




一起来用tf.data API!(2)——创建迭代器读取数据
(一)前 言
(二)单次迭代器
(三)可初始化迭代器
(四)可重新初始化迭代器
(五)可馈送迭代器
(六)消耗迭代器中的值
(七)保存迭代器的状态
(八)总 结
(一)前 言
在第一节中我们介绍了tf.data API的组件结构,我们使用Dataset方法来创建数据集,然后使用Iterator来读取数据集中的元素,本节我们就来介绍如何用Iterator方法。目前tf.data API 目前支持下列迭代器,复杂程度逐渐增大:
- 单次迭代器
- 可初始化迭代器
- 可重新初始化迭代器
- 可馈送迭代器
(二)单次迭代器
单次迭代器是最简单的迭代器形式,仅支持对数据集进行一次迭代,不需要显式初始化。单次迭代器可以处理基于队列的现有输入管道支持的几乎所有情况,但它们不支持参数化。以 Dataset.range() 为例:
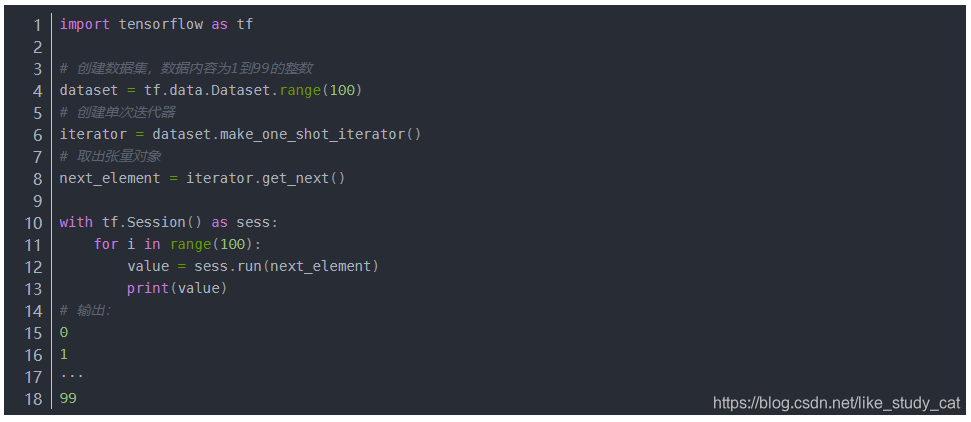 注意:只能在会话中才能读取数据集中的元素
注意:只能在会话中才能读取数据集中的元素
(三)可初始化迭代器
我们需要先进行迭代器的初始化操作,然后才能使用可初始化迭代器。同时,我们可以使用一个或多个 tf.placeholder() 张量(可在初始化迭代器时馈送)参数化数据集的定义。继续以 Dataset.range() 为例:
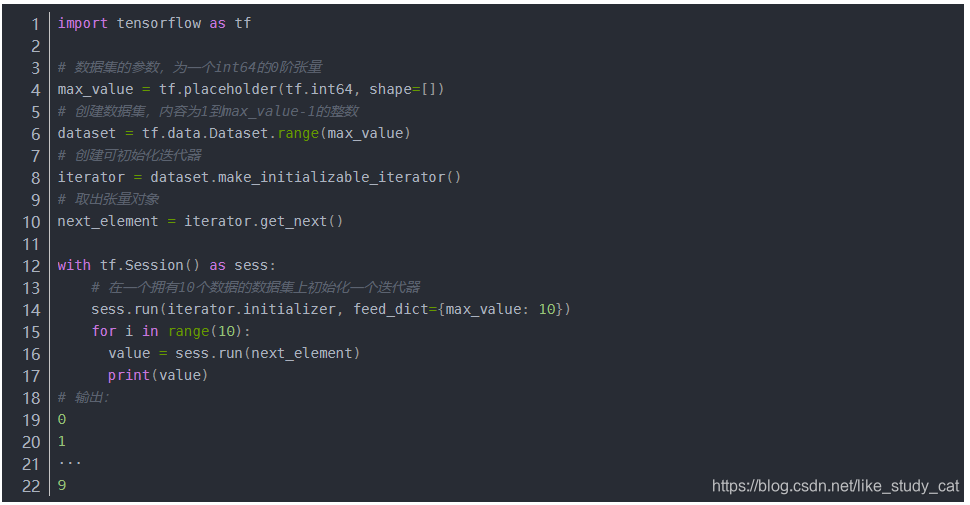
(四)可重新初始化迭代器
可重新初始化迭代器可以通过多个不同的 Dataset 对象进行初始化。如果我们有一个训练输入管道,它会对输入图片进行随机扰动来改善泛化性能;还有一个验证输入管道,它会评估对未修改数据的预测。这些管道通常会使用不同的 Dataset 对象,这些对象具有相同的结构(即每个组件具有相同类型和兼容形状)。通过以下代码来讲解可重新初始化迭代器:
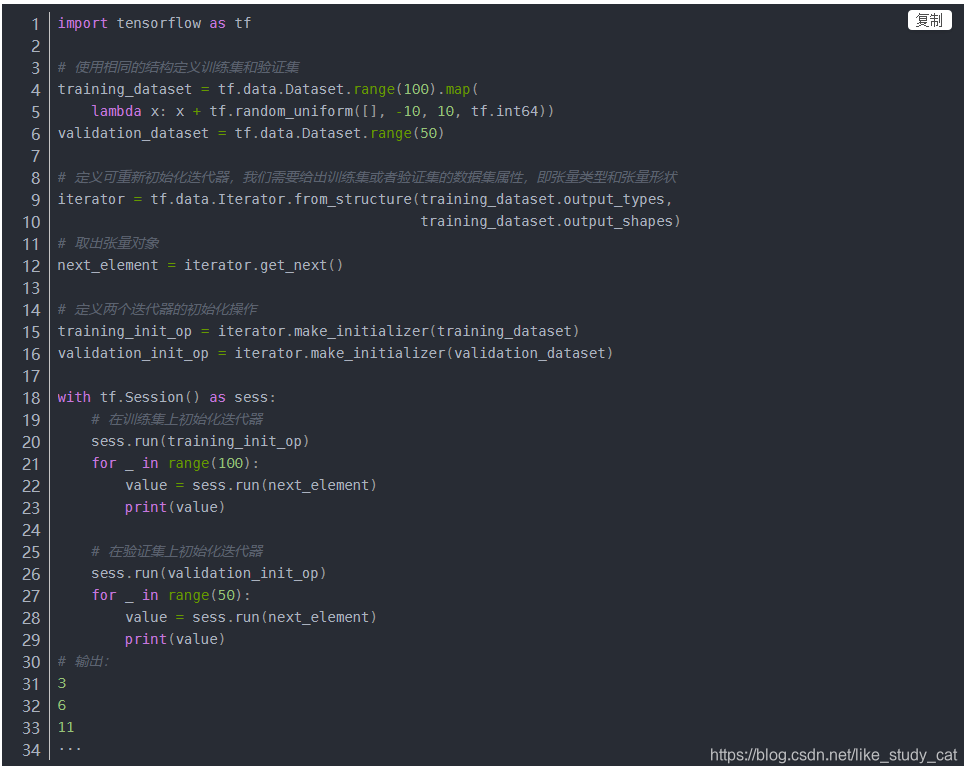
(五)可喂(feedable)迭代器
可馈送迭代器可以与 tf.placeholder 一起使用,通过熟悉的 feed_dict 机制选择每次调用 tf.Session.run 时所使用的 Iterator。它提供的功能与可重新初始化迭代器的相同,但在迭代器之间切换时不需要从数据集的开头初始化迭代器。例如,以上面的同一训练和验证数据集为例,我们可以使用 tf.data.Iterator.from_string_handle 定义一个可让在两个数据集之间切换的可馈送迭代器:
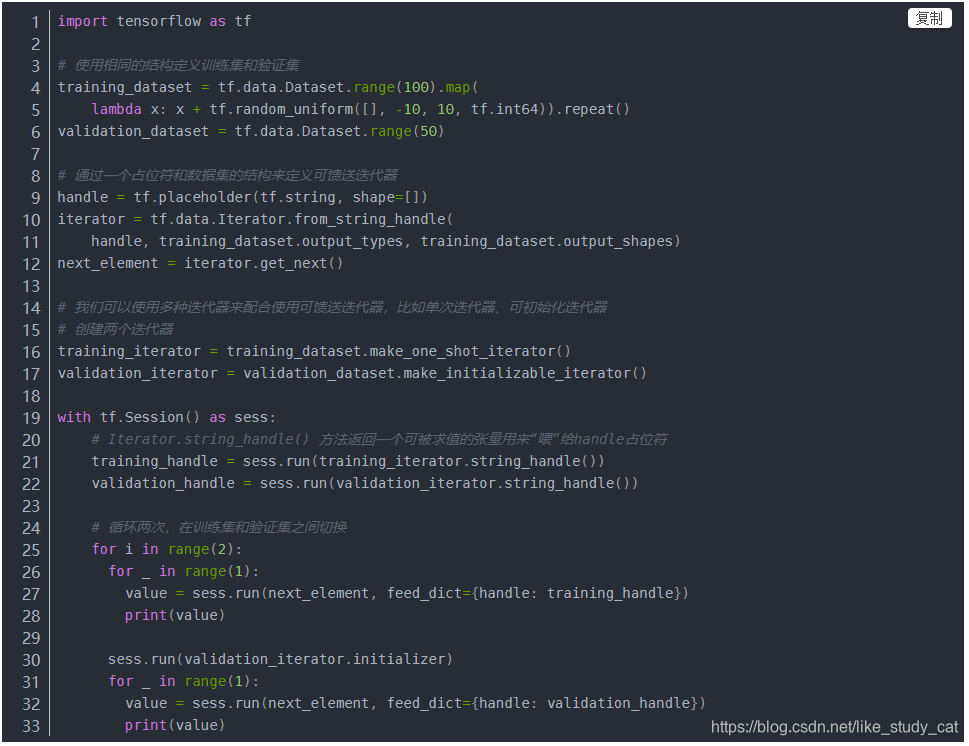
(六)消耗迭代器中的值
Iterator.get_next() 方法返回一个或多个张量对象,这些对象对应于迭代器有符号的下一个元素。每次评估这些张量时,它们都会获取底层数据集中下一个元素的值。如果迭代器到达数据集的末尾,则执行 Iterator.get_next() 操作会产生tf.errors.OutOfRangeError。在此之后,迭代器将处于不可用状态;如果需要继续使用,则必须对其重新初始化。一种常见模式是将“训练循环”封装在 try-except 块中:

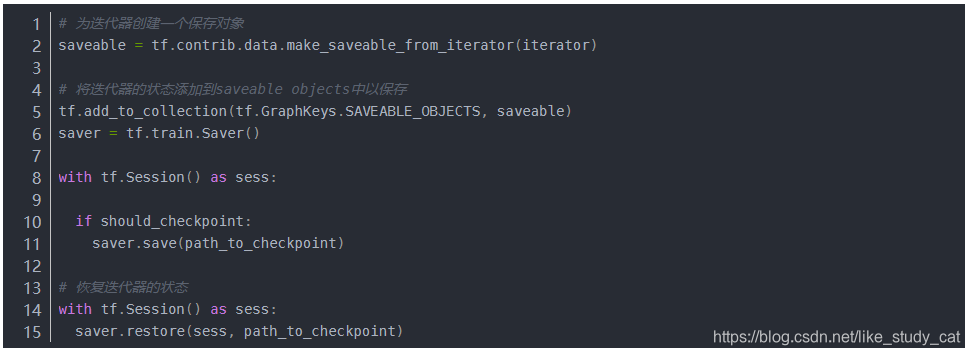
(七)保存迭代器的状态
我们可以使用tf.contrib.data.make_saveable_from_iterator 函数通过迭代器创建一个 SaveableObject,该对象可用于保存和恢复迭代器(实际上是整个输入管道)的当前状态。这样创建的可保存对象可以添加到 tf.train.Saver 变量列表或 tf.GraphKeys.SAVEABLE_OBJECTS 集合,以便采用与 tf.Variable 相同的方式进行保存和恢复。
(八)总 结
在本节中,我们介绍了迭代器的类型、各类型迭代器的创建、使用和保存方式,在下一节我们将开始介绍TFRecords的相关原理和使用方法,并尝试使用图像数据创建TFRecords文件,有任何疑问请在评论区留言,我会尽快回复,谢谢支持!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









