







在数据分析、机器学习、深度学习中我们需要划分训练集用于生成模型和测试集用于检验模型拟合度。在划分时通常由手动划分和函数划分两种。
以某案例数据为例,有338条14项特征值数据和对应的338条标签数据,此时以转换为数组格式。
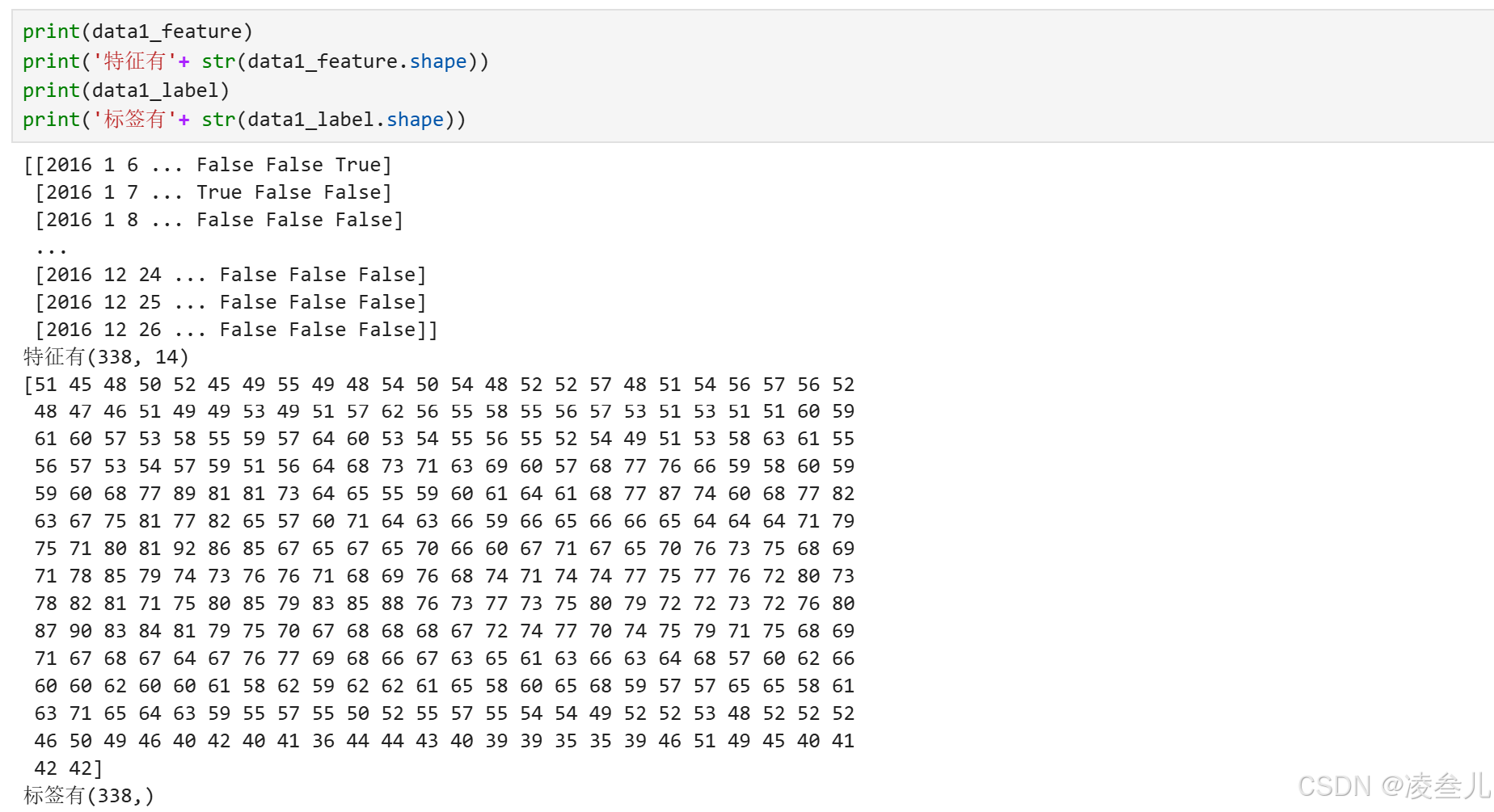
手动划分
- 不需要引入额外函数,适用于数据量较小的情况
- 简单,按照数组划分的方法进行划分即可。
- 缺点:不方便进行调整,不具备随机抽选性
# 划分为255条训练数据与83条测试数据
data1_train_feature = data1_feature[:255]
data1_test_feature = data1_feature[255:]
data1_train_label = data1_label[:255]
data1_test_label = data1_label[255:]
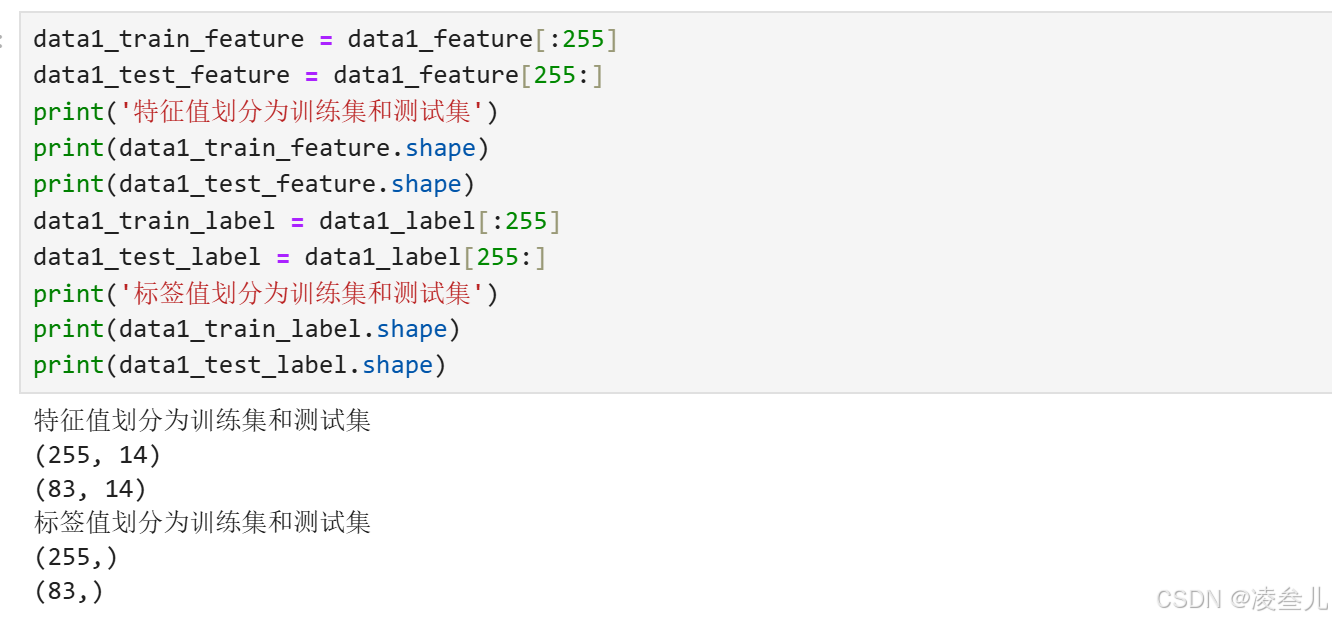
函数划分
python机器学习中常用 train_test_split()函数划分训练集和测试集。
-其用法语法如下:
# 引入划分函数
from sklearn.ensemble import RandomForestRegressor
X_train, X_test, y_train, y_test = train_test_split(train_data, train_target, test_size, random_state, shuffle)
| 变量 | 含义 |
|---|---|
| X_train | 划分的训练集数据 |
| X_test | 划分的测试集数据 |
| y_train | 划分的训练集标签 |
| y_test | 划分的测试集标签 |
| 参数 | 功能 |
|---|---|
| train_data | 还未划分的数据集 |
| train_target | 还未划分的标签 |
| test_size | 分割比例,默认为0.25,即测试集占完整数据集的比例 |
| random_state | 随机数种子,应用于分割前对数据的洗牌。可以是int,RandomState实例或None,默认值=None。设成定值意味着,对于同一个数据集,只有第一次运行是随机的,随后多次分割只要rondom_state相同,则划分结果也相同。 |
| shuffle | 是否在分割前对完整数据进行洗牌(打乱),默认为True,打乱 |
可以看出来,该函数不仅可以设置分割比例完成自动分割,还能通过random_state和shuffle进行随机划分实现每一次划分都是不同的。
在本例中,用以下代码将特征值与标签值按照3:1的比例划分训练集和测试集。
# 引入划分函数
from sklearn.ensemble import RandomForestRegressor
data1_train_feature, data1_test_feature, data1_train_label, data1_test_label = train_test_split(
data1_feature, data1_label, test_size = 0.25 , random_state = 0)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











