







🧑 博主简介:优快云博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c=1000,移动端可微信小程序搜索“历代文学”)总架构师,
15年工作经验,精通Java编程,高并发设计,Springboot和微服务,熟悉Linux,ESXI虚拟化以及云原生Docker和K8s,热衷于探索科技的边界,并将理论知识转化为实际应用。保持对新技术的好奇心,乐于分享所学,希望通过我的实践经历和见解,启发他人的创新思维。在这里,我希望能与志同道合的朋友交流探讨,共同进步,一起在技术的世界里不断学习成长。
技术合作请加本人wx(注明来自csdn):foreast_sea

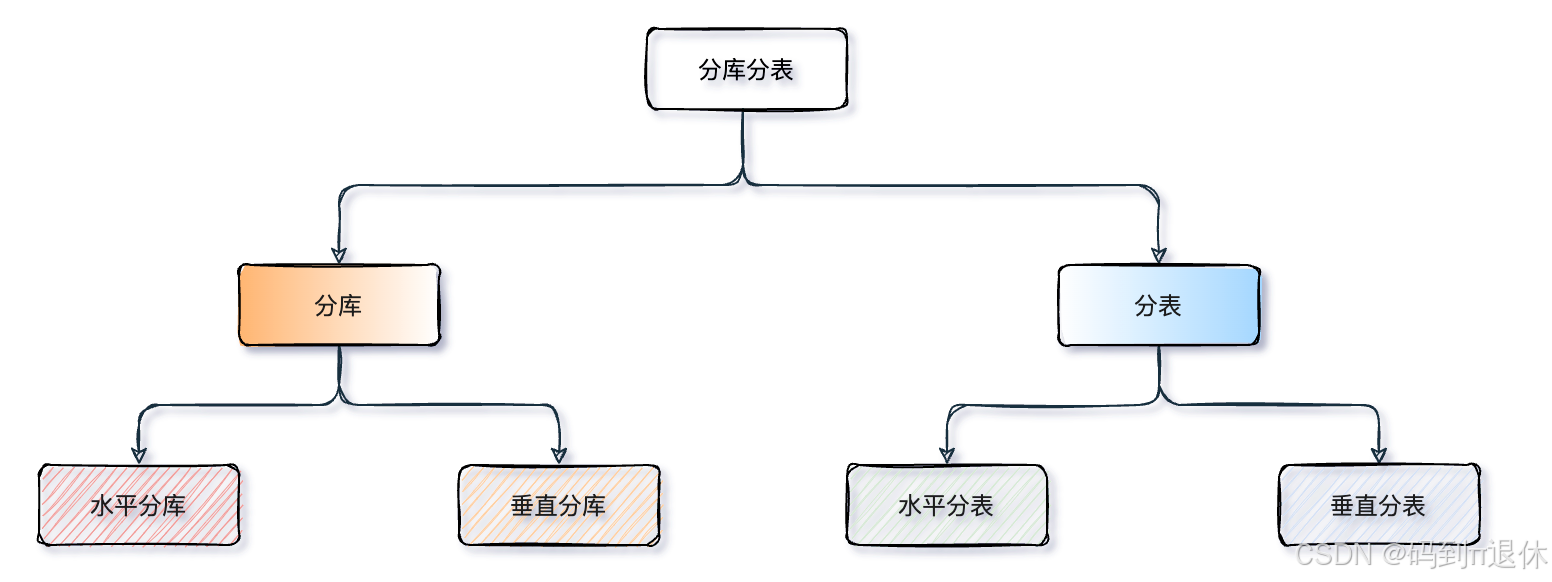
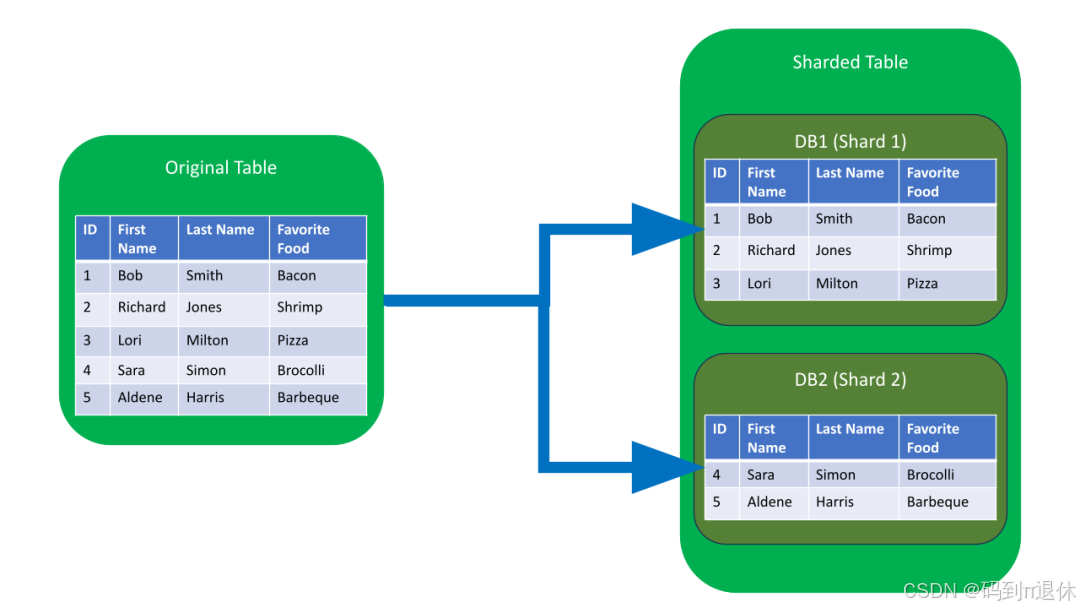
分库分表这么麻烦,为何各大数据库不默认封装进去?
引言
在数字化浪潮的推动下,数据规模正以指数级速度膨胀,从百万级到百亿级的数据表,似乎只是许多业务系统在短短几年内必经的技术跃迁。面对海量数据的存储与查询需求,“分库分表”这一看似简单粗暴的解决方案,却成为无数工程师的“必修课”。然而,一个令人费解的悖论始终萦绕在技术演进的道路上:为何数据库作为数据管理的核心基础设施,至今仍需开发者手动处理分库分表的复杂性,而不能像管理单机表一样“透明”地屏蔽分布式细节?
这一问题的答案,远非“技术不够成熟”可以概括。事实上,从早期的MySQL分片中间件,到如今的NewSQL数据库(如TiDB、CockroachDB),再到云厂商的托管式分布式服务(如AWS Aurora),行业从未停止对“透明分片”的探索。然而,这些尝试往往在落地时遭遇“理想丰满、现实骨感”的困境——或是因性能损耗被迫妥协,或是因业务适配性不足而沦为小众方案。其本质矛盾在于,分库分表并非单纯的存储层扩展问题,而是一场对数据哲学的重构。
在单机数据库中,数据的“位置”是天然确定的——所有记录共享同一份锁机制、同一棵B+树索引、同一块磁盘空间。而一旦进入分布式领域,数据被物理分散到多个节点,其读写逻辑便与业务语义深度耦合:用户的一次查询可能需要穿透多个分片,一笔交易可能涉及跨节点的状态同步,一条索引的更新可能触发全局一致性挑战。这种耦合性使得数据库无法像抽象“事务”或“索引”那样,将分片逻辑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 576
576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











