




 本文介绍了一种使用Python pandas库批量合并多个Excel文件中相同格式Sheet的方法,通过读取指定文件夹下所有.xlsx文件,将各公司数据整合到单一Excel表中,每张Sheet对应合并,有效提高财务报表处理效率。
本文介绍了一种使用Python pandas库批量合并多个Excel文件中相同格式Sheet的方法,通过读取指定文件夹下所有.xlsx文件,将各公司数据整合到单一Excel表中,每张Sheet对应合并,有效提高财务报表处理效率。
小姐妹提的需求
每家公司都有一个表,表的格式相同(每个表的工作簿sheet名,每个sheet的格式都相同),要把所有公司的数据合到一张表里,每个sheet对应合并。用网上的方法经常出问题,一直没有一劳永逸的方法,还是手动一张一张粘贴。每个月都有20+张表要合并。
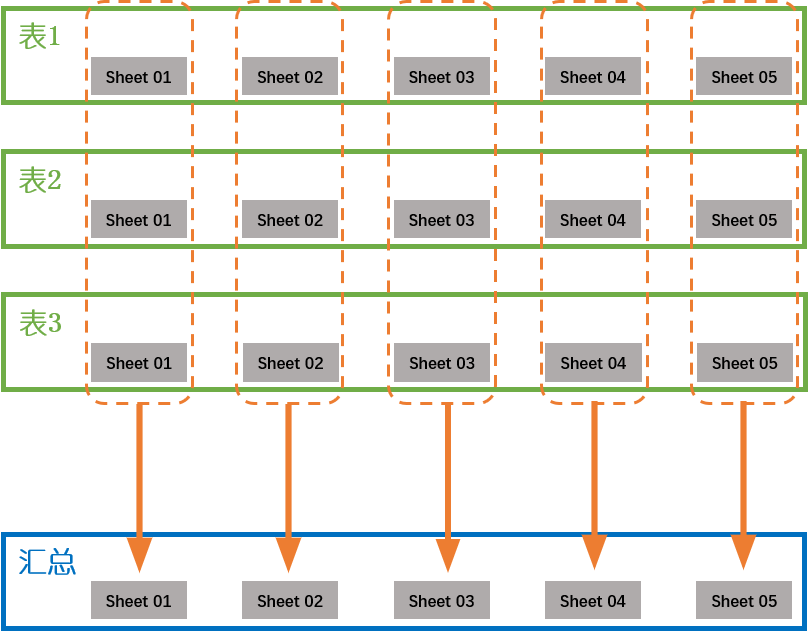
方案
用 pandas 读取 excel 文件作为 DataFrame,对 DataFrame 合并然后再导出为 excel。
pandas 用 read_excel 读取多个 sheet 的 excel 表:
pd.read_excel(path, header=None, sheet_name=None)
- sheet_name=None 表示读取所有的 sheet,如果是单独读取某个 sheet,取值写 sheet 的名字就可以。
- 输出的格式是字典 {‘sheet 01’: pandas.DataFrame, ‘sheet 02’: pandas.DataFrame, ‘sheet 03’: pandas.DataFrame},key 就是 sheet 名,value 就是那张表的 DataFrame 格式。
对于每张 sheet,遍历文件夹内所有 excel 表合成该张 sheet 的汇总。
存为 excel 文件用 to_excel:
writer = pd.ExcelWriter(output_path)
sheet.to_excel(writer, index=False,encoding='utf-8',header=None,sheet_name=s)
- output_path 就是新生成的 excel 表的路径,不需要先建立 excel 文件,直接生成新的 excel 文件。
- 每次的 to_excel 存储 sheet_name 为 s 的数据,连着用几次 to_excel,不同的 sheet_name 就生成不同的 sheet。
考虑到生成文件的管理,或许有时候修改了原数据又要重新生成,或许同名会难以分清。在生成的文件名添加了生成时间作为区分。
使用注意事项,就是最好保证读取的文件夹内只有需要合并的 xlsx 文件,虽然加了正则表达式只识别后缀为 xlsx 的文件。
鉴于小姐妹的财务报表是比较规范的,每张表的格式是一样的,懒得考虑异常处理。最后打包成 exe 发送给小姐妹使用~
代码
# -*- coding: utf-8 -*-
"""
Created on Sat Apr 25 10:28:58 2020
@author: an 橘
"""
import pandas as pd
import os
import time
import re
def get_path(path):
"""返回文件夹下所有文件地址:file_path列表"""
g = os.walk(path)
file_path = []
for path, dir_list, file_list in g:
for file_name in file_list:
if re.search('xlsx$', file_name) != None: # 只读xlsx文件地址
file_path.append(os.path.join(path, file_name))
return file_path
def read_excel(path):
"""每个Excel表存储为一个excel变量(以sheet名为键的字典)"""
p = get_path(path)
num_file = len(p)
excel = [[] for _ in range(num_file)]
for i,p0 in zip(range(num_file),p):
excel[i] = pd.read_excel(p0, header=None, sheet_name=None)
return excel
def sheets_name(excel):
"""返回所有sheet的名字"""
return list(excel[0].keys())
def concat_one_sheet(excel,sheetname):
"""合并一张sheet"""
sheet = []
for i in range(len(excel)):
sheet.append(excel[i][sheetname])
return pd.concat(sheet)
def combine_sheets(excel):
"""遍历所有文件合并对应sheet"""
"""工作簿0~8不合并,取第一张表"""
sheets = sheets_name(excel)
df = []
for s in range(len(sheets)):
if s<9:
df.append(excel[0][sheets[s]])
else:
df.append(concat_one_sheet(excel, sheets[s]))
# 未提出部分工作簿不合并前,做的遍历所有sheet合并
# for s in sheets:
# df.append(concat_one_sheet(excel,s))
return df
def save_file(output_path,excel):
"""保存输出结果"""
sheets = sheets_name(excel)
writer = pd.ExcelWriter(output_path)
df = combine_sheets(excel)
for i,s in zip(range(len(sheets)),sheets):
df[i].to_excel(writer, index=False,encoding='utf-8',header=None,sheet_name=s)
writer.save()
print("合并结果已保存。(文件名为“合并结果+日期+时间”)")
if __name__ == '__main__':
path = input("Hello! 晓兰~\n请确保文件夹下只有需要合并的Excel文件\n第一步:粘贴Excel文件所在的文件夹地址(不包括引号):")
output = input("第二步:粘贴你想要输出文件保存的文件夹(不包括引号):")
excel = read_excel(path)
time = time.strftime("%Y%m%d-%H%M%S", time.localtime())
output_path = output + r'\合并结果' + time + '.xlsx' # 输出文件位置
save_file(output_path,excel)

















 1771
1771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









