



 文章详细描述了Hudi在0.13.1版本中如何将Hoodie元数据的avroSchema转换为parquet的MessageType,进而同步到HiveMetastore的过程。涉及的关键步骤包括读取Hoodie元数据、转换表结构、创建Hive表以及处理分区列。Hudi通过HoodieHiveSyncClient、TableSchemaResolver和HiveSyncTool等类实现了这一流程。
文章详细描述了Hudi在0.13.1版本中如何将Hoodie元数据的avroSchema转换为parquet的MessageType,进而同步到HiveMetastore的过程。涉及的关键步骤包括读取Hoodie元数据、转换表结构、创建Hive表以及处理分区列。Hudi通过HoodieHiveSyncClient、TableSchemaResolver和HiveSyncTool等类实现了这一流程。
hudi的hiveSync同步表结构流程
hudi版本: 0.13.1
总体流程
(1)读取hoodie meta并获取avro SchemaStr,转化为avro Schema
(2)将avro Schema转换为parquet的 MessageType
(3)将parquet 的 MessageType转化为hive metastore的 List<FieldSchema>
(4)最终执行通过hive metastore 接口IMetaStoreClient的实现类 执行更新表
HoodieHiveSyncClient
@Override
public void createTable(String tableName, MessageType storageSchema, String inputFormatClass,
String outputFormatClass, String serdeClass,
Map<String, String> serdeProperties, Map<String, String> tableProperties) {
ddlExecutor.createTable(tableName, storageSchema, inputFormatClass, outputFormatClass, serdeClass, serdeProperties, tableProperties);
}
HoodieHiveSyncClient的父类HoodieSyncClient
@Override
public MessageType getStorageSchema(boolean includeMetadataField) {
try {
return new TableSchemaResolver(metaClient).getTableParquetSchema(includeMetadataField);
} catch (Exception e) {
throw new HoodieSyncException("Failed to read schema from storage.", e);
}
}
TableSchemaResolver
解析avro schema并生成 parquet的 MessageType
public MessageType getTableParquetSchema(boolean includeMetadataField) throws Exception {
return convertAvroSchemaToParquet(getTableAvroSchema(includeMetadataField));
}
包装方法:
/**
* Gets schema for a hoodie table in Avro format, can choice if include metadata fields.
*
* @param includeMetadataFields choice if include metadata fields
* @return Avro schema for this table
* @throws Exception
*/
public Schema getTableAvroSchema(boolean includeMetadataFields) throws Exception {
return getTableAvroSchemaInternal(includeMetadataFields, Option.empty());
}
此方法回去已经提交的hoodie中索取SchemaStr并转化为schema
private final Lazy<ConcurrentHashMap<HoodieInstant, HoodieCommitMetadata>> commitMetadataCache;
private volatile HoodieInstant latestCommitWithValidSchema = null;
getTableSchemaFromCommitMetadata --> 对应对象 commitMetadataCache
getTableSchemaFromLatestCommitMetadata —> 对应对象 latestCommitWithValidSchema
private Schema getTableAvroSchemaInternal(boolean includeMetadataFields, Option<HoodieInstant> instantOpt) {
Schema schema =
(instantOpt.isPresent()
? getTableSchemaFromCommitMetadata(instantOpt.get(), includeMetadataFields)
: getTableSchemaFromLatestCommitMetadata(includeMetadataFields))
.or(() ->
metaClient.getTableConfig().getTableCreateSchema()
.map(tableSchema ->
includeMetadataFields
? HoodieAvroUtils.addMetadataFields(tableSchema, hasOperationField.get())
: tableSchema)
)
.orElseGet(() -> {
Schema schemaFromDataFile = getTableAvroSchemaFromDataFile();
return includeMetadataFields
? schemaFromDataFile
: HoodieAvroUtils.removeMetadataFields(schemaFromDataFile);
});
// TODO partition columns have to be appended in all read-paths
if (metaClient.getTableConfig().shouldDropPartitionColumns()) {
return metaClient.getTableConfig().getPartitionFields()
.map(partitionFields -> appendPartitionColumns(schema, Option.ofNullable(partitionFields)))
.orElse(schema);
}
return schema;
}
getTableSchemaFromLatestCommitMetadata 获取的
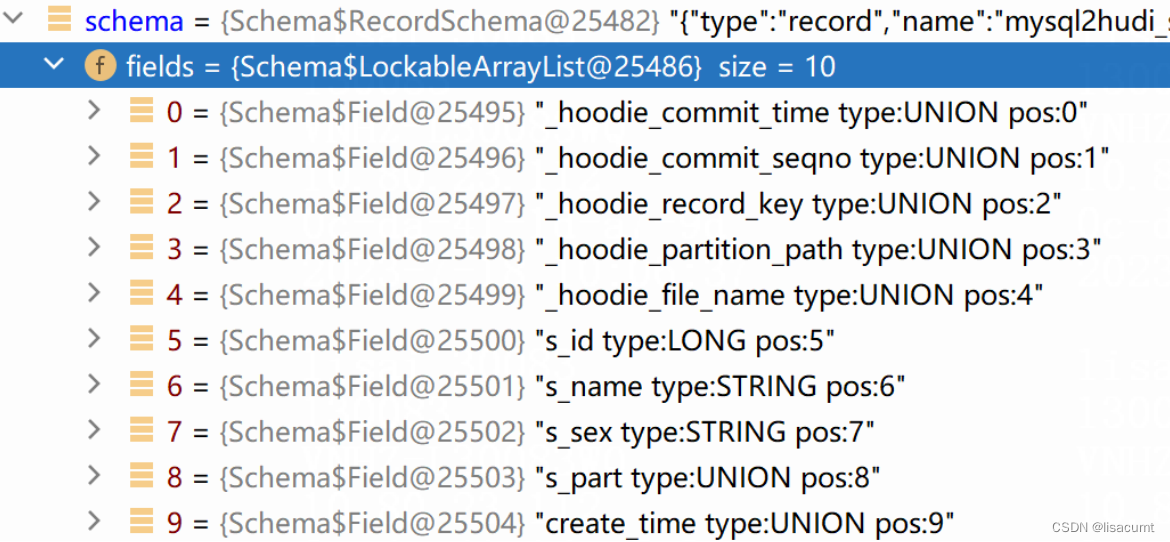
从avro的 schema转化为 Parquet的MessageType
private MessageType convertAvroSchemaToParquet(Schema schema) {
AvroSchemaConverter avroSchemaConverter = new AvroSchemaConverter(metaClient.getHadoopConf());
return avroSchemaConverter.convert(schema);
}
public MessageType convert(Schema avroSchema) {
if (!avroSchema.getType().equals(Schema.Type.RECORD)) {
throw new IllegalArgumentException("Avro schema must be a record.");
}
return new MessageType(avroSchema.getFullName(), convertFields(avroSchema.getFields()));
}
private List<Type> convertFields(List<Schema.Field> fields) {
List<Type> types = new ArrayList<Type>();
for (Schema.Field field : fields) {
if (field.schema().getType().equals(Schema.Type.NULL)) {
continue; // Avro nulls are not encoded, unless they are null unions
}
types.add(convertField(field));
}
return types;
}
HiveSyncTool
同步表方法:
注意此处重要 的是MessageType的获取方法。
protected void syncHoodieTable(String tableName, boolean useRealtimeInputFormat, boolean readAsOptimized) {
LOG.info("Trying to sync hoodie table " + tableName + " with base path " + syncClient.getBasePath()
+ " of type " + syncClient.getTableType());
// check if the database exists else create it
if (config.getBoolean(HIVE_AUTO_CREATE_DATABASE)) {
try {
if (!syncClient.databaseExists(databaseName)) {
syncClient.createDatabase(databaseName);
}
} catch (Exception e) {
// this is harmless since table creation will fail anyways, creation of DB is needed for in-memory testing
LOG.warn("Unable to create database", e);
}
} else {
if (!syncClient.databaseExists(databaseName)) {
LOG.error("Hive database does not exist " + databaseName);
throw new HoodieHiveSyncException("hive database does not exist " + databaseName);
}
}
// Check if the necessary table exists
boolean tableExists = syncClient.tableExists(tableName);
// Get the parquet schema for this table looking at the latest commit
MessageType schema = syncClient.getStorageSchema(!config.getBoolean(HIVE_SYNC_OMIT_METADATA_FIELDS));
// Currently HoodieBootstrapRelation does support reading bootstrap MOR rt table,
// so we disable the syncAsSparkDataSourceTable here to avoid read such kind table
// by the data source way (which will use the HoodieBootstrapRelation).
// TODO after we support bootstrap MOR rt table in HoodieBootstrapRelation[HUDI-2071], we can remove this logical.
if (syncClient.isBootstrap()
&& syncClient.getTableType() == HoodieTableType.MERGE_ON_READ
&& !readAsOptimized) {
config.setValue(HIVE_SYNC_AS_DATA_SOURCE_TABLE, "false");
}
// Sync schema if needed
boolean schemaChanged = syncSchema(tableName, tableExists, useRealtimeInputFormat, readAsOptimized, schema);
LOG.info("Schema sync complete. Syncing partitions for " + tableName);
// Get the last time we successfully synced partitions
Option<String> lastCommitTimeSynced = Option.empty();
if (tableExists) {
lastCommitTimeSynced = syncClient.getLastCommitTimeSynced(tableName);
}
LOG.info("Last commit time synced was found to be " + lastCommitTimeSynced.orElse("null"));
boolean partitionsChanged;
if (!lastCommitTimeSynced.isPresent()
|| syncClient.getActiveTimeline().isBeforeTimelineStarts(lastCommitTimeSynced.get())) {
// If the last commit time synced is before the start of the active timeline,
// the Hive sync falls back to list all partitions on storage, instead of
// reading active and archived timelines for written partitions.
LOG.info("Sync all partitions given the last commit time synced is empty or "
+ "before the start of the active timeline. Listing all partitions in "
+ config.getString(META_SYNC_BASE_PATH)
+ ", file system: " + config.getHadoopFileSystem());
partitionsChanged = syncAllPartitions(tableName);
} else {
List<String> writtenPartitionsSince = syncClient.getWrittenPartitionsSince(lastCommitTimeSynced);
LOG.info("Storage partitions scan complete. Found " + writtenPartitionsSince.size());
// Sync the partitions if needed
// find dropped partitions, if any, in the latest commit
Set<String> droppedPartitions = syncClient.getDroppedPartitionsSince(lastCommitTimeSynced);
partitionsChanged = syncPartitions(tableName, writtenPartitionsSince, droppedPartitions);
}
boolean meetSyncConditions = schemaChanged || partitionsChanged;
if (!config.getBoolean(META_SYNC_CONDITIONAL_SYNC) || meetSyncConditions) {
syncClient.updateLastCommitTimeSynced(tableName);
}
LOG.info("Sync complete for " + tableName);
}
同步shchema到hive方法
其中MessageType是parquet的数据结构描述
根据表是否已经存在执行:(1)syncClient.updateTableSchema (2)syncClient.createTable
/**
* Get the latest schema from the last commit and check if its in sync with the hive table schema. If not, evolves the
* table schema.
*
* @param tableExists does table exist
* @param schema extracted schema
*/
private boolean syncSchema(String tableName, boolean tableExists, boolean useRealTimeInputFormat,
boolean readAsOptimized, MessageType schema) {
// Append spark table properties & serde properties
Map<String, String> tableProperties = ConfigUtils.toMap(config.getString(HIVE_TABLE_PROPERTIES));
Map<String, String> serdeProperties = ConfigUtils.toMap(config.getString(HIVE_TABLE_SERDE_PROPERTIES));
if (config.getBoolean(HIVE_SYNC_AS_DATA_SOURCE_TABLE)) {
Map<String, String> sparkTableProperties = SparkDataSourceTableUtils.getSparkTableProperties(config.getSplitStrings(META_SYNC_PARTITION_FIELDS),
config.getStringOrDefault(META_SYNC_SPARK_VERSION), config.getIntOrDefault(HIVE_SYNC_SCHEMA_STRING_LENGTH_THRESHOLD), schema);
Map<String, String> sparkSerdeProperties = SparkDataSourceTableUtils.getSparkSerdeProperties(readAsOptimized, config.getString(META_SYNC_BASE_PATH));
tableProperties.putAll(sparkTableProperties);
serdeProperties.putAll(sparkSerdeProperties);
}
boolean schemaChanged = false;
// Check and sync schema
if (!tableExists) {
LOG.info("Hive table " + tableName + " is not found. Creating it with schema " + schema);
HoodieFileFormat baseFileFormat = HoodieFileFormat.valueOf(config.getStringOrDefault(META_SYNC_BASE_FILE_FORMAT).toUpperCase());
String inputFormatClassName = HoodieInputFormatUtils.getInputFormatClassName(baseFileFormat, useRealTimeInputFormat);
if (baseFileFormat.equals(HoodieFileFormat.PARQUET) && config.getBooleanOrDefault(HIVE_USE_PRE_APACHE_INPUT_FORMAT)) {
// Parquet input format had an InputFormat class visible under the old naming scheme.
inputFormatClassName = useRealTimeInputFormat
? com.uber.hoodie.hadoop.realtime.HoodieRealtimeInputFormat.class.getName()
: com.uber.hoodie.hadoop.HoodieInputFormat.class.getName();
}
String outputFormatClassName = HoodieInputFormatUtils.getOutputFormatClassName(baseFileFormat);
String serDeFormatClassName = HoodieInputFormatUtils.getSerDeClassName(baseFileFormat);
// Custom serde will not work with ALTER TABLE REPLACE COLUMNS
// https://github.com/apache/hive/blob/release-1.1.0/ql/src/java/org/apache/hadoop/hive
// /ql/exec/DDLTask.java#L3488
syncClient.createTable(tableName, schema, inputFormatClassName,
outputFormatClassName, serDeFormatClassName, serdeProperties, tableProperties);
schemaChanged = true;
} else {
// Check if the table schema has evolved
Map<String, String> tableSchema = syncClient.getMetastoreSchema(tableName);
SchemaDifference schemaDiff = HiveSchemaUtil.getSchemaDifference(schema, tableSchema, config.getSplitStrings(META_SYNC_PARTITION_FIELDS),
config.getBooleanOrDefault(HIVE_SUPPORT_TIMESTAMP_TYPE));
if (!schemaDiff.isEmpty()) {
LOG.info("Schema difference found for " + tableName + ". Updated schema: " + schema);
syncClient.updateTableSchema(tableName, schema);
// Sync the table properties if the schema has changed
if (config.getString(HIVE_TABLE_PROPERTIES) != null || config.getBoolean(HIVE_SYNC_AS_DATA_SOURCE_TABLE)) {
syncClient.updateTableProperties(tableName, tableProperties);
syncClient.updateSerdeProperties(tableName, serdeProperties);
LOG.info("Sync table properties for " + tableName + ", table properties is: " + tableProperties);
}
schemaChanged = true;
} else {
LOG.info("No Schema difference for " + tableName + "\nMessageType: " + schema);
}
}
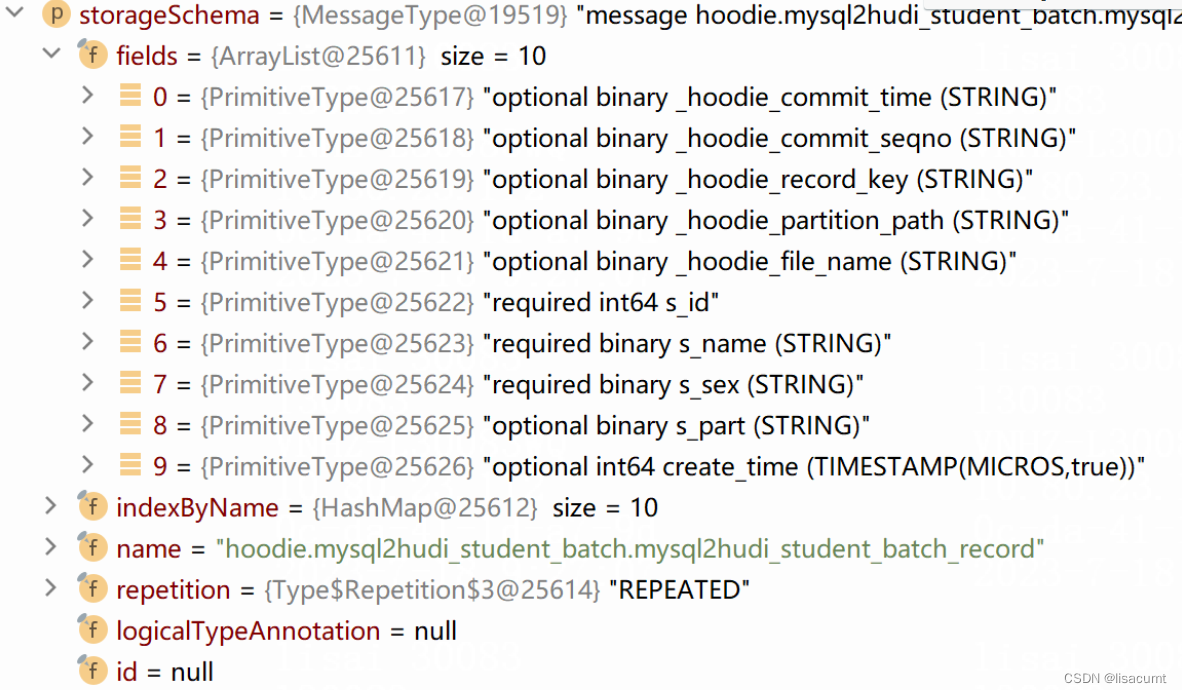
HoodieHiveSyncClient类
@Override
public void createTable(String tableName, MessageType storageSchema, String inputFormatClass,
String outputFormatClass, String serdeClass,
Map<String, String> serdeProperties, Map<String, String> tableProperties) {
ddlExecutor.createTable(tableName, storageSchema, inputFormatClass, outputFormatClass, serdeClass, serdeProperties, tableProperties);
}
HMSDDLExecutor类
创建表方法:
@Override
public void createTable(String tableName, MessageType storageSchema, String inputFormatClass, String outputFormatClass, String serdeClass, Map<String, String> serdeProperties,
Map<String, String> tableProperties) {
try {
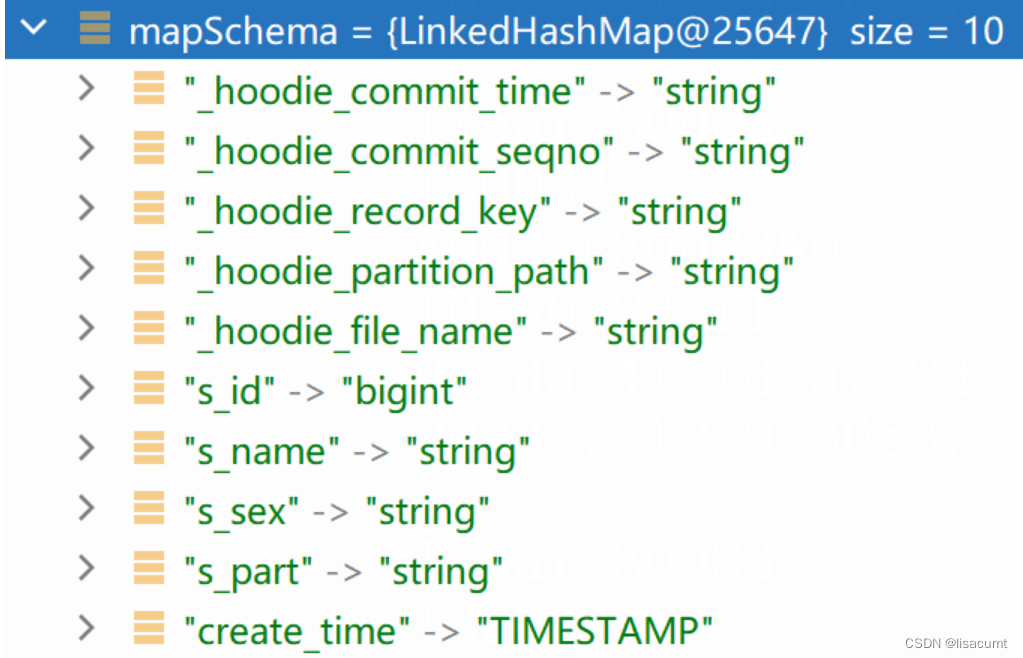
LinkedHashMap<String, String> mapSchema = HiveSchemaUtil.parquetSchemaToMapSchema(storageSchema, syncConfig.getBoolean(HIVE_SUPPORT_TIMESTAMP_TYPE), false);
List<FieldSchema> fieldSchema = HiveSchemaUtil.convertMapSchemaToHiveFieldSchema(mapSchema, syncConfig);
List<FieldSchema> partitionSchema = syncConfig.getSplitStrings(META_SYNC_PARTITION_FIELDS).stream().map(partitionKey -> {
String partitionKeyType = HiveSchemaUtil.getPartitionKeyType(mapSchema, partitionKey);
return new FieldSchema(partitionKey, partitionKeyType.toLowerCase(), "");
}).collect(Collectors.toList());
Table newTb = new Table();
newTb.setDbName(databaseName);
newTb.setTableName(tableName);
newTb.setOwner(UserGroupInformation.getCurrentUser().getShortUserName());
newTb.setCreateTime((int) System.currentTimeMillis());
StorageDescriptor storageDescriptor = new StorageDescriptor();
storageDescriptor.setCols(fieldSchema);
storageDescriptor.setInputFormat(inputFormatClass);
storageDescriptor.setOutputFormat(outputFormatClass);
storageDescriptor.setLocation(syncConfig.getString(META_SYNC_BASE_PATH));
serdeProperties.put("serialization.format", "1");
storageDescriptor.setSerdeInfo(new SerDeInfo(null, serdeClass, serdeProperties));
newTb.setSd(storageDescriptor);
newTb.setPartitionKeys(partitionSchema);
if (!syncConfig.getBoolean(HIVE_CREATE_MANAGED_TABLE)) {
newTb.putToParameters("EXTERNAL", "TRUE");
newTb.setTableType(TableType.EXTERNAL_TABLE.toString());
}
for (Map.Entry<String, String> entry : tableProperties.entrySet()) {
newTb.putToParameters(entry.getKey(), entry.getValue());
}
client.createTable(newTb);
} catch (Exception e) {
LOG.error("failed to create table " + tableName, e);
throw new HoodieHiveSyncException("failed to create table " + tableName, e);
}
}
HiveSchemaUtil类
包装方法,将Parquet的 MessageType转化为hive metastore的List<FieldSchema>
/**
* Returns equivalent Hive table Field schema read from a parquet file.
*
* @param messageType : Parquet Schema
* @return : Hive Table schema read from parquet file List[FieldSchema] without partitionField
*/
public static List<FieldSchema> convertParquetSchemaToHiveFieldSchema(MessageType messageType, HiveSyncConfig syncConfig) throws IOException {
return convertMapSchemaToHiveFieldSchema(parquetSchemaToMapSchema(messageType, syncConfig.getBoolean(HIVE_SUPPORT_TIMESTAMP_TYPE), false), syncConfig);
}
将Map类型转换为Hive 的FieldSchema类型
/**
* @param schema Intermediate schema in the form of Map<String,String>
* @param syncConfig
* @return List of FieldSchema objects derived from schema without the partition fields as the HMS api expects them as different arguments for alter table commands.
* @throws IOException
*/
public static List<FieldSchema> convertMapSchemaToHiveFieldSchema(LinkedHashMap<String, String> schema, HiveSyncConfig syncConfig) throws IOException {
return schema.keySet().stream()
.map(key -> new FieldSchema(key, schema.get(key).toLowerCase(), ""))
.filter(field -> !syncConfig.getSplitStrings(META_SYNC_PARTITION_FIELDS).contains(field.getName()))
.collect(Collectors.toList());
}
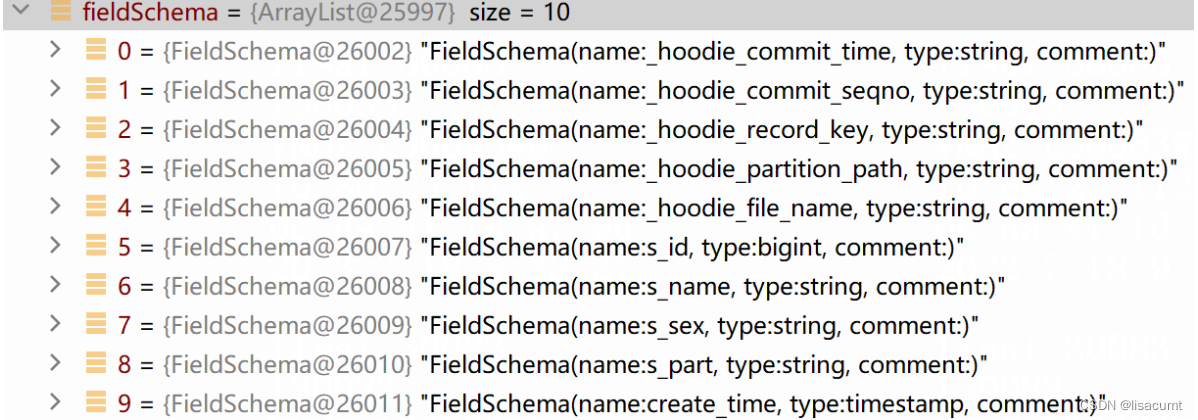
将parquet的类型转换为Map类型
/**
* Returns schema in Map<String,String> form read from a parquet file.
*
* @param messageType : parquet Schema
* @param supportTimestamp
* @param doFormat : This option controls whether schema will have spaces in the value part of the schema map. This is required because spaces in complex schema trips the HMS create table calls.
* This value will be false for HMS but true for QueryBasedDDLExecutors
* @return : Intermediate schema in the form of Map<String, String>
*/
public static LinkedHashMap<String, String> parquetSchemaToMapSchema(MessageType messageType, boolean supportTimestamp, boolean doFormat) throws IOException {
LinkedHashMap<String, String> schema = new LinkedHashMap<>();
List<Type> parquetFields = messageType.getFields();
for (Type parquetType : parquetFields) {
StringBuilder result = new StringBuilder();
String key = parquetType.getName();
if (parquetType.isRepetition(Type.Repetition.REPEATED)) {
result.append(createHiveArray(parquetType, "", supportTimestamp, doFormat));
} else {
result.append(convertField(parquetType, supportTimestamp, doFormat));
}
schema.put(key, result.toString());
}
return schema;
}

















 4235
4235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









