 SQLServer表分区优化实践
SQLServer表分区优化实践





 本文探讨了SQLServer中表分区技术的应用,包括如何选择分区字段、创建文件组和文件,以及实施表分区的具体步骤。通过案例分析,展示表分区如何显著提升查询效率。
本文探讨了SQLServer中表分区技术的应用,包括如何选择分区字段、创建文件组和文件,以及实施表分区的具体步骤。通过案例分析,展示表分区如何显著提升查询效率。
首先明确表分区和分库分表的概念。
- 表分区:在不破坏原本表结构的基础上,对单个大表进行切割,分成不同文件,存储在不用文件或硬盘。
- 分库分表:这里涉及到垂直切分及水平切分(引用网上的文章:https://www.cnblogs.com/zr520/p/5449748.html)。
垂直切分:垂直拆分就是要把表按模块划分到不同数据库表中(当然原则还是不破坏第三范式),这种拆分在大型网站的演变过程中是很常见的。当一个网站还在很小的时候,只有小量的人来开发和维护,各模块和表都在一起,当网站不断丰富和壮大的时候,也会变成多个子系统来支撑,这时就有按模块和功能把表划分出来的需求。其实,相对于垂直切分更进一步的是服务化改造,说得简单就是要把原来强耦合的系统拆分成多个弱耦合的服务,通过服务间的调用来满足业务需求看,因此表拆出来后要通过服务的形式暴露出去,而不是直接调用不同模块的表,淘宝在架构不断演变过程,最重要的一环就是服务化改造,把用户、交易、店铺、宝贝这些核心的概念抽取成独立的服务,也非常有利于进行局部的优化和治理,保障核心模块的稳定性。
水平切分:上面谈到垂直切分只是把表按模块划分到不同数据库,但没有解决单表大数据量的问题,而水平切分就是要把一个表按照某种规则把数据划分到不同表或数据库里。例如像计费系统,通过按时间来划分表就比较合适,因为系统都是处理某一时间段的数据。而像SaaS应用,通过按用户维度来划分数据比较合适,因为用户与用户之间的隔离的,一般不存在处理多个用户数据的情况,简单的按user_id范围来水平切分
这里我们指讨论表分区。
1.首先明确系统中对此表的查询情况
如果系统比较复杂可以借助“SQL Server Profiler”对生产环境进行抓取。并分析此表的查询情况,比如:如果是行业类型的新闻,可能以行业来查询的情况比较多,笔者之前维护过一个系统,属于行业资讯类,单表大概几百万,对行业ID建立索引后,列表页查询(Row_number)大概在200ms左右。利用行业ID进行表分区后,稳定表现在50ms左右。因为sqlserver优化器会根据表分区的函数定位到该分区,不对其他分区进行查询,所以提高比较明显。总的来说就是先判断要以哪个字段作为分区依据。
如果存在多个可进行分区的字段,那么如果他们之间是有关联的,比如:类别1,类别1的2级类别,类别1的3级类别,但是又是有互相关系的,可以对基础字段进行分区,及类别1。如果需要查询“类别1的2级类别”,可以把类别1加上,这样依然会定位对应的分区从而提高速度。
2.创建文件组
- 一种利用sqlserver的管理器进行创建:
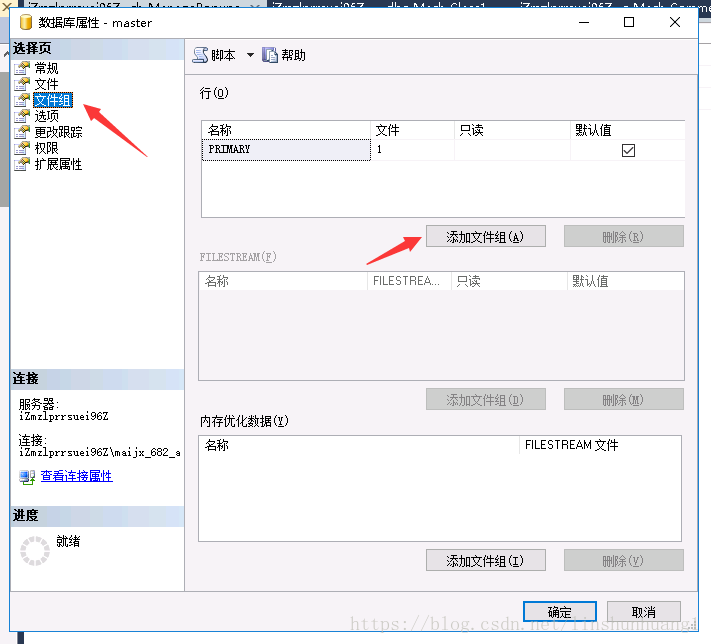
- 利用命令进行创建,
alter database <数据库名> add filegroup <文件组名>如果打算分10区就得添加10个文件组。
3.创建文件(真实的文件名)
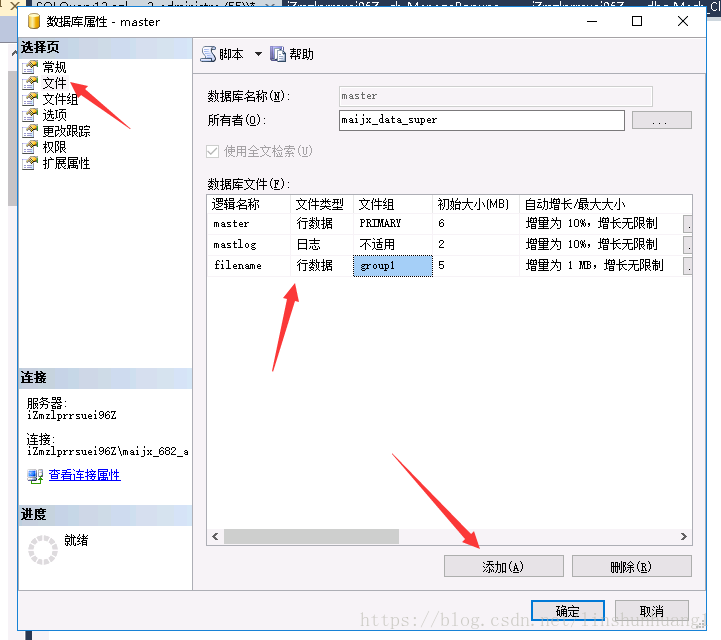
或
alter database <数据库名称> add file <数据标识> to filegroup <文件组名称>
--<数据标识> (name:文件名,fliename:物理路径文件名,size:文件初始大小kb/mb/gb/tb,filegrowth:文件自动增量kb/mb/gb/tb/%,maxsize:文件可以增加到的最大大小kb/mb/gb/tb/unlimited)4.创建表分区
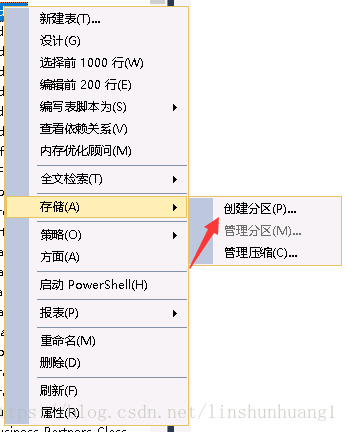
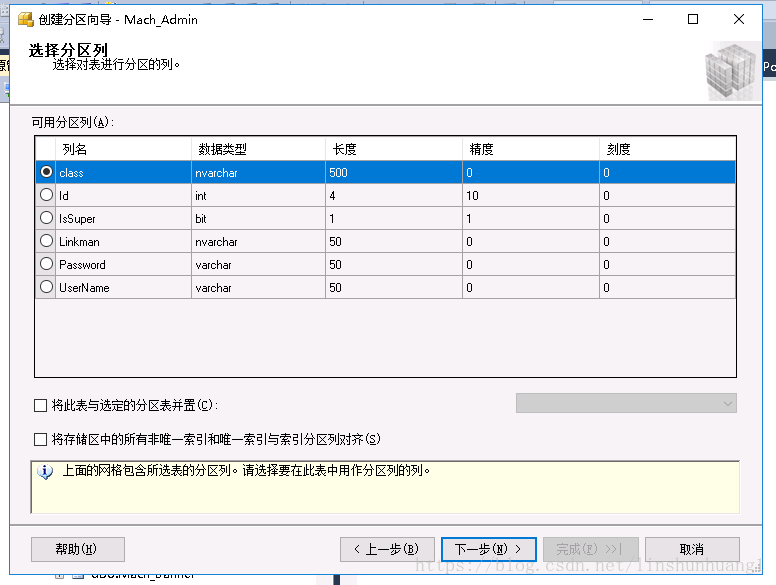
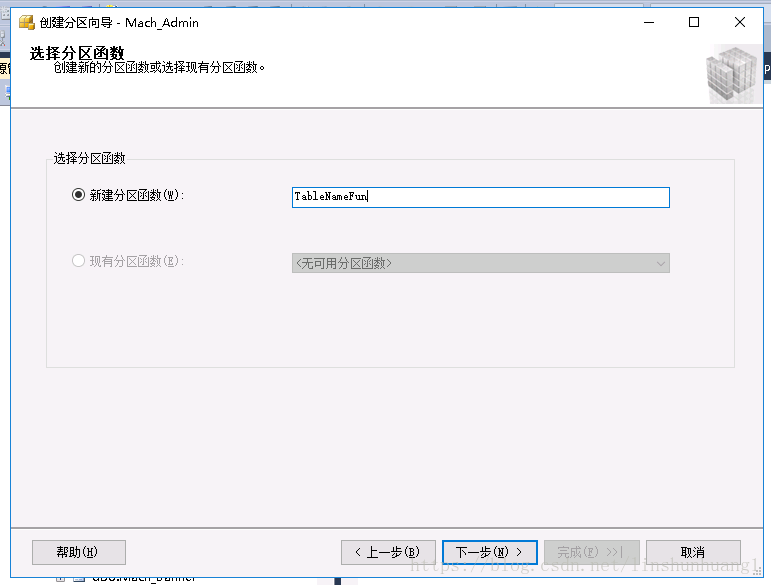
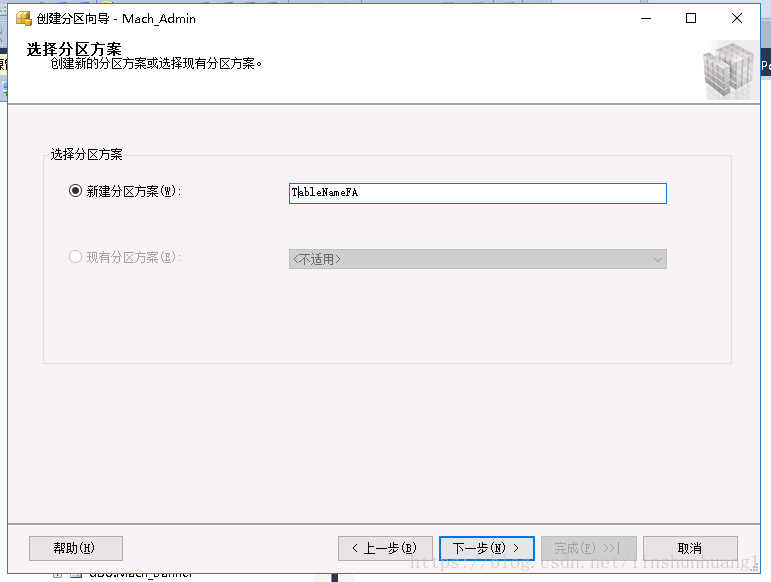
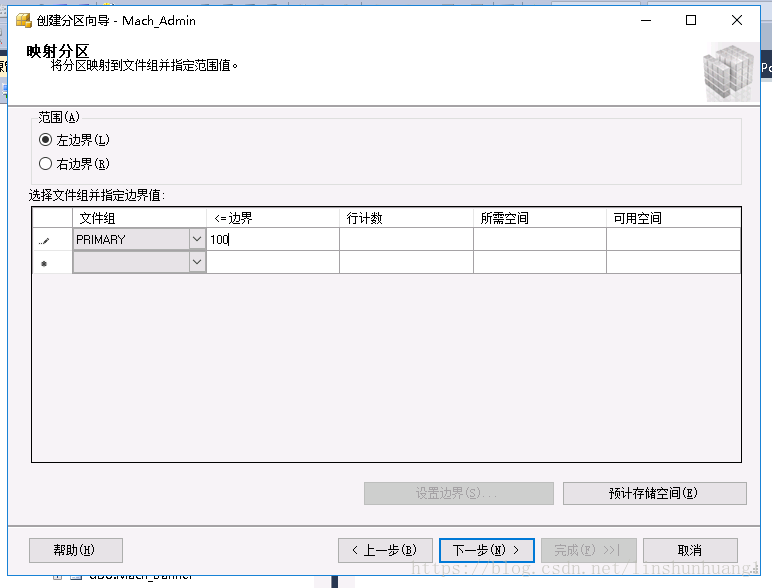
在这里设置分区的项目,PRIMARY则是默认的DB文件。一般先存储到分区,最后剩下的数据存储在PRIMARY。完成后生成脚本。


















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









