




 本文介绍了一种使用Scrapy框架爬取京东商城特定产品信息的方法,包括安装配置、项目创建、代码实现及数据导出至Excel的过程。通过XPath解析产品名称和价格,展示了爬虫从数据获取到存储的完整流程。
本文介绍了一种使用Scrapy框架爬取京东商城特定产品信息的方法,包括安装配置、项目创建、代码实现及数据导出至Excel的过程。通过XPath解析产品名称和价格,展示了爬虫从数据获取到存储的完整流程。
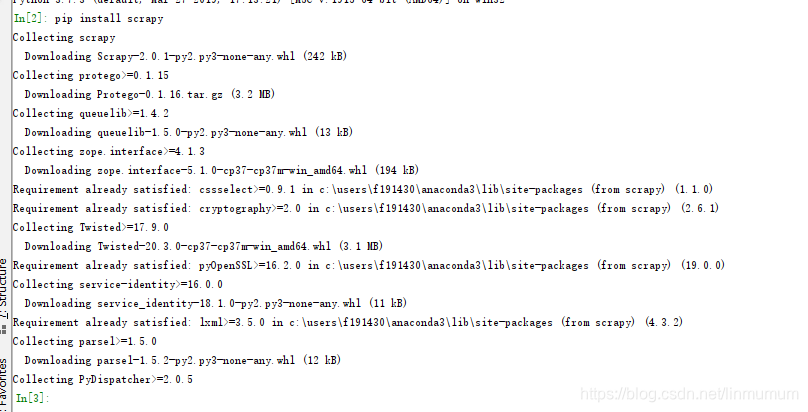
1.安装:pip install scrapy
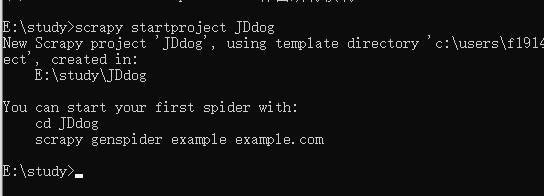
2.创建项目:scrapy startproject JDdog
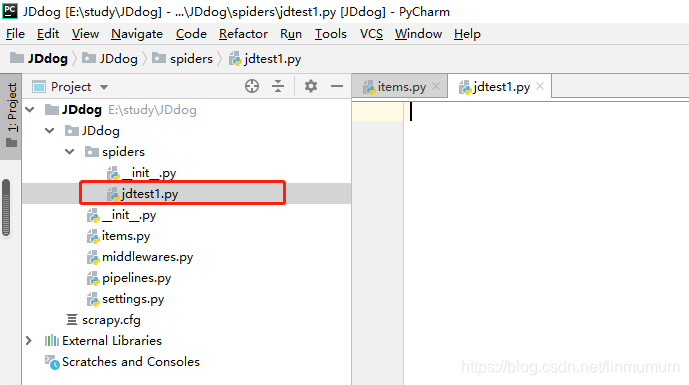
3.创建文件:
4.附上一部分代码
#coding=utf-8
import scrapy, os, json, time
from openpyxl import Workbook
import xlsxwriter
cwd = os.getcwd()#获得当前目录
name = "jdtest" # 定义蜘蛛名
Screentime = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time()))
def save_excel_row_data(_list, address, filename):
wb = xlsxwriter.Workbook(address)
ws = wb.add_worksheet(filename)
j = 0
for i in _list:
ws.write(j, 0, i)
j = j+1
# ws.append(_list)
wb.close()
#将list数据按列写入excel
def save_excel_data(_list, address, filename):
wb = Workbook()
ws = wb.create_sheet(filename)
ws.append(_list)
wb.save(address)
class JDdog(scrapy.Spider): # 需要继承scrapy.Spider类
name = "jdtest" # 定义蜘蛛名
def start_requests(self): # 由此方法通过下面链接爬取页面
# 定义爬取的链接
urls = [
'https://search.jd.com/Search?keyword=%E5%8D%8E%E4%B8%BAmate30',
# 'https://try.jd.com/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse) # 爬取到的页面如何处理?提交给parse方法处理
# def parse(self, response):
# '''
# start_requests已经爬取到页面,那如何提取我们想要的内容呢?那就可以在这个方法里面定义。
# 这里的话,并木有定义,只是简单的把页面做了一个保存,并没有涉及提取我们想要的数据,后面会慢慢说到
# 也就是用xpath、正则、或是css进行相应提取,这个例子就是让你看看scrapy运行的流程:
# 1、定义链接;
# 2、通过链接爬取(下载)页面;
# 3、定义规则,然后提取数据;
# 就是这么个流程,似不似很简单呀?
# '''
# page = response.url.split("/")[-2] # 根据上面的链接提取分页,如:/page/1/,提取到的就是:1
# filename = 'mingyan-%s.html' % page # 拼接文件名,如果是第一页,最终文件名便是:mingyan-1.html
# with open(filename, 'wb') as f: # python文件操作,不多说了;
# f.write(response.body) # 刚才下载的页面去哪里了?response.body就代表了刚才下载的页面!
# self.log('保存文件: %s' % filename) # 打个日志
# 将list数据按列写入excel
def parse(self, response):
_nlist = []
_plist = []
selector = scrapy.Selector(response)
n_s_list = selector.xpath("//div[@class ='p-name p-name-type-2']")
n_list = selector.xpath("//div[@class ='p-name p-name-type-2']/a/em")
for i in n_list:
second_name = n_s_list.xpath("//a/em/font[1][@class ='skcolor_ljg']")
for name2 in second_name:
name2 = name2.xpath('./text()')
name2 = name2.extract()[-1]
n_list = i.xpath('./text()')
n_list = n_list.extract()
_name = str(n_list[0])+str(name2)+str(n_list[-1])
p_list = selector.xpath("//div[@class ='p-price']/strong/i")
for sel in p_list:
p_list = sel.xpath('./text()')
p_list = p_list.extract_first()
_plist.append(p_list)
_nlist.append(_name)
##css写法
# _pricelist = response.css('div.p-price')
# _list = []
# for var in _pricelist:
# price = var.css('i')
# price = str(price)
# price = price.replace("[<Selector xpath='descendant-or-self::i' data='<i>", "")
# price = price.replace("</i>'>]", "")
fileName = '华为mate30价格.txt' # 定义文件名,
address = cwd + '\\京东商城华为mate30价格'+Screentime+'.xlsx'
print(address)
wb = xlsxwriter.Workbook(address)
ws = wb.add_worksheet(fileName)
j = 0
for i in _nlist:
ws.write(j, 0, i)
j = j + 1
row = 0
for i in _plist:
ws.write(row, 1, i)
row = row + 1
# ws.append(_list)
wb.close()
if __name__ == "__main__":
import os
command1 = 'cd' + ' ' + str(cwd)
command2 = 'cd e:'
command3 = 'scrapy crawl ' + name
os.system(command1)
os.system(command2)
os.system(command3)
# if __name__ == "__main__":
# #scrapy调试工具的使用
# import os
# cwd = os.getcwd() # 获得当前目录
# command1 = 'scrapy shell https://search.jd.com/Search?keyword=%E5%8D%8E%E4%B8%BAmate30'
# os.system(command1)
#response.css('title') 在调试框输入,检查是否展示<title>京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物...
#response.css('title').extract()
#response.css('title::text').extract_first()我们在title后面加上了 ::text ,这代表提取标签里面的数据,至此,我们已经成功提取到了我们需要的数据:


















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











