



Java集合框架主要分为collection 和map两个类型的容器。
collection主要由List,Set,Queue三个接口直接继承。
一、List是有序的元素可重复的:List下面有个抽象的类 AbstractList,AbstractList抽象类实现了List这个接口。Vector,ArrayList和 LinkedList这三个类是List接口的最终实现类。
二、Set是无序元素不可重复的:Set下面有个抽象的类AbstractSet,AbstractSet抽象类实现了Set这个接口。 HashSet,LinkedHashSet,TreeSet这三个类是Set接口的最终实现类。
三、Queue。
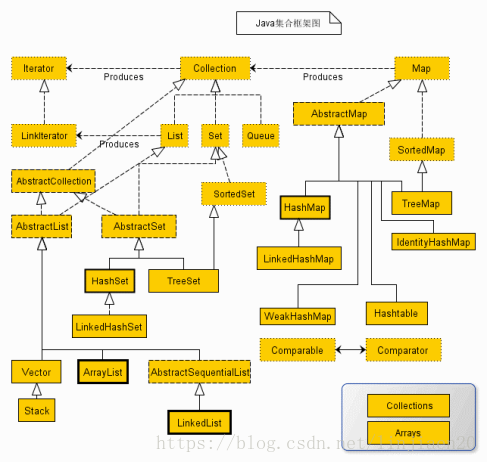
四、Map容器
Map容器下面有个抽象类AbstractMap实现了Map这个接口。也有个SortedMap接口继承了Map这个接口。
Map接口的最终实现类有HashMap,LinkedHashMap,WeakHashMap,
Hashtable,TreeMap,IdentityHashMap。
Vector,ArrayList和LinkedList这三个的区别:
参考链接:
https://www.cnblogs.com/huzi007/p/5550440.html
https://www.cnblogs.com/zkk-wust/p/7250776.html
- Vector和ArrayList都是以基于动态数组的数据结构存储在内存中,LinkedList则是基于链表的数据结构存在内存中。
- Vector是线程安全的,ArrayList和LinkedList不是线程安全的。
- ArrayList在元素填满容器时会自动扩充容器大小的50%,而Vector则是100%,因此ArrayList更节省空间。
- 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
- 对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
public class ListTest {
static final int N=50000;
static long timeList(List list){
long start=System.currentTimeMillis();
Object o = new Object();
for(int i=0;i<N;i++) {
list.add(0, o);
}
return System.currentTimeMillis()-start;
}
static long readList(List list){
long start=System.currentTimeMillis();
int j=list.size();
for(int i=0;i<j;i++){
}
return System.currentTimeMillis()-start;
}
static List addList(List list){
Object o = new Object();
for(int i=0;i<N;i++) {
list.add(0, o);
}
return list;
}
public static void main(String[] args) {
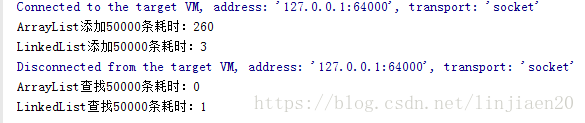
System.out.println("ArrayList添加"+N+"条耗时:"+timeList(new ArrayList()));
System.out.println("LinkedList添加"+N+"条耗时:"+timeList(new LinkedList()));
List list1=addList(new ArrayList<>());
List list2=addList(new LinkedList<>());
System.out.println("ArrayList查找"+N+"条耗时:"+readList(list1));
System.out.println("LinkedList查找"+N+"条耗时:"+readList(list2));
}
}
HashSet,LinkedHashSet和TreeSet这三个的区别:
参考链接:
https://www.cnblogs.com/wl0000-03/p/6019627.html
- HashSet是不可重复的,且不能保证元素的排列顺序,HashSet集合元素可以是null,但只能放入一个null,HashSet也是线程不安全的。当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。
- TreeSet类型是J2SE中唯一可实现自动排序的类型。TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。
- LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
- LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
HashMap,LinkedHashMap,WeakHashMap,Hashtable,TreeMap,IdentityHashMap的区别:
参考链接:
https://blog.youkuaiyun.com/weishiwei0923/article/details/47295757
HashMap与HashTable的区别:
(1)同步性:Hashtable是同步的,这个类中的一些方法保证了Hashtable中的对象是线程安全的。而HashMap则是异步的,因此HashMap中的对象并不是线程安全的。因为同步的要求会影响执行的效率,所以如果你不需要线程安全的集合那么使用HashMap是一个很好的选择,这样可以避免由于同步带来的不必要的性能开销,从而提高效率。
(2)值:HashMap可以让你将空值作为一个表的条目的key或value,但是Hashtable是不能放入空值的。HashMap最多只有一个key值为null,但可以有无数多个value值为null。
LinkedHashMap:
它的父类是HashMap,使用双向链表来维护键值对的次序,迭代顺序与键值对的插入顺序保持一致。LinkedHashMap需要维护元素的插入顺序,so性能略低于HashMap,但在迭代访问元素时有很好的性能,因为它是以链表来维护内部顺序。
TreeMap:
Map接口派生了一个SortMap子接口,SortMap的实现类为TreeMap。TreeMap也是基于红黑树对所有的key进行排序,有两种排序方式:自然排序和定制排序。Treemap的key以TreeSet的形式存储,对key的要求与TreeSet对元素的要求基本一致。
WeakHashMap:
WeakHashMap与HashMap的用法基本相同,区别在于:后者的key保留对象的强引用,即只要HashMap对象不被销毁,其对象所有key所引用的对象不会被垃圾回收,HashMap也不会自动删除这些key所对应的键值对对象。但WeakHashMap的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被回收。WeakHashMap中的每个key对象保存了实际对象的弱引用,当回收了该key所对应的实际对象后,WeakHashMap会自动删除该key所对应的键值对。
IdentityHashMap:
IdentityHashMap与HashMap基本相似,只是当两个key严格相等时,即key1==key2时,它才认为两个key是相等的 。IdentityHashMap也允许使用null,但不保证键值对之间的顺序。

















 115
115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









