







**
java集合的总结(Set,Map,List,Array)
**
重点掌握数组,ArrayList,HashMap,HashSet,和ConcurrentHashMap

首先先看看集合的关系图:
=~=Array==
1.只能存放单一类型
2.必须指定数组的长度 不可控 长度过长,会造成内存浪费,过短会造成数据溢出
3.值默认为null
4.在内存中是连续存储的,所以它的索引速度非常快。
5.两个数据间插入数据是很麻烦的,只能根据角标插入
=~ArrayList(动态数组)
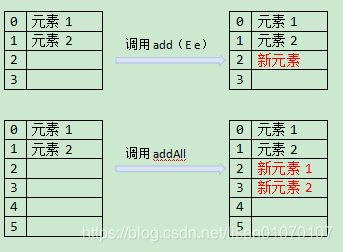
目的:为了解决数组的长度不可控,只能存放单一类型的缺陷。
1.可以存放多种类型,但是这样性能慢,有装箱和拆箱,所以出现泛型
2.底层就是数组, 因此按序查找快, 乱序插入, 删除涉及后面元素移位的所以性能慢.
3.要remove一个元素,循环遍历数组, 判断E是否equals当前元素, 删除性能不如LinkedList.
4.默认容量是10, 扩容后,即0.5倍增长.扩容后会重新创建一个对象,将原有的值转移过去。
5.动态数组,查询数据快。只要不是在末尾添加或删除元素,那么元素的位置都要进行移动.
比如代码:
ArrayList l = new ArrayList<>();
l.add("212");
l.add("21212121");
l.add(1,"jjd");
这边数据右边的就需要移位,所以中间添加删除的效率慢
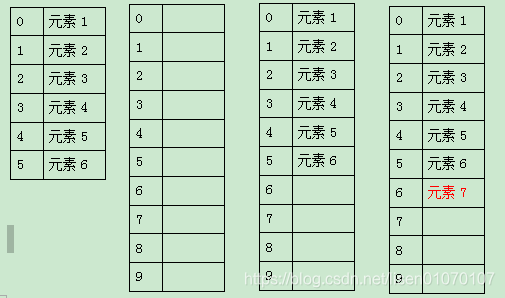
6.ArrayList只有把元素添加进去之后才可以通过下标访问相应的元素(数组是可以的)
7.线程安全的
数组跟ArrayList的使用场景:如果已经知道数据的长度并且不需要频繁的做插入和删除操作,建议使用数组,反之亦然。
正确的预估可能的元素,并且在适当的时候设置长度是提高ArrayList使用效率的重要途径

LinkedList
目的:为了解决ArrayList的乱序插入删除的性能缺陷
单链表只能向后操作,不可以向前操作。为了向前、向后操作方便,可以给每个元素附加两个指针域(head,tail),即双向链表。
1.经典的双链表结构, 且头结点中不存放数据。适用于乱序插入, 删除. 指定序列操作则性能不如ArrayList, 这也是其数据结构决定的.
2.get(index)也是会先判断index, 不过性能依然不好, 这也是为什么不推荐用for(int i = 0; i < lengh; i++)的方式遍历linkedlist, 而是使用iterator的方式遍历.
3.线程不安全的,所以平常也看不到使用LinkedList
对比ArrayList
对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
Stack
栈 经典的数据结构, 底层也是数组, 继承自Vector, 先进后出FILO, 默认new Stack()容量为10, 超出自动扩容.
E push(E item) //把项压入堆栈顶部。
E pop() //移除堆栈顶部的对象,并作为此函数的值返回该对象。
E peek() //查看堆栈顶部的对象,但不从堆栈中移除它。
boolean empty() //测试堆栈是否为空。
int search(Object o) //返回对象在堆栈中的位置,以 1 为基数。
ArrayBlockingQueue(阻塞队列)
take() 当元素被取出后, 并没有对数组后面的元素位移, 而是更新takeIndex来指向下一个元素.
takeIndex是一个环形的增长, 当移动到队列尾部时, 会指向0, 再次循环.
队列 与Stack的区别在于, Stack的删除与添加都在队尾进行, 而Queue删除在队头, 添加在队尾.
JDK7提供了7个阻塞队列。分别是
ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
DelayQueue:一个使用优先级队列实现的无界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
HashSet
目的:存放不同的对象的集合,底层都是HashMap
单列的hash表 存储不同数据 无序 不能传null
1.依赖两个方法:hashCode()和equals()
2.说白了,HashSet就是限制了功能的HashMap,所以了解HashMap的实现原理,这个HashSet自然就通
3.对于HashSet中保存的对象,主要要正确重写equals方法和hashCode方法,以保证放入Set对象的唯一性
4.虽说是Set是对于重复的元素不放入,倒不如直接说是底层的Map直接把原值替代了(这个Set的put方法的返回值真有意思)
5.HashSet没有提供get()方法,原因是同HashMap一样,Set内部是无序的,只能通过迭代的方式获得
LinkedHashSet
LinkedHashSet是继承自HashSet,底层实现是LinkedHashMap
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
TreeSet
底层数据结构是红黑树。(唯一,有序)
- 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
HashMap
目的:解决了数组查询某个元素的性能堪忧的问题。
1.最常用的哈希表, 面试的童鞋必备知识了, 内部通过 数组 + 单链表 的方式实现. jdk8中引入了红黑树对长度 > 8的链表进行优化。
2.HashMap 数组每一个元素的初始值都是 Null。

3.HashMap 的长度是有限的,当插入的 Entry 越来越多时,再完美的 Hash 函数也难免会出现 index 冲突的情况。所以加入了单链表。同一角标可插入多个。(同样查询先查到对应数组角标,再去链表查询)
一般后插入的放在前面,方便查找,一般查找都是找后面的节点。
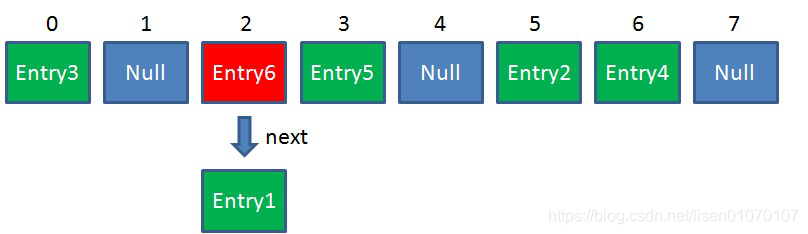
4.默认长度是16.宽容为2的指数幂,原因就是插入数据根据HashCode跟长度-1的二进制进行与运算,达到平均分配的作用。Index是数组的角标。
就拿8来:
Hashcode 10111111000111 1011
Length-1 1111
Index 1111
始终是HashCode的后四位的值
5.负载因子在0.75 ,比如16的长度达到12就会进行扩容,扩容之后会进行重新hash计算重新分配因为length改变了,计算的值也不会一样了。
6.众所周知,HashMap 是一个用于存储Key-Value键值对的集合,每一个键值对也叫做 Entry。
7.当map中元素超出设定的阈值后, 会进行resize (length * 2)操作, 扩容过程中对元素一通操作, 并放置到新的位置.
具体操作如下:
在jdk7中对所有元素直接rehash, 并放到新的位置.
在jdk8中判断元素原hash值新增的bit位是0还是1, 0则索引不变, 1则索引变成"原索引 + oldTable.length".
8.是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
9.HashMap 实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。
LinkedHashMap
继承自HashMap, 底层额外维护了一个双向链表来维持数据有序. 可以通过设置accessOrder来实现FIFO(插入有序)或者LRU(访问有序)缓存.
主要在HashMap的基础之上有加了一个双向链表达到有序的目的,就是每插入一个节点通过一个双向链表连起来。
HashTable
所有的方法都是同步的 线程安全的
Collections.synchronizedMap();也是一个HashTable
ConcurrentHashMap
1.分段锁 线程安全的 IOC就是采用这个map集合来存放的
效率大概是HashTable的16倍 在内部创建同步 相当于16个内部的HashTable
2.但是高版本的JDK已经取消了分段锁segment,(采用table数组元素链表的首个元素或者红黑色的根节点)作为锁。
3.红黑树叫平衡二叉树,二叉树的优点就是查询快(但是当一个链过长,又等于一个长的链表,查询就慢了,所以红黑树解决了这个问题),平衡二叉树会通过左旋,右旋来解决。
4.如果链表的长度>8且数组的node>64的时候就链表就转化为红黑树,当出现扩容的时候,链表<8的时候就把红黑树转化为链表。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









