






 本文介绍了本地事务与分布式事务的区别,解释了分布式事务产生的原因,并详细探讨了几种常见的分布式事务解决方案,包括补偿事务TCC、本地消息表、MQ非事务消息及MQ事务消息。
本文介绍了本地事务与分布式事务的区别,解释了分布式事务产生的原因,并详细探讨了几种常见的分布式事务解决方案,包括补偿事务TCC、本地消息表、MQ非事务消息及MQ事务消息。
一、本地事务和分布式事务的区别:本地事务只用于处理单一数据源事务(比如单个数据库),分布式事务可以处理多种异构的数据源,比如某个业务操作中同时包含了JDBC和JMS或者某个操作需要访问多个不同的数据库。
二、为什么需要分布式事务:因为分布式系统在与数据库连接时连接了不同的数据库,采用不同的connection对象,无法保证多个connection事务的一致性,会导致数据出现不一致,所以需要分布式事务。
三、CAP定理:CAP定理是由加州大学伯克利分校Eric Brewer教授提出来的,他指出WEB服务无法同时满足一下3个属性
a.一致性(Consistency):( 同样数据在分布式系统的各个节点上都是一致的)
b.可用性(Availability):( 所有在分布式系统活跃的节点都能够处理操作且能响应查询)
c.分区容忍性(Partition Tolerance) :(如果出现了网络故障、一部分节点无法通信,但是系统仍能够工作)
四、分布式事务解决方案:
1.补偿事务TCC(try,confirm,cancel):
TCC的核心思想主要是针对每一个操作,都要注册一个与其对应的确认与撤销操作。分为三个步骤:
- Try阶段主要对业务系统做检测和资源预留;
- Confirm阶段主要对业务系统做确认提交,Try阶段执行成功并开始执行Confirm阶段时,默认Confirm阶段一定不会出错。即:只要Try成功,Confirm一定成功。
- Cancel阶段主要是在业务执行错误,需要回滚的情况下执行的业务取消,预留资源释放。
举个例子:
某用户在银行提款100元,这三个阶段对应如下:
a.Try:先调用远程的接口冻结这个用户在银行中的账户100元,然后调用远程的转账接口;
b.Confirm:若转账成功,调用远程的接口将100元扣除;
c.Cancel:若转账失败,调用远程的接口解冻100元。
优点:流程相对简单了一些,但数据的一致性要差一些;
缺点: 实现复杂,牺牲了可用性,对性能影响较大,不适合高并发高性能场景。
2.本地消息表(经典的ebay模式):
核心思想:其基本的设计思想是将远程分布式事务拆分成一系列的本地事务。
举个例子:在线支付系统的跨行转账
a.伪代码如下,对用户id为A的账户扣款1000元,通过本地事务将事务消息(包括本地事务id、支付账户、收款账户、金额、状态等)插入至消息表:
Begin transaction
update user_account set amount = amount - 1000 where userId = 'A'
insert into trans_message(xid,payAccount,recAccount,amount,status) values(uuid(),'A','B',1000,1);
end transaction
commit;
b.通知对方用户id为B,增加1000元。那问题来了,如何通知到对方呢?
通常采用两种方式:
- 采用时效性高的MQ,由对方订阅消息并监听,有消息时自动触发事件
- 采用定时轮询扫描的方式,去检查消息表的数据。
两种方式其实各有利弊,仅仅依靠MQ,可能会出现通知失败的问题。而过于频繁的定时轮询,效率也不是最佳的(90%是无用功)。所以,我们一般会把两种方式结合起来使用。
这里为了保证幂等性,防止触发重复的转账操作,需要在执行转账操作方新增一个trans_recv_log表用来做幂等,在第二阶段收到消息后,通过判断trans_recv_log表来检测相关记录是否被执行,如果未被执行则会对B账户余额执行加1000元的操作,并会将该记录增加至trans_recv_log,事件结束后通过回调更新trans_message的状态值。
优点: 一种非常经典的实现,避免了分布式事务,实现了最终一致性
缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。关系型数据库的吞吐量和性能方面存在瓶颈,频繁的读写消息会给数据库造成压力。所以,在真正的高并发场景下,该方案也会有瓶颈和限制的。
3.MQ(非事务消息)
通常情况下,在使用非事务消息支持的MQ产品时,我们很难将业务操作与对MQ的操作放在一个本地事务域中管理。通俗点描述,还是以上述提到的“跨行转账”为例,我们很难保证在扣款完成之后对MQ投递消息的操作就一定能成功。
先从消息生产者这端来分析,请看伪代码:
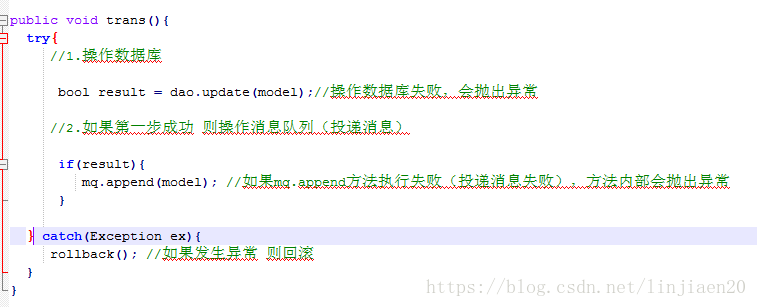
我们来分析下可能的情况:
a.操作数据库成功,向MQ中投递消息也成功,皆大欢喜
b.操作数据库失败,不会向MQ中投递消息了
c.操作数据库成功,但是向MQ中投递消息时失败,向外抛出了异常,刚刚执行的更新数据库的操作将被回滚
从上面分析的几种情况来看,貌似问题都不大的。那么我们来分析下消费者端面临的问题:
a.消息出列后,消费者对应的业务操作要执行成功。如果业务执行失败,消息不能失效或者丢失。需要保证消息与业务操作一致
b.尽量避免消息重复消费。如果重复消费,也不能因此影响业务结果
如何保证消息与业务操作一致,不丢失?
主流的MQ产品都具有持久化消息的功能。如果消费者宕机或者消费失败,都可以执行重试机制的(有些MQ可以自定义重试次数)。
如何避免消息被重复消费造成的问题?
a.保证消费者调用业务的服务接口的幂等性
b.通过消费日志或者类似状态表来记录消费状态,便于判断(建议在业务上自行实现,而不依赖MQ产品提供该特性)
优点:这种方式比较常见,性能和吞吐量是优于使用关系型数据库消息表的方案。如果MQ自身和业务都具有高可用性,理论上是可以满足大部分的业务场景的。
缺点:不过在没有充分测试的情况下,不建议在交易业务中直接使用。
4.MQ 事务消息
有一些第三方的MQ是支持事务消息的,比如RocketMQ,他们支持事务消息的方式也是类似于采用的二阶段提交,但是市面上一些主流的MQ都是不支持事务消息的,比如 RabbitMQ 和 Kafka 都不支持。
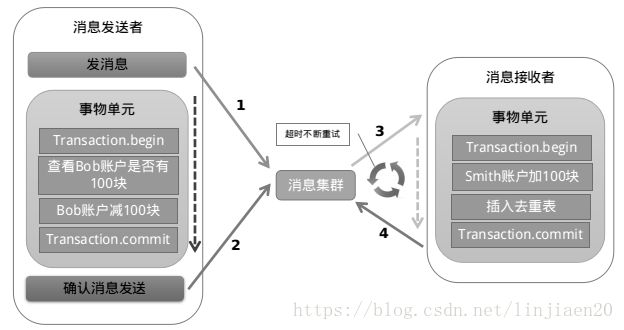
以阿里的 RocketMQ 中间件为例,其思路大致为:
第一阶段,RocketMQ在执行本地事务之前,会先发送一个Prepared消息,并且会持有这个消息的地址
第二阶段,执行本地事物操作
第三阶段,确认消息发送,通过第一阶段拿到的地址去访问消息,并修改状态,如果本地事务成功,则修改状态为已提交,否则修改状态为已回滚
也就是说在业务方法内要向消息队列提交两次请求,一次发送消息和一次确认消息。如果确认消息发送失败了RocketMQ会定期扫描消息集群中的事务消息,这时候发现了Prepared消息,它会向消息发送者确认,所以生产方需要实现一个check接口,RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
优点: 实现了最终一致性,不需要依赖本地数据库事务。
缺点: 实现难度大,主流MQ不支持,没有.NET客户端,RocketMQ事务消息部分代码也未开源。
这些解决方案都是为了解决分布式系统数据最终一致性的问题。

















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









