了。如果容量小,而要存的数据多,可能会有更长的链表,这时如果要操作链表尾端的 ccc就会大大降低 HashMap 的效率。所以必需对这种情况进行处理,处理方法:
当 HashMap 存储的 Entry 多于某个临界点时,就要对 HashMap 进行扩容。这个初始默认临界点就是
initialCapacity * loadFactor
loadFactor 默认取值是 0.75,下面是 HashMap 判断扩容的代码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//第一次存储数据进行初始化
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
。。。
}
++modCount;
if (++size > threshold)
//当容量大于临界值,进行扩容
resize();
afterNodeInsertion(evict);
return null;
}
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//临界值变为原来的两倍,容量也变为原来的两倍,临界值依然是 容量*加载因子
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
//初始化时,用默认容量*默认加载因子
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
。。。
}
return newTab;
}
上面代码加注释已经很清楚了,扩容临界点就是:当前容量 *加载因子。
容量选择:HashMap 容量选择都是 2 的 N 次方。
因为每次扩容,都要重新计算余数,再一次整理 HashMap 里的桶和链表,会有较大的性能开销。选2 的 N 次方,是为了进行位运算,提高效率。
对 2 的 N 次方求余可以用 & 进行位运算,这个很简单不再展开。
关于红黑树: 1.8 引入红黑树,不过是对上面拉链法的补充。
如果某个桶上的链表过长,也就是好多个 key 的 hashcode 求余得到的位置指向同一个桶,会导致针对这个桶链表的操作效率会大大降低,为了改善这种情况引入了红黑树,当链表节点大于 7 个时,把链表结构转化为红黑树结构,来降低查找的开销。红黑树只是平衡二叉树的一种实现,其目的就是减少查找层级,优化极端情况下的查找速度。这里理解其优化思想即可,不再深究。
最后,HashMap 图(懒得画了,网上找的,侵删)


















 8510
8510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









