






学习地址:
学习小册
大白话讲清楚:什么是 Langchain 及其核心概念
开篇
随着基础模型越来越卷,token会越来越便宜,性能越来越强,速度越来越快。
为什么是LangChain
LLM(大语言模型)的API只是提供了一个非常基础的调用方式,当要构建一个复杂的chat bor的时候,需要考虑如何保存聊天上下文,如何进行网络搜索等问题,这些问题都是应用框架帮我们解决的。
想象一下,如果能让聊天机器人不止能回答通用问题,还能从你自己的数据库或者文件中提取信息,并根据这些信息进行回答,做出反应,进而成为一个私人机器人,LangChain就是做这个的。它允许开发人员,将LLM和外部的计算和数据源结合起来,允许将大模型链接到自己的数据元,还能根据这些信息执行特定操作,比如发送邮件等操作。
可以理解LangChain等价于数据库的JDBC,它扮演一个中介的角色,底层可以是不同的模型。
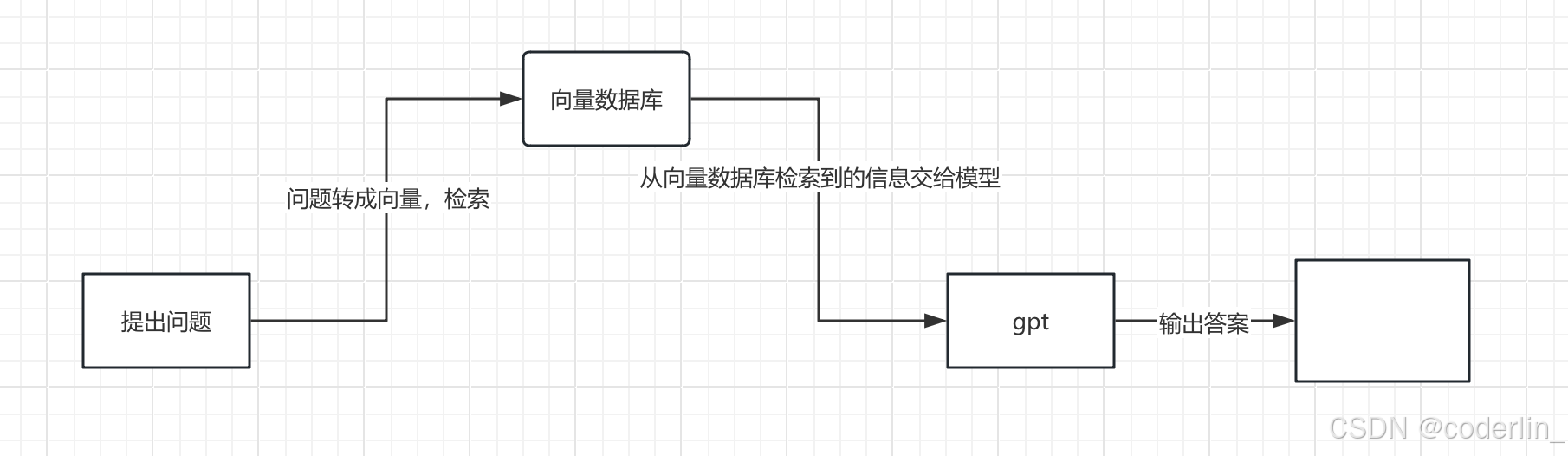
LangChain如何工作?
用户提出问题;
问题被转为向量,用于在向量数据库中进行相似性搜索,获取相关信息。
从向量数据库中取出相关信息快,输入给语言模型,生成答案。
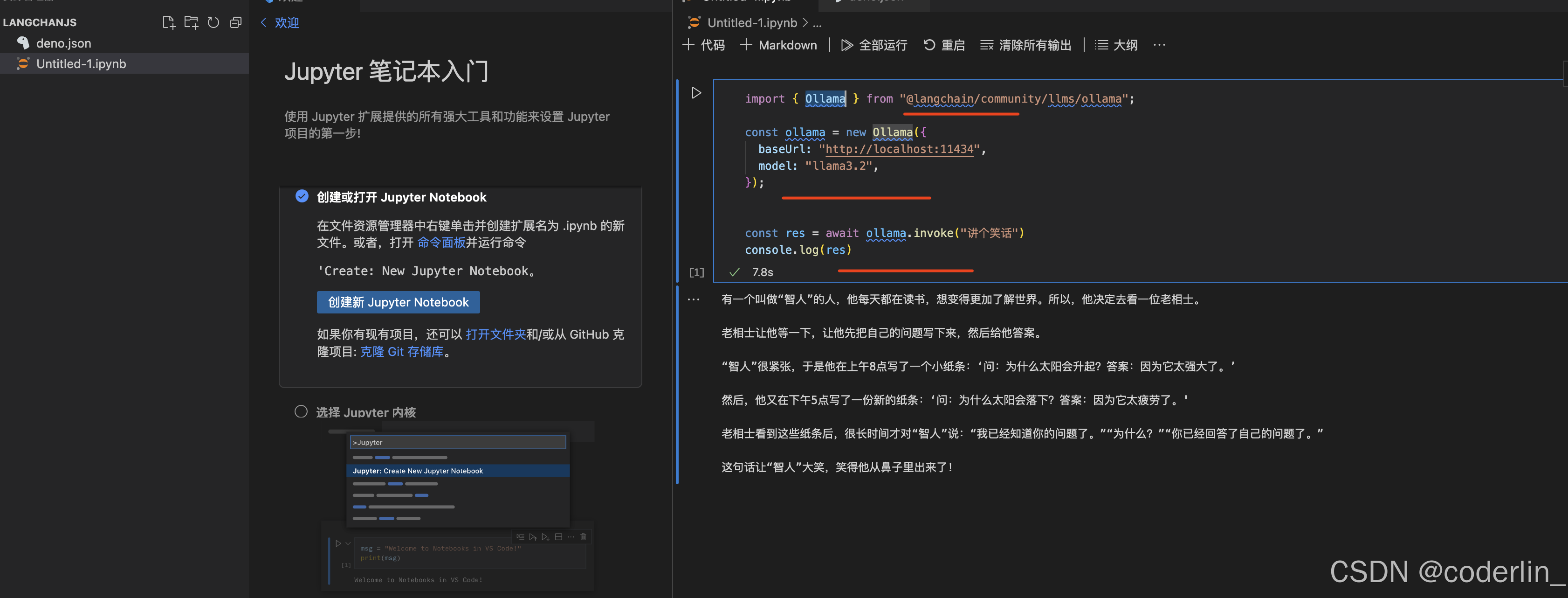
Deno+Jupyter NoteBook
在vscode中借用Jupyter插件,然后用deno环境。因为是本地练习,所以使用本地大模型,llama3.2。
api
Runnable对象,每个模型实例都是一个Runnable,有几个常用的调用接口
- invoke 基础调用
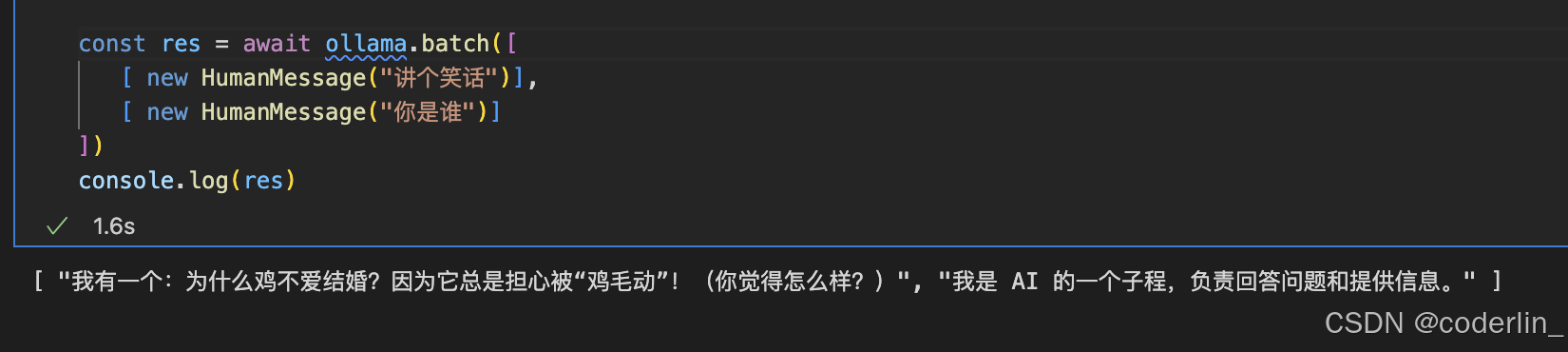
- batch 批量调用
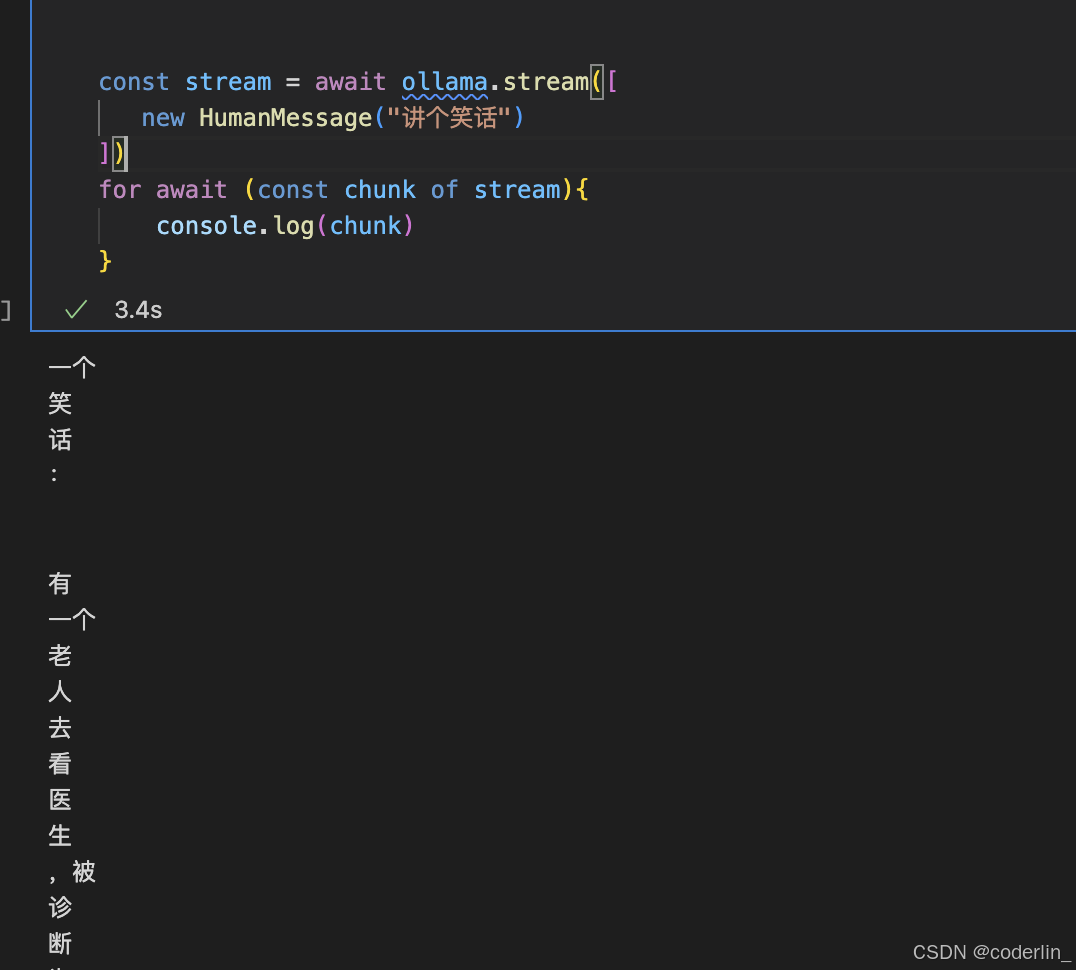
- stream,以stream流的方式返回
- streamLog,以stream流的方式返回,并且返回中间运行结果。
batch
stream,LLM很多调用都是一段一段返回的,如果等到完整的内容再返回,就会等待比较久,影响体验。可以用stream的形。
- fallback
withFallbacks是每个runnable都有一个一个函数,相当于兜底对象,大多数runnable都自带出错重试机制。无论是llm model或者其他模块,还是整个chain都是runnable对象,可以给整个LCEL流程的任意缓解增加fallback,避免出现问题后卡住剩下环境的运行。
也可以个整个chain增加fallback,例如一个复杂但输出高质量的chain可以设置一个非常简单的chain作为callback,可以保证在极端环境下有输出。
RAG
Retrieval Augmented Generation,检索增强生产技术,核心流程:检索->增强->生成。
LLM的局限性
-
1幻觉问题,llm本身是基于大量数据训练出来的概率模型,是伪智能,而不是底层基于逻辑和推理能力的真智能。
举个例子,给一个猴子一个打字机,让他随便打字,只要实验时间是无限的,总有一天,他会打出一部完整的莎士比亚小说。
但这个猴子并不懂莎士比亚,不具备逻辑,只不过一切概率性的巧合凑到一起。
而llm就是一个更大概率打出莎士比亚小说的猴子,他不理解文本逻辑,也不理解内容,只不过他的模型足够强大,训练数据集足够大,输出内容的概率也足够大,从外界来看,他就像真正理解内容一样,也就像具有真正的逻辑和推理能力。 -
2 领域知识的缺陷。分两种情况,一种是对知识的更新慢(问他最新的i新闻他肯定不知道,因为训练数据集不可能每天都更新。),一种是特定领域的知识不了解(比如做一个宠物医疗机器人,它本身训练数据集这方面的知识,就容易出现幻想问题,瞎回答)。更不要说问公司内部的知识库了。
RAG就是针对这两点解决的。
RAG原理
在了解了llm是基于概率性的底层逻辑后,那么解决方法就是尽可能提供与答案相关的上下文,来增强他正确的输出的可能性。形象地说就是,拿一本莎士比亚文集放在猴子身边,让他一般看一边打字。
RAG流程:
1 用户输入提问
2 检索:根据用户提问转为向量,对向量数据库进行相似性检测,查找与用户回答问题最相关的内容。
3 增强:根据检索的结果,生成prompt,一般都会加一个限制“仅依赖下述信息源来回答问题”,这种限制llm参考信息源的语句,来减少幻想,让回答更加聚焦。
4 生成:将增强后的prompt传给llm,返回数据给用户。
RAG就是哪里有问题解决哪里,大模型无法获得最新和内部的数据集,那就使用外挂的向量数据库为llm提供最新和内部的数据库,既然llm有幻想问题,就将回答问题所需要的信息和知识编码到上下文中,强制大模型只参考这些内容进行回答。
更底层的逻辑就是,llm是逻辑推理引擎,而不是信心引擎。由外挂的向量数据库提供最有效的知识,然后由llm根据知识进行推理,提供有价值的恢复。
RAG流程
- 1 加载数据,将数据集放到向量数据库中。
- 2 切分数据,gpt3.5t 的上下文窗口是 16k,gpt4t 上下文窗口是 128k,而我们很多数据源都很容易比这个大,需要对数据集进行切分,根据内容特点和目标大模型的特点,对数据源进行切分。
- 3 嵌入embedding,将文档使用embedding算法转换成向量,存放到向量数据库。
- 4 检索数据,将用户提问embedding成向量,去向量数据库中进行检索,找到相似性最高的几个文档块返回。
- 5 增强prompt,根据检索到的文档快,构建prompt,比如
你是一个 xxx 的聊天机器人,你的任务是根据给定的文档回答用户问题,并且回答时仅根据给定的文档,尽可能回答
用户问题。如果你不知道,你可以回答“我不知道”。
这是文档:
{docs}
用户的提问是:
{question}
- 6 生成:将组装好的prompt交给llm,进行生成回答。
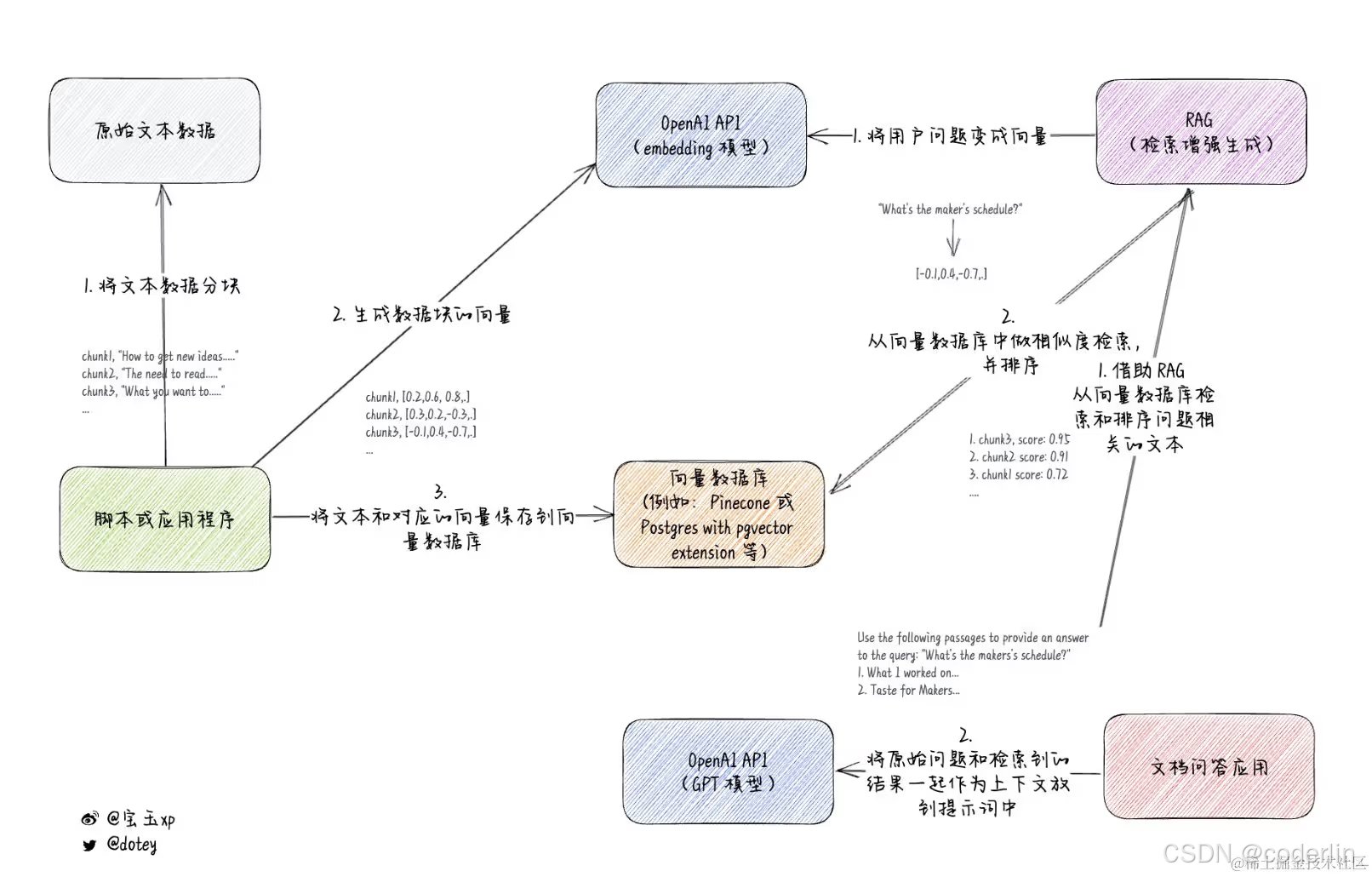
简单来说,就是llm学习一次流程比较长,所以我们可以外挂一个向量数据库,给llm提供一个上下文环境,在回答中,把上下文给llm作为前置条件来回答问题。(而不是内容作为数据集让llm去训练)
Prompt
Prompt 是大模型的核心,传统方式我们一般使用字符串拼接或者模版字符串来构造 prompt,而有了 langchain 后,我们可以构建可复用的 prompt 来让我们更工程化的管理和构建 prompt,从而制作更复杂的 chat bot
最简单的template prompt
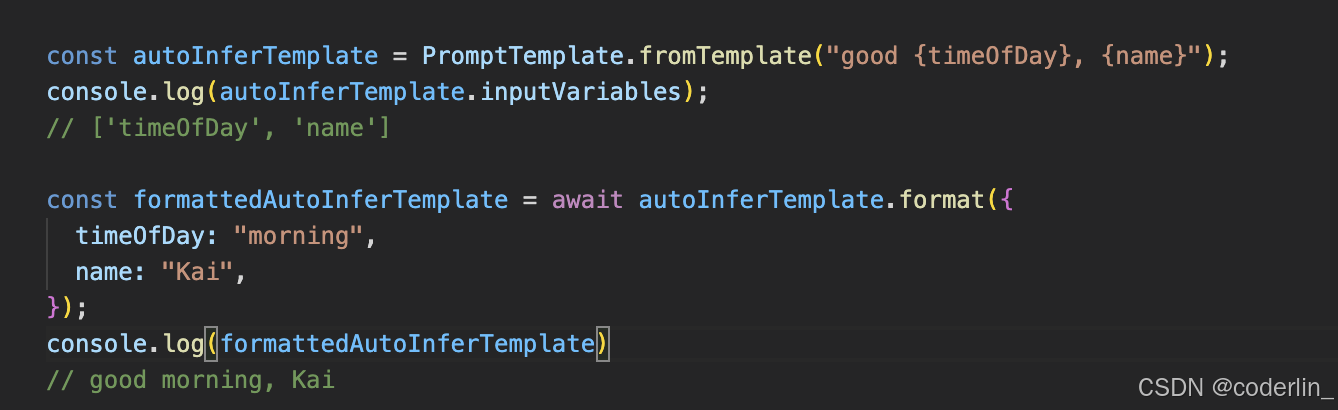
chat prompt
在openAi的定义中,每一条消息都跟一个role关联。角色的概念对于llm理解和构建整个对话流程非常重要。
- system 通常设置对话的上下文或指定模采取特定的行为模式。可以理解成模型的源信息,权重很高。比如
你是专业的xxx,你的任务是xxx - user 角色代表真实用户在对话中的发言。这些消息通常是问题、指令或者评论,反映了用户的意图和需求。
- assistant 角色的消息代表AI模型的回复。这些消息是模型根据system的指示和user的输入生成的。
如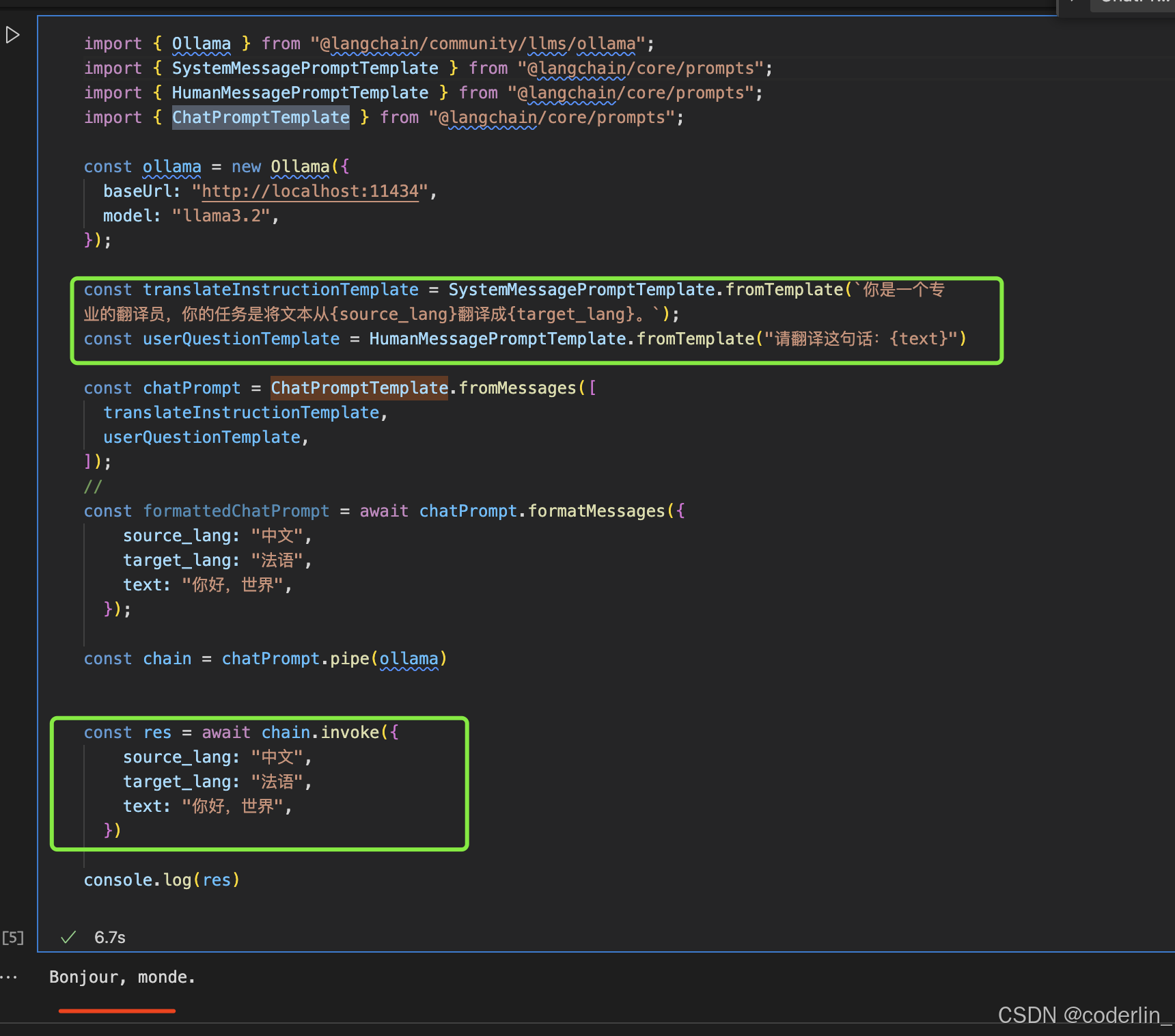
组合多个prompt
实际工程中可能会根据多个变量,根据外界环境去构建一个很复杂的prompt,这就是PipelinePromptTemplate的应用场景。
PipelinePromptTemplate核心概念
- pipelinePrompts,一组 object,每个 object 表示 prompt 运行后赋值给 name 变量
- finalPrompt,表示最终输出的 prompt
const getCurrentDateStr = () => {
return new Date().toLocaleDateString();
};
const fullPrompt = PromptTemplate.fromTemplate(`
你是一个智能管家,今天是 {date},你的主人的信息是{info},
根据上下文,完成主人的需求
{task}`);
const datePrompt = PromptTemplate.fromTemplate("{date},现在是 {period}")
const periodPrompt = await datePrompt.partial({
date: getCurrentDateStr
})
const infoPrompt = PromptTemplate.fromTemplate("姓名是 {name}, 性别是 {gender}");
const taskPrompt = PromptTemplate.fromTemplate(`
我想吃 {period} 的 {food}。
再重复一遍我的信息 {info}`);
可以看到,不同的prompt可以用同一个变量,比如period。
通过PipelinePromptTemplate组合起来。
onst composedPrompt = new PipelinePromptTemplate({
pipelinePrompts: [
{
name: "date",
prompt: periodPrompt,
},
{
name: "info",
prompt: infoPrompt,
},
{
name: "task",
prompt: taskPrompt,
},
],
finalPrompt: fullPrompt,
});
const formattedChatPrompt = await composedPrompt.format({
period: "早上",
name: "张三",
gender: "男",
food: "手抓饼"
});
console.log('提问信息是:\n', formattedChatPrompt);
const chain = composedPrompt.pipe(ollama)
const res = await chain.invoke({
period: "早上",
name: "张三",
gender: "男",
food: "手抓饼"
})
console.log(res)
而且,pipelinePrompts中的变量可以被引用,可以看到在taskPrompt使用了infoPrompt的运行结果。
langchain 会自动分析 pipeline 之间的依赖关系,尽可能的进行并行化来提高运行速度
运行结果

OutputParser
解析模型输出,引导模型以需要的格式进行输出。
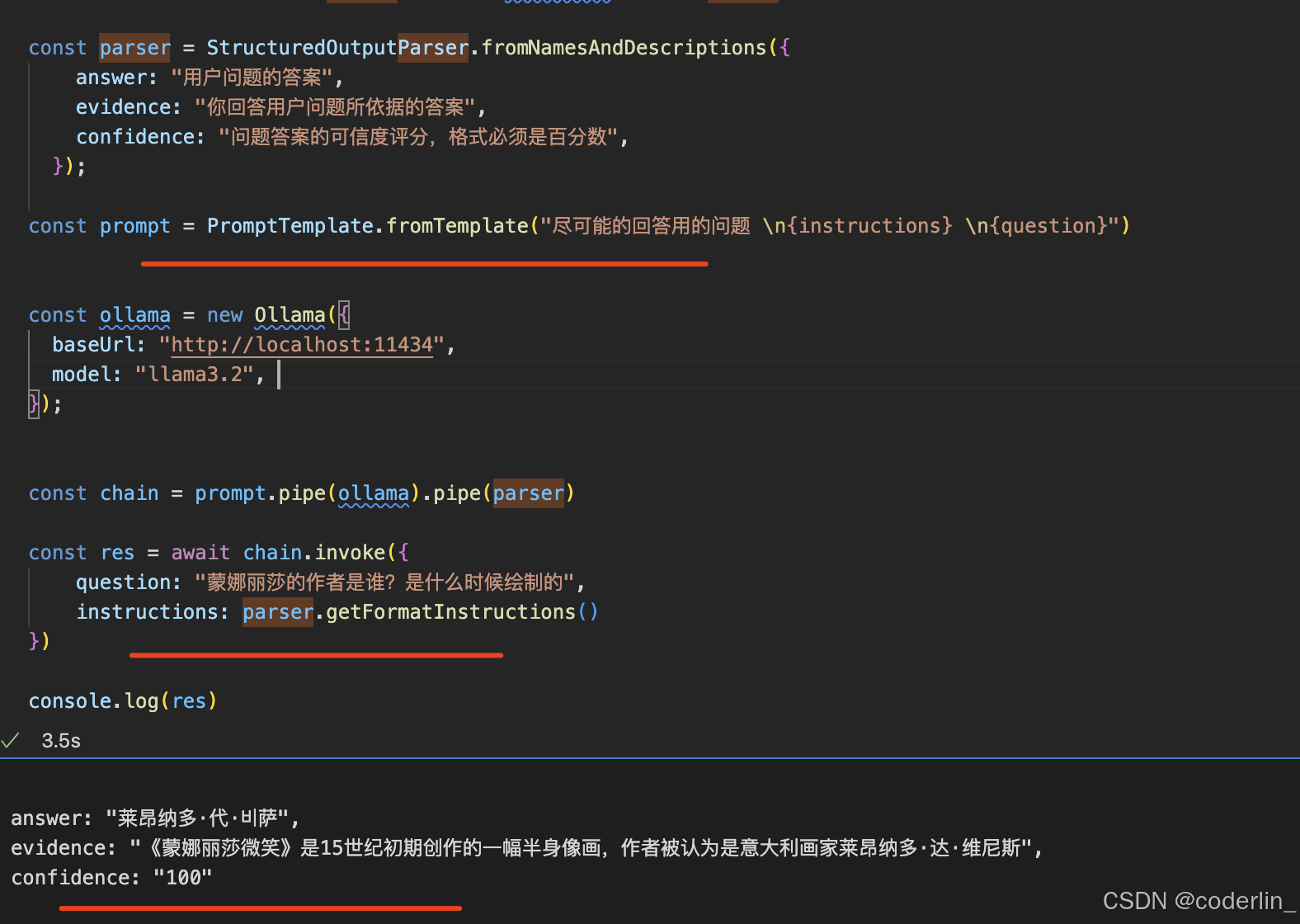
因为是本地模型,答案不是很准确。
Auto Fix Parser
对于出现了输出不符合要求的情况,我们希望llm不反复输出,因为llm可能没有认识到自己的错误,所以需要我们把报错信息返回给llm,让他理解错在哪里,怎么修复。


















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











