







 ResNet通过残差学习解决深度神经网络的退化问题,利用Shortcut Connection避免梯度消失,实现网络层数加深而准确率不降。文中介绍了残差块、Baseline网络结构以及实验结果。
ResNet通过残差学习解决深度神经网络的退化问题,利用Shortcut Connection避免梯度消失,实现网络层数加深而准确率不降。文中介绍了残差块、Baseline网络结构以及实验结果。
背景与问题
当前神经网络的训练存在两种问题:一是梯度爆炸和梯度消失,2二是随着网络深度的增加,准确率不会上升,并且可能会下降。下降并不是过拟合,而是因为层数的增多导致训练的准确率下降,训练的错误率本来就会很高。这就是深度网络的退化问题。下图演示了上述二所述的现象。
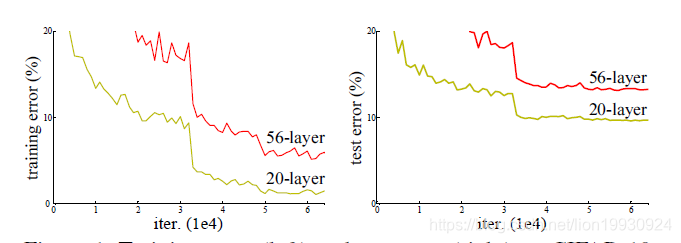
在如何解决这个问题上,作者考虑一个简单地事实,在浅层网络上增加深的层,这些层是浅层网络的恒等映射(identity mapping),什么都不学习,那这样深层网络应该不会出现退化的问题。但是这种方法经过试验是无法解决这个问题的。因此作者提出一种深度残差网络,使深层的网络去拟合浅层网络的残差映射(residual mapping),如下图所示,曲线表示恒等映射,直线表示残差映射。假设恒等映射是H(x)那么残差映射F(x)=H(x)-x.当残差为0时,残差映射可以转化为恒等映射。其中F(x)+x可以通过Shortcut Connection实现,什么是Shortcut Connection呢。这里我们先介绍一下HighWay Network.
-
HighWay NetWork
HighWay Network主要解决的问题是网络层数加深导致的梯度回流受阻的问题,可以看到下图,随着网络深度的增加训练误差也逐渐增加,而加入HighWay Network的网络训练误差得以缓解。HighWay Network灵感来自于LSTM结构,提出“门”的概念。
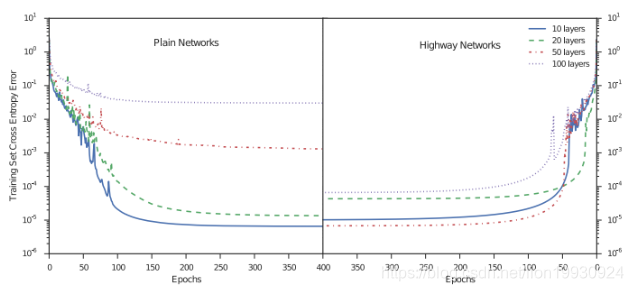
- 对于一个神经网络第L层的输出y是对输入做了一个非线性变化:y=H(x, Wx) - 定义门函数,T(x, Wx), 输出y=H(x,Wx)*T(x,Wx)+x(1-T(x,Wx)),对应的门函数使用sigmoid函数。这样可以保证在前向传播的时候将原始的信息带出一部分,避免后向传播的时候出现梯度消失等问题。 -
Shortcut Connection
Shortcut Connection的结构于HighWay Network结构类似,只不过他的结构是以两层神经元为一个单位,结构如下所示。当然这个残差结构可以跳过一层也可以跳过多层,这样可以有效解决梯度消失等问题,通过这样的残差结构连接可以组成一个深层的神经网络。同时相比于HighWay Network,Shortcut Connection并没有引入新的参数,并且HighWay Network有门关闭的风险,(门函数等于1)原始输入信息无法传递,而Shortcut Connection则没有这个问题。这是Shortcut Network相比于Highway Network的优势。
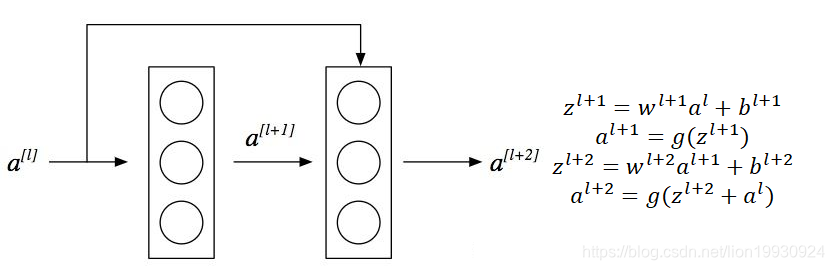
网络结构
残差学习
基于Shortcut Connection何大神提出残差学习,一般对于模块输入X,输出H(X)网络结构主要学习H(X),这样就容易引出梯度消失或梯度爆炸的问题,何大神另辟蹊径,提出残差学习,我们学习F(x)其中F(x) = H(x) - x,就是我们将输出认定是由输入的函数,我们不直接学习输出函数,我们学习输出函数和输入的差。一方面这个差保证梯度最小为1,不会出现梯度消失,细胞死亡的情况。另一方面这也降低的反向传到梯度的值,使网络结构对梯度的变化更加敏感。
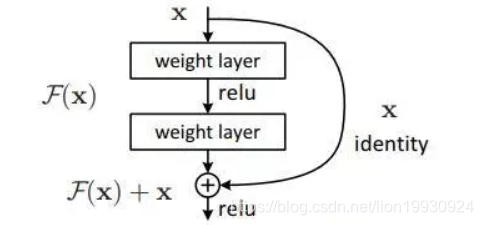
网络结构
- Baseline
文章的basline包含两种网络,VCG19层网络和基于VCG网络的34层网络。其中34层网络在设计中遵循了两个原则,一是feature map的大小相同时卷积核数量也相同,二是当feature map的大小降低为一般卷积核的数量变成之前的2倍。这是为了保证在每层的计算中时间消耗比较平均。
这里我们可以看一下torch官方实现的BasicBlock和BottleNeckBlock。我们目前学习的是残差,因此最后卷积的输出会加上输入。而且BottleNeck相比于Basic是多了1 [公式] 1的卷积,这点和GoogleNet思想相近,这里不做解释,大家可以在我的csdn blog进行了解:深度学习经典神经网络GoogLeNet阅读笔记
class BasicBlock(nn.Module):
expansion = 1
__constants__ = ['downsample']
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
__constants__ = ['downsample']
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
- 残差网络
实验的网络是基于34层VGG网络的残差网络,当输入层和输出层维度相同,残差块可以直接将输入和输出连接。当纬度不同时作者提出了两种解法,一种是直接padding为0,不引入参数。另外一种是对输入X进行11卷积将其映射成输出的维度,进行恒等映射。即H(X)=F(X)+WX这个会引入新的参数。而且从理论上讲,这已经不是恒等映射了。
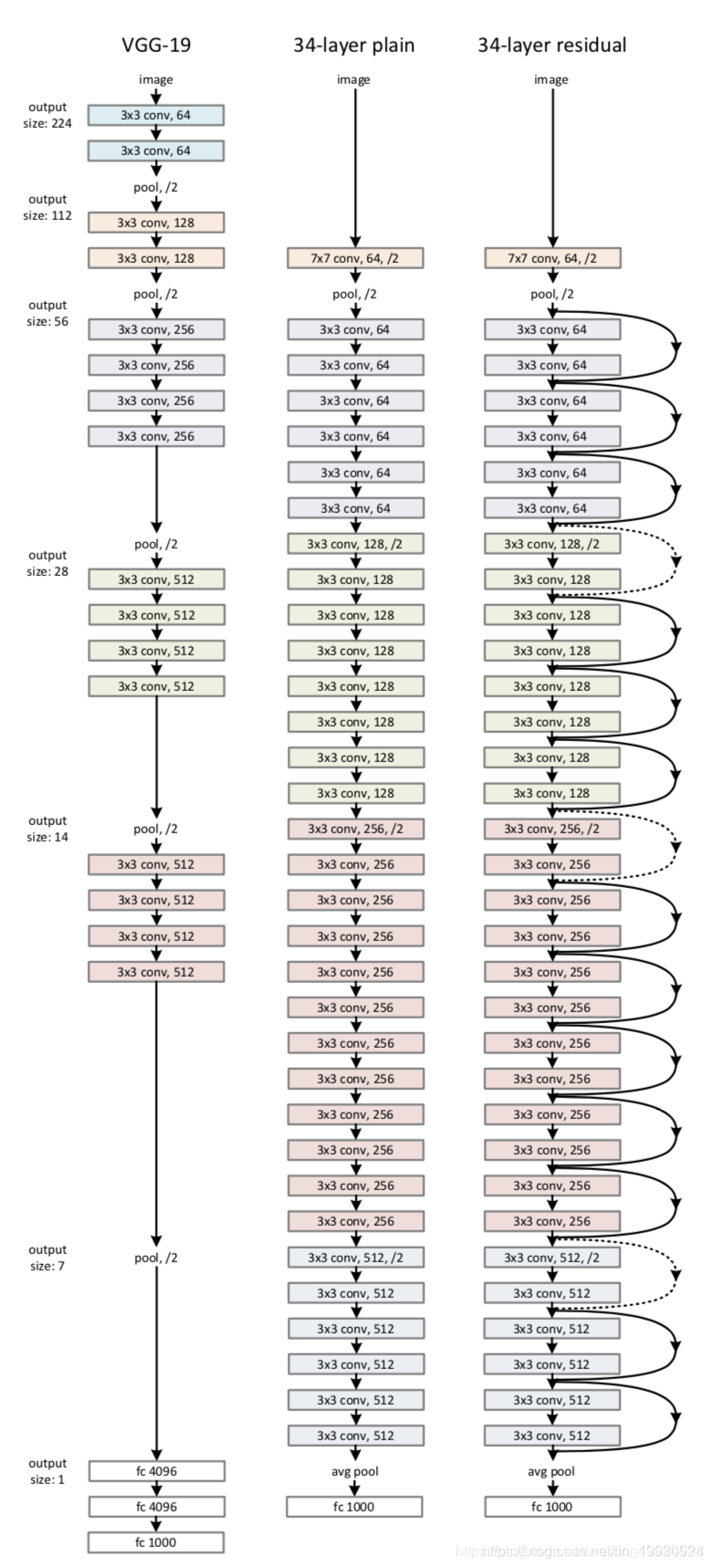
网络配置如下:
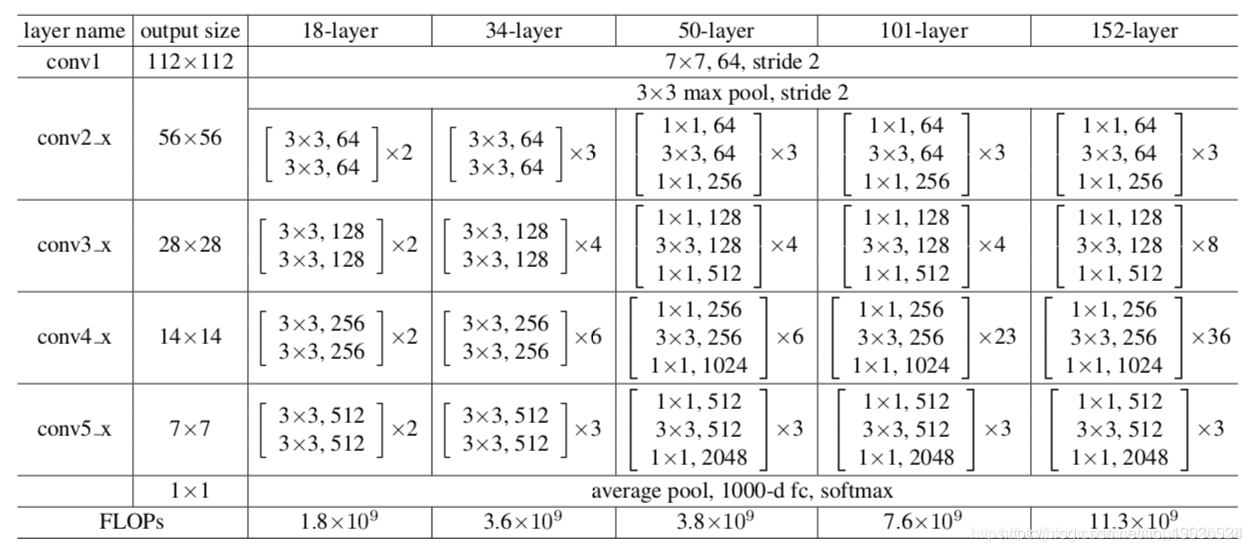
实验结果
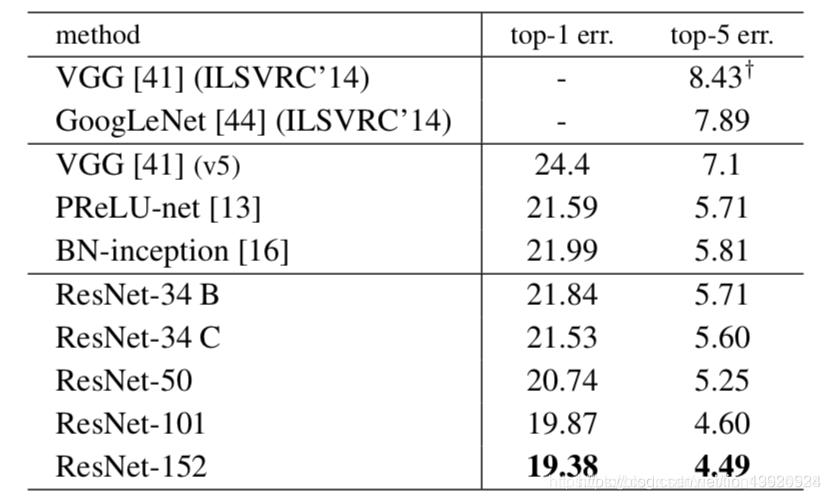
实验结果如下:
参考文档
- https://www.quora.com/What-are-shortcut-connections-how-do-they-work-and-what-is-their-role-in-the-paper-Deep-Residual-Learning-for-Image-Recognition
- https://zhuanlan.zhihu.com/p/36806579

















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









