







 本文探讨了链表(包括双向链表)和顺序表在存储空间、访问效率、插入删除操作及对缓存的影响。强调了顺序表的物理连续性提高缓存命中率,而链表则可能降低命中率并造成缓存污染。
本文探讨了链表(包括双向链表)和顺序表在存储空间、访问效率、插入删除操作及对缓存的影响。强调了顺序表的物理连续性提高缓存命中率,而链表则可能降低命中率并造成缓存污染。
| 不同点 | 顺序表 | 链表 |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1) | 不支持:O(N) |
| 任意位置插入或者删除 | 可能需要搬移元素,效率低O(N) | 只需修改指针指向 |
| 插入 | 动态顺序表,空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 任意位置插入和删除频繁 | 缓存利用率 |
| 缓存利用率 | 高 | 低 |
备注:缓存利用率参考存储体系结构 以及 局部原理性。
链表(双向)的优势:
- 任意位置插入删除都是O(1)
- 知道pos位置并且插入和删除,都是O(N) //后期学习哈希可以达到O(1)
- 按需求申请释放,合理利用空间,不存在浪费
链表(双向)劣势:
- 下标随机访问不方便O(N) //不支持高效排序
顺序表优势:
- 支持下标随机访问O(1)
- CPU高速缓存命中率比较高
顺序表劣势:
- 头部或者中间插入删除效率低,要挪动数据。O(N)
- 空间不够需要扩容,扩容有一定的消耗,且可能存在一定的空间浪费
- 只适合尾插尾删
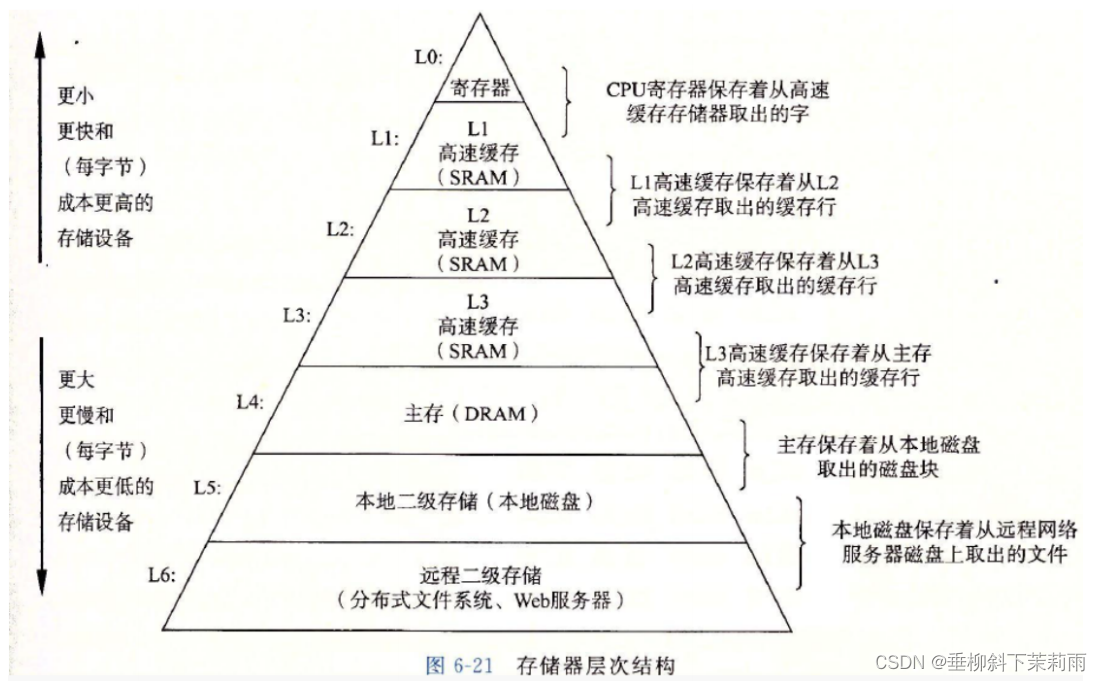
补充:关于硬件部分的知识
CPU高速缓存命中率比较高
电脑中负责运算就是 CPU 和 GPU(显卡等)。负责存储就是内存和硬盘(磁盘/固态)。
- 硬盘不带电永久存储,读写速度相对慢。(把画图板内容保存)
- 内存是带电暂时存储,但速度相对较快。(比如我们在画图板中编辑但尚未保存)
当然除了内存和硬盘这两个存储介质,还有;两个存储介质。
- 一个是三级缓存。虽然内存速度相较于硬盘快,但是对于CPU来说还是慢了,于是就有围绕在CPU附近的缓存。
- 还有一个就是寄存器了。寄存器比较小,但是速度是最快的!缓存中,缓存的存储数据越少,速度越快。
- 所以,小的数据会放到寄存器,大的数据会放到高速缓存中去。像顺序表/链表/数组这样的数据存储就是放到高速缓存中。
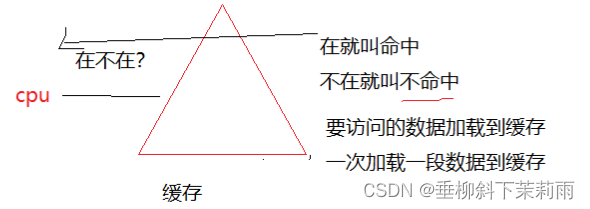
CPU怎样去访问缓存中的数据呢?
- 首先CPU会到高速缓存中去查看需要访问的数据是否在缓存中
- 如果在就命中
- 如果不在(没命中),就把数据 加载 高速缓存中(不是一个一个加载,而是一段一段的加载)
- 加载之后再去访问
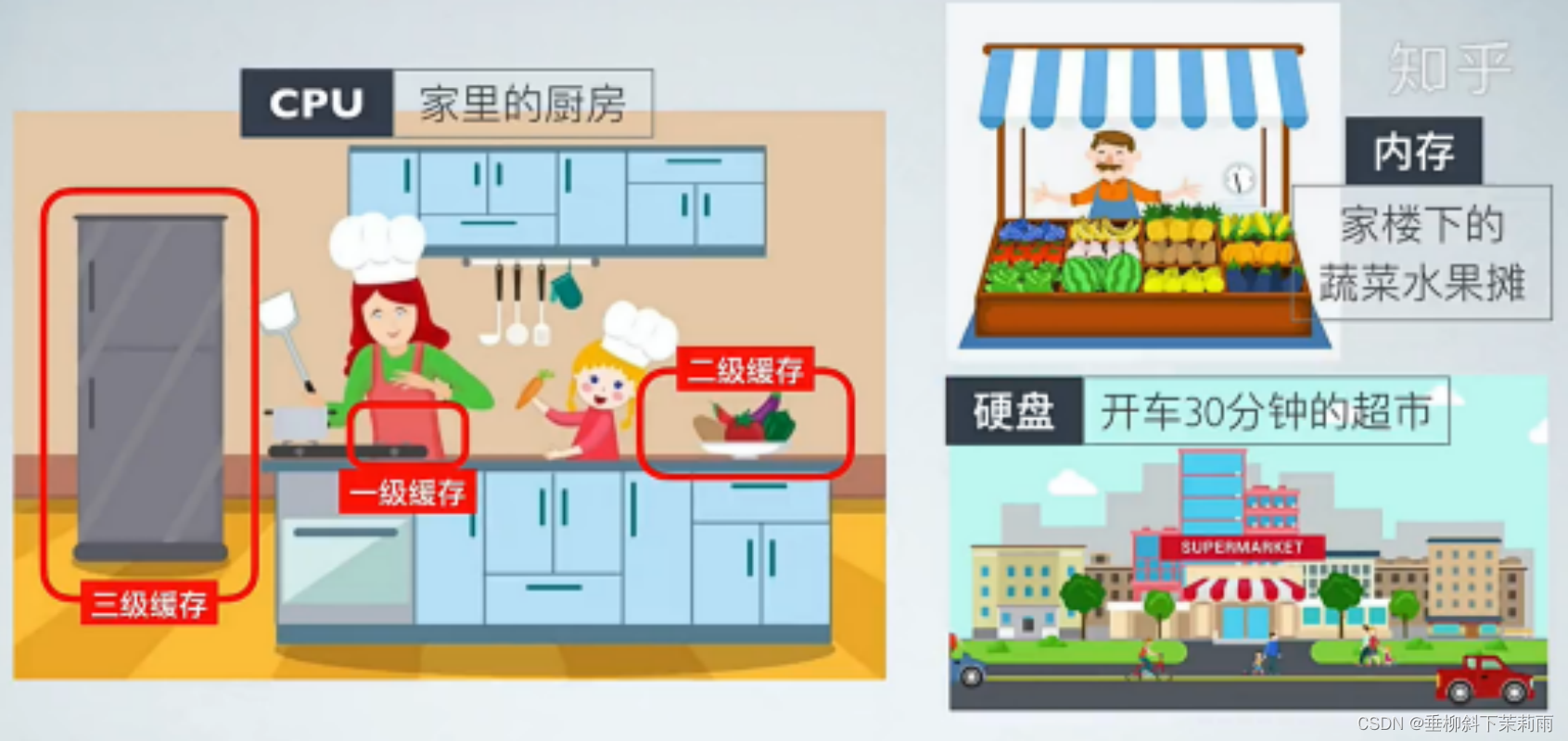
局部性原理
对于顺序表来说,物理结构上的连续,加载和访问时的命中率更高
对于链表来说,只是逻辑上的连续,物理空间可能相隔很远,所以命中率相对没有那么高,而且很容易造成缓存污染(空间存储的都是一些不必要的数据)
想要更进一步了解,可以看看这篇文章。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









