




3.1 hdfs的设计
超大文件:几百M 到几百T ,甚至是T的数据
流式数据访问: 一次写入,多次读取,每次读取都是全量的数据
商用硬件:允许机器硬件故障
低时间延迟: 不适合,可以考虑HBase
大量小文件:不好,由于元数据保存在内存中,每个文件/目录/数据块 在内存中大约占150字节。
如果有一百W个小文件,每个文件一个数据块,那么就要 100,0000*2*150 B= 300*1000*1000B=300MB
不支持修改和多用户插入:
3.2 hdfs的概念
3.2.1 数据块
默认是128M,如果文件只有5M,那这个块也只有5M。
为什么是128M:
1 之所以比较大,是因为要减小寻址空间
2 之所以只有128M,是因为map函数一次只处理一个块的数据,如果太大了,分布得主机太少,计算速度慢
为什么要分块:
1 文件大小可以很大,可以大过磁盘的大小,比如我一个文件1Tb,但是我的每个磁盘500G,可以分块来存
2 方便管理,块是固定大小的,可以很容易计算还可以存储多少块。同时取消元数据的顾忌,块只管存储整个信息,但是元数据其他信息如权限等,不需要和数据一起存储了
3 提高系统容错能力,可以很容易得进行副本管理,默认设置为3个副本
3.2.2 namenode和datanode
namenode:
保存: 1 命名空间镜像文件 2 编辑日志 3 块的存储位置 (不存硬盘,有dn上报)
客户端,client:
用户和nn,dn交互的接口
datanode:
存块,计算,定期向nn发送位置信息
nameNode的容错机制:
1 通过配置,使得nn在多个文件系统中保存元数据的持久状态,这些操作是同步的,原子性的。一般的配置是,将持久状态写入本地磁盘的同时,写入一个远程挂载的网络文件系统(NFS)
2 通过secondryNameNode
3.2.3 块缓存
通常是从磁盘中读取块信息,如果块频繁被访问,就有可能被缓存在某个datanode的内存中,这样可以提高读取效率
可以通过缓存池来告诉nn缓存哪些文件和多久
3.2.4 联邦HDFS
namenode的内存成为了集群的瓶颈之后,联邦HDFS可以添加nn来实现扩展。
例如: nn1管理 /user 下的文件, nn2管理 /share下的文件
datanode是共享的,但是nn之间互不通信,即使一个挂了,也不影响另外一个
3.2.5 hdfs的高可用
如果没有高可用,假如要NN工作,需要:
1 将 镜像导入到内存
2 重演editLog
3 接受dn的数据报告
对于一个大集群来说,这要花费非常多的时间。
hadoop2对这个问题提供了HA,主挂了之后,备会立即接管他的工作,系统不会有明显中断。架构修改:
1 nn之间需要高可用共享存储来实现编辑日志的共享。当主nn挂掉,备机会通读日志,实现同步
2 dn需要向2个nn都发送数据,因为这些数据存在内存中
3 客户端使用某机制来处理nn切换,这个过程对用户透明
4 备用nn取代 seconderyNN, 备用nn为主nn周期性得设置检查点
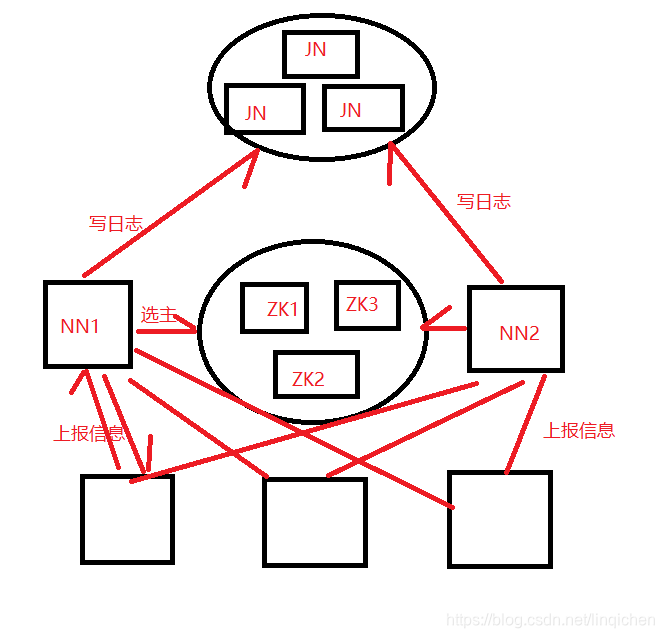
切换了之后,为了防止之前的nn去操作 jn,要把原来的nn彻底搞死
1 撤销nn的访问权限
2 屏蔽接口
3 一枪爆头,直接通过某个模块,把他断电
3.3 命令行接口
注意2个hdfs的属性:
fs.defaultFS: 用于设置hadoop的默认文件系统,设置为: hdfs://localhost/
dfs.replication: 副本数
文件系统的操作:
hadoop fs -help 帮助
hadoop fs -copyFromLocal 从本地文件系统复制到hdfs
hadoop fs -mkdir 创建目录
hadoop fs -ls 展示目录
权限:
hdfs的权限与POSIX的权限模式相似:
一共有3类权限: 只读 r ,写入 w , 执行 x 。 其中x 可以忽略,因为不能在hdfs中执行文件,但是在访问一个目录的子项时需要该权限。
每个文件和目录都有 所属用户,所属组别及模式。 模式是由 所属用户/组/其他成员 的权限组成。
默认是这个权限体系是停用的,启用 dfs.permissions.enabled.
超级用户,namenode的进程是超级用户,不会执行任何的权限检查
3.4 hadoop文件系统
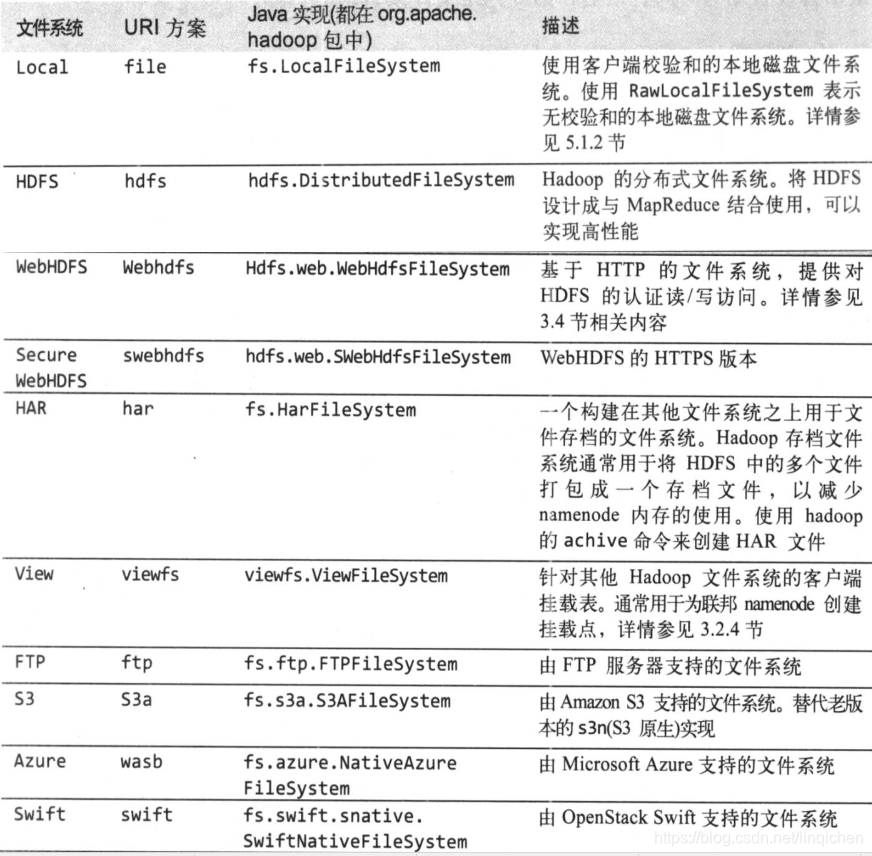
以上都是实现了hadoop的 抽象文件系统的 实现类。
mapReduce程序可以访问任何的文件系统,但是建议还是选择一个由数据本地化的分布式文件系统。如hdfs
接口:
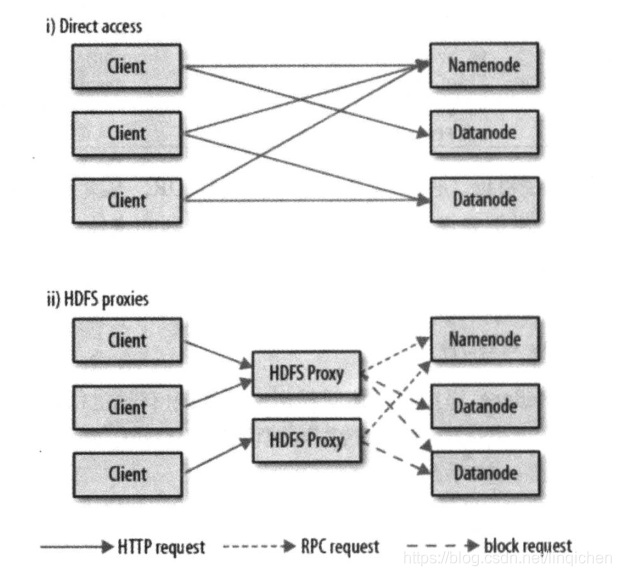
1 http
提供了http rest api来访问hdfs但是http接口要比原生的java客户端要慢,所以尽量不用。通过http来访问hdfs的方法有两种:直接访问,间接访问(代理访问)。
直接访问:nn和dn会内嵌web服务器,dfs.webhdfs.enabled被设置成true(默认),文件读写先发送到nn, nn发送一个http重定向到某客户端,指示以流的方式传输文件的目的或者源 dn.
间接访问: 依靠一个或者多个代理服务器通过http访问hdfs。所有集群的网络通信都需要经过代理,使用代理服务器,可以使用严格的防火墙策略和带宽策略。实现不同数据中心部署的hadoop集群之间的数据传输,或者从外部网络访问云端运行的hadoop集群。
2 c语言接口
提供hdfs的c语言接口,和java的接口类似,但是开发滞后于java,不建议使用
NFS挂载
可以使用hadoop的NFSv3网关将Hdfs挂载为本地客户端的文件系统。用户可以直接使用unix的操作命令来使用hdfs,只可以在末尾添加数据,不能随意修改数据
Fuse-dfs :
和nfs类似,但是是C语言开发的,基于上面所说的c语言接口,建议使用NFS来搞
3.5 java接口
会深入探讨 FileSystem类,它是与hadoop文件系统交互的api
hadoop2以后,添加了一个叫FileContent的文件系统接口,此接口可以很好得处理多文件问题。但是FileSystem仍然广泛使用
3.5.1 从Hadoop的url中读取数据
要想获取Hdfs的数据,最简单的方法就是使用 java.net.URL来读取。


3.5.2 通过FileSystem API来读取数据
hadoop通过Path对象来代表文件(而不是java.io.File)
获取FileSystem有以下的几个静态工厂方法:


FSDataInputStream对象:
实际上 FileSystem的open返回的方法不是java.io的对象,而是FSDataInputStream对象。
支持随机访问,可以从流的任意位置来读取数据。
seek()可以移到文件的任意一个绝对的位置,但是是一个高开销的方法,建议少用。
3.5.3 写入数据
FileSystem类有很多新建文件的方法。

Progressable

append:


FSDataOutPutStream
有个获取查询文件当前位置的方法: getPos()。
但是和FSDataInputStream不同,他不允许在文件中定位。只允许对一个已打开的文件进行写入,或者在现有文件中追加。换句话说,它不支持在文件末尾之外的地方写入。所以上面的定位方法没啥用。
3.5.4 目录
mkdirs(Path p).
调用create()来创建文件时,会自动创建目录
3.5.5 查询文件系统
1 文件元数据 FileStatus
FileSystem的 getFilestatus()可以获取到 FileStatus对象,里面有:
文件长度 块大小 副本 修改时间 所有者 权限信息等
2 列出文件
listStatus() ,可以返回 FileStatus[] 数组
3 文件模式
globStatus()方法返回 FileStatus[] 数组,还可以使用 PathFilter来对结果进行过滤


3.5.6 删除数据
delete()
3.6 数据流
3.6.1 剖析文件读取
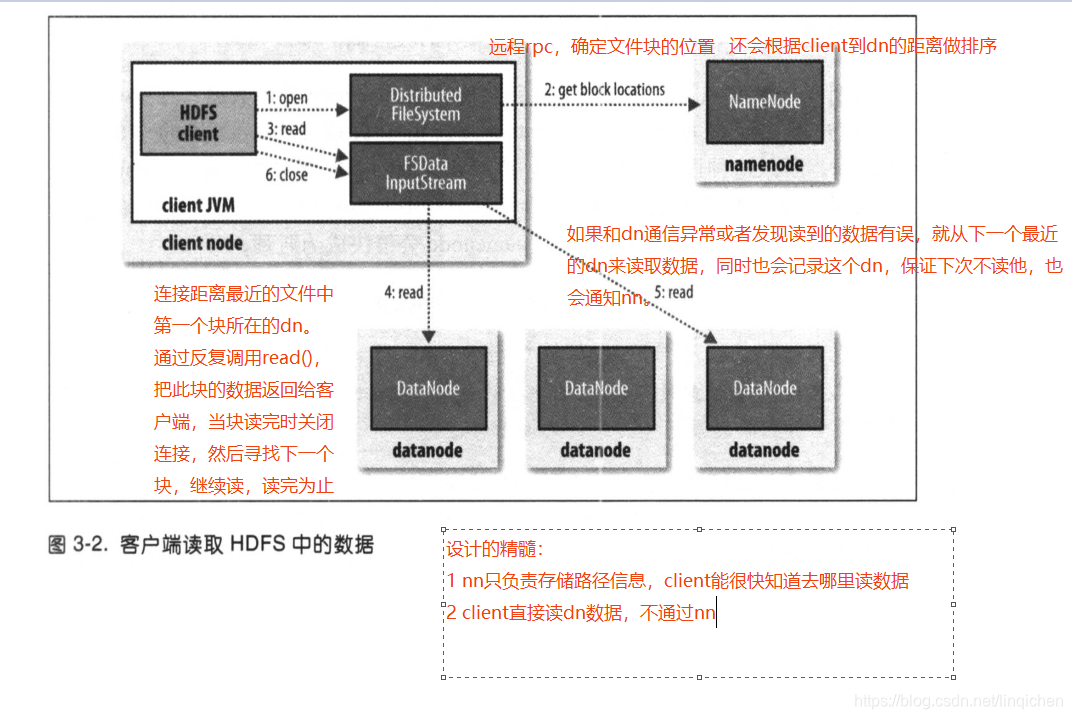
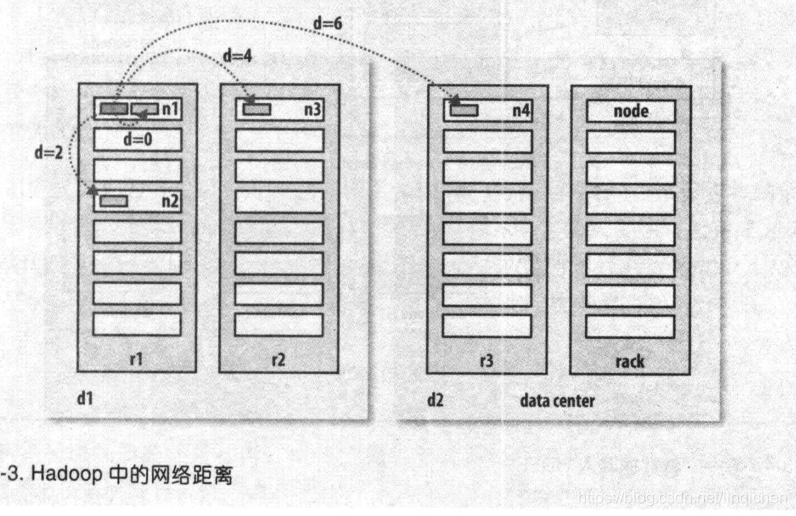
其中讲到数据距离的概念:
同一节点 < 同一机架 < 同一数据中心不同机房 < 不同数据中心
目前hadoop 不支持 不同数据中心的运行。
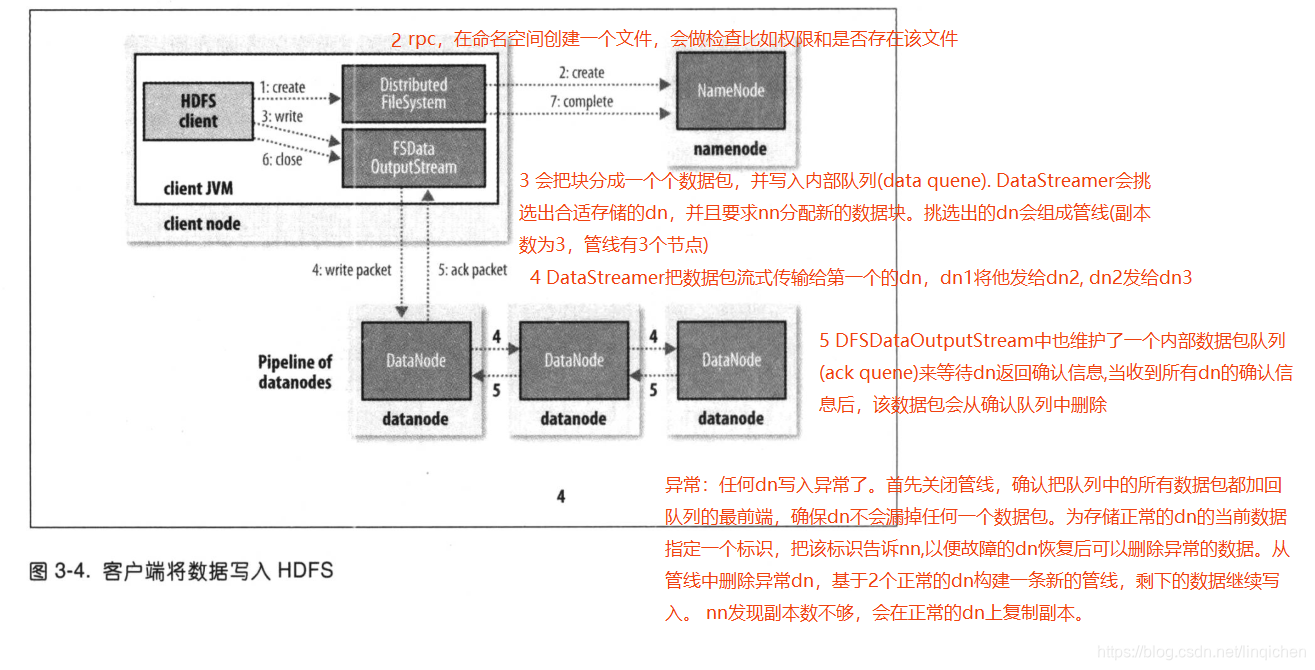
3.6.2 剖析文件写入
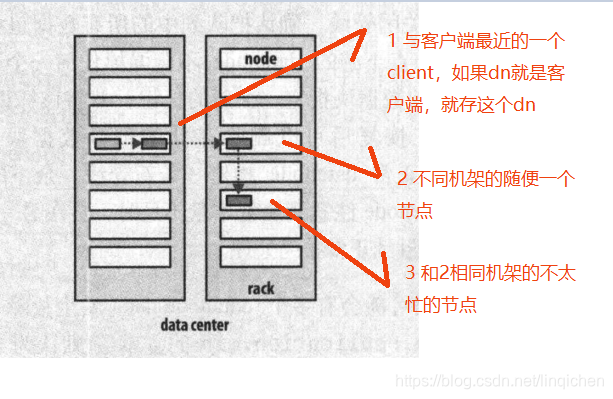
副本存放策略:
3.6.3 一致性模型
文件系统的一致性模型描述了文件读写的一致性。 hdfs为了性能,牺牲了一些POSIX需求,因此一些操作与你期待不同。
1 新建目录,其他用户立即可见
2 新建文件,对其他用户不立即可见,只有写入超过一个块之后才对其他用户可见
hadoop提供强行将缓存刷到datanode中的方法:hflush() hsync();
其中 hflush会先刷到dn的内存中,所以,当断电时,数据会丢失。
hsync()是直接写到本地文件系统中,不过开销更大
对应用系统的重要性:
如果不使用 hflush和hsync,就可能系统故障时丢失数据,所以要适当得调用,在数据鲁棒性和吞吐量之间要做取舍,通过调整调用频率来达到好的效果。
3.7 通过distcp并行复制
hadoop自带一个程序distcp, 可以并行从hdfs中复制数据,也可以将大量数据复制到hdfs中。
distcp是用mapReduce来实现的,但是里面只有map没有reduce。 用每个Map来执行复制任务,默认是20个,但是可以用-m来指定map的个数

保持hadoop集群的均衡
用distcp来复制,如果只用1个map,就是不考虑性能,那么第一个副本就在Map 的节点上,第二和第三个分布在其他节点。但是这个节点就不均衡了,如果map设置为大于集群的节点数,就不会有这个问题。
结论是:使用distcp最好使用默认的20个map.
但是还是不能阻止集群的不均衡,所以后面的11.1.4会专门讨论均衡器

















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









