




 本文深入解析决策树算法的三种主要类型:ID3、C4.5和CART,包括它们的计算原理、优缺点及应用。ID3算法通过信息增益选择最佳特征,但不适用于连续数据且容易过拟合;C4.5改进了信息增益比并能处理连续值,引入剪枝技术防止过拟合;CART算法采用基尼指数评估纯度,适用于分类和回归任务。
本文深入解析决策树算法的三种主要类型:ID3、C4.5和CART,包括它们的计算原理、优缺点及应用。ID3算法通过信息增益选择最佳特征,但不适用于连续数据且容易过拟合;C4.5改进了信息增益比并能处理连续值,引入剪枝技术防止过拟合;CART算法采用基尼指数评估纯度,适用于分类和回归任务。
决策树类型
一. ID3
ID3是基于信息增益作为决策树分裂特征选择的一种决策树算法。
信息熵:
H=∑i=0n−Pi∗logPiH = \sum_{i=0}^n-P_i * log P_iH=∑i=0n−Pi∗logPi
信息熵值越大,混乱程度越高,不确定性越高。
条件熵:
H(Y丨X)=∑i=0nP(Xi)∗H(Y丨Xi)H(Y丨X) = \sum_{i=0}^nP(X_i) * H(Y丨X_i)H(Y丨X)=∑i=0nP(Xi)∗H(Y丨Xi)
条件熵是指在已知X的情况下Y的不确定性。
信息增益
g(Y丨X)=H(Y)−H(Y丨X)g(Y丨X ) = H(Y) - H(Y丨X)g(Y丨X)=H(Y)−H(Y丨X)
信息增益是指在知道了X之后对于Y不确定性的减少程度。
测试数据集
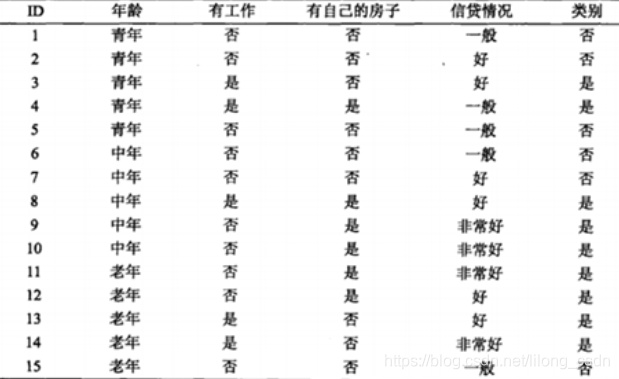
现在有年龄、工作、房子、信贷情况4个特征, 首先每个特征都计算一次信息增益,选择信息增益最大的作为根节点
以年龄为例:
H(类别)=−915∗log2915−615∗log2615=0.971H(类别) = -\frac {9} {15} *log_2\frac {9} {15}-\frac {6} {15} *log_2\frac {6} {15} = 0.971H(类别)=−159∗log2159−156∗log2156=0.971
H(类别丨年龄=青年)=−35∗log235−25∗log225=0.971H(类别丨年龄=青年) = -\frac {3} {5} *log_2\frac {3} {5}-\frac {2} {5} *log_2\frac {2} {5} = 0.971H(类别丨年龄=青年)=−53∗log253−52∗log252=0.971
H(类别丨年龄=中年)=−35∗log235−25∗log225=0.971H(类别丨年龄=中年) = -\frac {3} {5} *log_2\frac {3} {5}-\frac {2} {5} *log_2\frac {2} {5} = 0.971H(类别丨年龄=中年)=−53∗log253−52∗log252=0.971
H(类别丨年龄=老年)=−45∗log245−15∗log215=0.722H(类别丨年龄=老年) = -\frac {4} {5} *log_2\frac {4} {5}-\frac {1} {5} *log_2\frac {1} {5} = 0.722H(类别丨年龄=老年)=−54∗log254−51∗log251=0.722
g(类别丨年龄)=H(类别)−515∗H(类别丨年龄=青年)−515∗H(类别丨年龄=中年)−515∗H(类别丨年龄=老年)=0.082g(类别丨年龄) = H(类别)- \frac {5} {15}*H(类别丨年龄=青年)- \frac {5} {15}*H(类别丨年龄=中年)- \frac {5} {15}*H(类别丨年龄=老年) = 0.082g(类别丨年龄)=H(类别)−155∗H(类别丨年龄=青年)−155∗H(类别丨年龄=中年)−155∗H(类别丨年龄=老年)=0.082
依次计算工作、房子、信贷等的信息增益,选择其中最大的作为根节点。后续的节点也是同样的操作。
ID3j决策树代码
import numpy as np
import pandas as pd
from collections import defaultdict
# 计算信息熵
# 输入 pd.Series
# 输出 信息熵值
def calc_info_entropy(d_series):
ps = d_series.value_counts() / len(d_series)
return np.sum(ps.apply(lambda x: -x * np.log2(x)))
# 计算条件熵
# 输入 条件Series 目标Series
# 输出 条件熵值
def calc_condition_entropy(cond, target):
entropys = target.groupby(cond).apply(lambda group: calc_info_entropy(group) * len(group) / len(target))
return np.sum(entropys)
# 计算信息增益
# 输入 条件Series 目标Series
# 输出 条件熵值
def calc_info_gain(cond, target):
return calc_info_entropy(target) - calc_condition_entropy(cond, target)
# 返回作为分裂点的特征
# 输入 data_features pd.Dataframe
# data_label pd.Series
def get_best_feature(data_features, data_label):
values = data_features.apply(lambda x: calc_info_gain(x, data_label), axis=0)
return values.idxmax()
# 创建决策树
def create_tree(df_features, df_label):
ret = defaultdict(dict)
if df_features.shape[1] == 1: #特征分裂到最后一个的时候 选择各类别中多数的label值作为value
all = pd.concat([df_features, df_label], axis=1)
for key in np.unique(df_features.values):
f_name = df_features.columns[0]
l_name = df_label.name
value = all[all[f_name] == key][l_name].value_counts().idxmax()
ret[f_name][key] = value
ret = dict(ret)
else:
best_feature = get_best_feature(df_features, df_label)
all = pd.concat([df_features, df_label], axis=1)
cols = list(df_features.columns)
cols.remove(best_feature)
for key in set(df_features[best_feature]):
# 如果该key下都是同一类 直接赋值
if len(all[all[best_feature] == key][df_label.name].value_counts()) == 1:
ret[best_feature][key] = all[all[best_feature] == key][df_label.name].values[0]
else:
ids = df_features[best_feature] == key
ret[best_feature][key] = dict(create_tree(df_features[cols][ids],
all[ids][df_label.name]))
ret = dict(ret)
return ret
# 测试数据集
def create_test_data():
test_data = np.array([['青年','否','否','一般','否'],
['青年','否','否','好','否'],
['青年','是','否','好','是'],
['青年','是','是','一般','是'],
['青年','否','否','一般','否'],
['中年','否','否','一般','否'],
['中年','否','否','好','否'],
['中年','是','是','好','是'],
['中年','否','是','非常好','是'],
['中年','否','是','非常好','是'],
['老年','否','是','非常好','是'],
['老年','否','是','好','是'],
['老年','是','否','好','是'],
['老年','是','否','非常好','是'],
['老年','否','否','一般','否']])
ret = pd.DataFrame(test_data, columns=['年龄', '有工作', '有自己的房子', '信贷情况', '类别'])
return ret
if __name__ == '__main__':
data = create_test_data()
print(create_tree(data[['年龄', '有工作', '有自己的房子', '信贷情况']], data['类别']))
运行结果:
{‘有自己的房子’: {‘否’: {‘有工作’: {‘否’: ‘否’, ‘是’: ‘是’}}, ‘是’: ‘是’}}
ID3缺点
- ID3不能处理连续的数据
- 只有树的生成,很容易过拟合
- ID3更偏向于取值比较多的特征,从公式可以看出:取值越多, 条件熵越小, 信息增益越大
二. C4.5
信息增益比
gr(Y丨X)=g(Y丨X)HX(Y)g_r(Y丨X) = \frac{g(Y丨X )}{H_X(Y)}gr(Y丨X)=HX(Y)g(Y丨X)
g(Y丨X)g(Y丨X )g(Y丨X)即之前提到的信息增益, HX(Y){H_X(Y)}HX(Y)是在数据Y中X的信息熵。1HX(Y)\frac{1}{H_X(Y)}HX(Y)1可以看做是信息增益的一个惩罚系数。以信息增益作为分裂节点的原则的时候会偏向于类别数目较多的特征,但是在信息增益比中,如果X的类别较多,那么HX(Y)H_X(Y)HX(Y)相对较大,倒数也便比较小,在一定程度上惩罚了信息增益值。
C4.5决策树就是以信息增益比作为根节点选择的依据的。C4.5相对于ID3还有如下改变:
1—C4.5可以处理连续值属性:
假设某属性的值为【5,2,1,3,4】先对这些值进行排序,【1,2,3,4,5】,然后每次取两个值的中值可以把所有的值分为两类,那么数值变量就变成了类别变量。比如取1.5, 那么数据就分为大于1.5和小于1.5两类,计算的过程中选择最大信息增益比的中值
2—C4.5可以进行剪枝
C4.5采用的剪枝算法为PEP(Pessimistic Error Pruning)剪枝法,该剪枝算法为后剪枝算法(自顶向下),且不需要验证集。
PEP(Pessimistic Error Pruning)剪枝法(悲观错误剪枝法)
假设一棵树的叶子节点覆盖了n个样本,其中有e个错误,那么该叶子节点的错误率为e+0.5n\frac{e+0.5}{n}ne+0.5,0.5为惩罚系数。假设一棵树有L个叶子节点,那么这棵树的错误率为 ErrorRate=∑i=1Lei+0.5L∑i=1LniErrorRate=\frac{\sum_{i=1}^Le_i+0.5L}{\sum_{i=1}^Ln_i}ErrorRate=∑i=1Lni∑i=1Lei+0.5L
其中eie_iei表示叶子节点iii的错误数量,nin_ini表示叶子节点iii的覆盖样本数量
假如一棵树错误分类一个样本记做1,正确分类一个样本记做0,那么他满足二项分布。
ErrorMean=n∗p=∑i=1Lni∗ErrorRateErrorMean=n*p=\sum_{i=1}^{L}n_i*ErrorRateErrorMean=n∗p=∑i=1Lni∗ErrorRate
ErrorStd=n∗p∗q=∑i=1Lei∗ErrorRate∗(1−ErrorRate)ErrorStd=n*p*q=\sqrt{\sum_{i=1}^{L}e_i*ErrorRate*(1-ErrorRate)}ErrorStd=n∗p∗q=∑i=1Lei∗ErrorRate∗(1−ErrorRate)
把一棵子树替换为叶子节点之后的错误率
ErrorRate‘=e‘+0.5n‘ErrorRate^`=\frac{e^`+0.5}{n^`}ErrorRate‘=n‘e‘+0.5
其中e‘e^`e‘是新树的全部错误数量,n‘n^`n‘是新树覆盖的样本数量
ErrorMean‘=∑i=1Lni‘∗ErrorRate‘ErrorMean^`=\sum_{i=1}^{L}n_i^`*ErrorRate^`ErrorMean‘=∑i=1Lni‘∗ErrorRate‘
当:
ErrorMean−ErrorStd>ErrorMean‘ErrorMean-ErrorStd>ErrorMean^`ErrorMean−ErrorStd>ErrorMean‘
的时候,进行剪枝
3—C4.5可以处理空值的情况
在构建决策树的过程中,如果某个样本的某个属性有空值,可以选择忽略掉这个样本,或者选择一个该属性中频率最高的值来填充
决策树构建完成之后,对于一个待分类的测试数据中的空值,要么使用一个该属性中频率最高的值来进行填充,要么直接终止该子树的构建,选择类别中频率最大的值来作为分类结果
C4.5缺点
1—算法的计算效率比较低,特备是涉及到连续属性值的时候
2—在选择分裂属性的过程中没有考虑属性之间的相关性,只是考虑了特征与label之间的期望信息,在一定程度上影响了树的正确构建
C4.5代码
只需要修改一下ID3的get_best_feature方法
# 返回作为分裂点的特征
# 输入 data_features pd.Dataframe
# data_label pd.Series
def get_best_feature(data_features, data_label):
# ID3 信息增益作为分裂依据
# values = data_features.apply(lambda x: calc_info_gain(x, data_label), axis=0)
# C4.5信息增益比作为分裂依据
values = data_features.apply(lambda x: calc_info_gain(x, data_label) / calc_info_entropy(x), axis=0)
return values.idxmax()
三. CART
CART又叫分类与回归树。当用作分类的时候,采用基尼指数作为评价纯度的标准。
基尼指数
Gini(p)=∑k=1kpk(1−pk)=1−∑k=1kpk2Gini(p)=\sum_{k=1}^kp_k(1-p_k)=1-\sum_{k=1}^kp_k^2Gini(p)=∑k=1kpk(1−pk)=1−∑k=1kpk2
从公式上来理解基尼指数就是:被选中的概率*被分错的概率,那么可以看出基尼指数的值越小越好。
以上边数据的年龄为例,年龄分为青年、中年、老年, 它的子集为{青年、中年、老年}、{},{青年}、{中年}、{老年}、{青年、中年}、{青年、老年}、{中年、老年},有效子集需要去掉全集和空集,还剩下6个,即2n−22^n-22n−2个。可以看出把数据分为了两类,属于该子集与不属于该子集,可以看出CART决策树实际上是二叉树
Gini青年、中年年龄=D1DGini(D1)+D2DGini(D1)=1015∗(1−5102−5102)+515∗(1−352−252)Gini_{青年、中年}年龄=\frac{D1}{D}Gini(D1)+\frac{D2}{D}Gini(D1)=\frac{10}{15}*(1-\frac{5}{10}^2-\frac{5}{10}^2)+\frac{5}{15}*(1-\frac{3}{5}^2-\frac{2}{5}^2)Gini青年、中年年龄=DD1Gini(D1)+DD2Gini(D1)=1510∗(1−1052−1052)+155∗(1−532−522)
同理可以计算出其他有效子集的基尼指数,以及其他特征的所有有效子集的基尼指数。选择其中最小的值的特征作为根节点,该特征下有效子集最小的子集作为最优的有效子集,递归构建CART决策树。CART对连续值的处理与C4.5一样,也是排序之后每两个值之间取一个中间值来进行数据分割。
对于回归树而言,评价纯度的标准是方差:
σ=∑(xi−μ)2\sigma=\sqrt{\sum(x_i-\mu)^2}σ=∑(xi−μ)2
Gain=∑σiGain = \sum\sigma_iGain=∑σi
方差越小,纯度越高,数据越集中,预测值越准确。
CART剪枝采用的是CCP剪枝算算法(自底向上),需要验证集,后剪枝算法
Cost-Complexity Pruning(CCP,代价复杂度剪枝)
定义一棵树的损失为:
La(T)=C(T)+a丨T丨L_a(T)=C(T)+a丨T丨La(T)=C(T)+a丨T丨
C(T)C(T)C(T)为训练误差,aaa为可调节参数,丨T丨丨T丨丨T丨为树的规模(子节点数目)
可以看出当aaa越大的时候,树的规模越小,aaa越小,树的规模越大
定义单节点ttt的损失为:
La(t)=C(t)+aL_a(t)=C(t)+aLa(t)=C(t)+a
定义以ttt为根节点的子树损失为:
La(Tt)=C(Tt)+a丨Tt丨L_a(T_t)=C(T_t)+a丨T_t丨La(Tt)=C(Tt)+a丨Tt丨
令La(t)=La(Tt)L_a(t)=L_a(T_t)La(t)=La(Tt)可得a=C(T)−C(Tt)∣Tt∣−1a=\frac{C(T)-C(T_t)}{|T_t|-1}a=∣Tt∣−1C(T)−C(Tt)
回归问题中训练误差可以使用均方误差
分类问题中训练误差的计算:
C(T)=r(t)∗p(t)C(T)=r(t)*p(t)C(T)=r(t)∗p(t),r(t)r(t)r(t)是该根节点的错误率,p(t)p(t)p(t)是该根节点数据量占比
C(Tt)=∑imri(t)∗pi(t)C(T_t)=\sum_i^mr_i(t)*p_i(t)C(Tt)=∑imri(t)∗pi(t),ri(t)r_i(t)ri(t)是以t为根节点的子树的叶子节点iii的错误率,pi(t)p_i(t)pi(t)是以ttt为根节点的子树的叶子节点iii的数据量占比
此时单节点ttt与子树TtTtTt具有相同的损失,可以进行剪枝。
定义节点t剪枝后的损失程度为:
g(t)=C(T)−C(Tt)∣Tt∣−1g(t) = \frac{C(T)-C(T_t)}{|T_t|-1}g(t)=∣Tt∣−1C(T)−C(Tt)
剪枝的流程如下:
对于输入的决策树T0T_0T0,计算所有内部节点的损失程度,可以得到g(t)0,g(t)1,g(t)2.....{g(t)_0,g(t)_1,g(t)_2}.....g(t)0,g(t)1,g(t)2.....选择其中最小的进行剪枝,得到T1T_1T1,再计算T1T_1T1所有的内部节点的损失程度,根据上边的方法,同样选择g(t)g(t)g(t)最小的节点ttt进行剪枝,得到T2,
知道TnT_nTn为单节点。得到一系列的次最优子树{T0,T1,T2......TnT_0,T_1,T_2......T_nT0,T1,T2......Tn},在验证集验证这些次最优子树,进而选择出最优子树。

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









