




 Azkaban是LinkedIn为解决Hadoop作业依赖问题而开发的工具,包括MySQL数据库、AzkabanWebServer和AzkabanExecutorServer三部分。AzkabanWebServer负责项目管理、调度和监控,AzkabanExecutorServer执行工作流和作业。文章介绍了不同部署模式,包括适合初学者的Solo Server,以及适用于生产环境的双服务器和多执行器模式。
Azkaban是LinkedIn为解决Hadoop作业依赖问题而开发的工具,包括MySQL数据库、AzkabanWebServer和AzkabanExecutorServer三部分。AzkabanWebServer负责项目管理、调度和监控,AzkabanExecutorServer执行工作流和作业。文章介绍了不同部署模式,包括适合初学者的Solo Server,以及适用于生产环境的双服务器和多执行器模式。
Azkaban是在LinkedIn上实现的,用来解决Hadoop作业依赖的问题。我们的工作需要按顺序运行,从ETL工作到数据分析产品。
Azkaban最初是一个单一的服务器解决方案,随着多年来Hadoop用户数量的增加,它已经发展成为一个更健壮的解决方案。
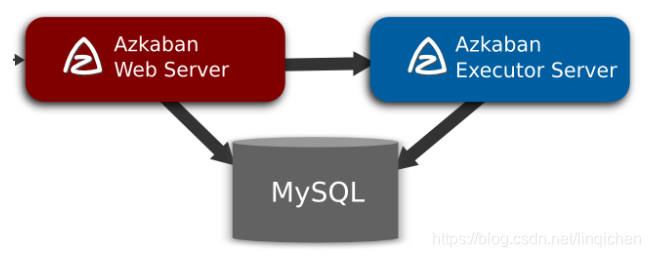
Azkaban由三个关键部分组成:
- 关系型数据库(MySQL)
- AzkabanWebServer
- AzkabanExecutorServer
Relational Database (MySQL)
Azkaban使用MySQL来存储它的大部分状态。AzkabanWebServer和AzkabanExecutorServer都访问数据库。
AzkabanWebServer 是如何访问数据库的?
web服务器使用数据库的原因如下:
- 项目管理——项目、项目权限、上传文件。
- 执行工作流状态——跟踪执行工作流以及哪个执行器正在运行它们。
- 以前的工作流/作业——搜索以前执行的作业和工作流,并访问它们的日志文件。
- 调度程序——保持调度作业的状态。
- SLA——保持所有SLA规则
AzkabanExecutorServer 用数据库来干啥?
- 访问项目——从数据库中检索项目文件。
- 执行工作流/作业——检索和更新正在执行的工作流的数据
- 日志——将作业和工作流的输出日志存储到数据库中。
- 互流依赖——如果一个工作流在不同的执行程序上运行,它将从数据库获取状态。
选择MySQL的原因是它是一个广泛使用的数据库。我们希望实现与其他数据库的兼容性,尽管在历史上运行作业的搜索需求受益于关系数据存储。
AzkabanWebServer
AzkabanWebServer是阿兹卡班的主要管理器。它处理项目管理、身份验证、调度器和执行监视。它还充当web用户界面。
使用Azkaban很容易,Azkaban使用*.job键值属性文件定义工作流中的各个任务,_dependencies_属性定义作业的依赖链。这些作业文件和相关代码可以归档到一个*.zip文件中,并通过Azkaban UI或curl通过web服务器上传。
AzkabanExecutorServer
以前的Azkaban版本同时具有Azkab
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5580
5580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









