






最近小强接了一个需求,要对集合做各种操作,比如统计集合的数据个数,计算集合的交集,并集等,我看小强拿着代码各种for,if , else嵌套,经常加班,最后的结果还不一定对,我实在看不下去了,必须告诉他一些好用的工具类,比如最常用的guava。

1.背景
平时我们都会封装一些处理缓存或其他的小工具。但每个人都封装一次,重复造轮子,有点费时间,最关键的问题是如果造的轮子有问题,那将是整个项目的灾难,今天给大家引入一中java工具类guava,它是谷歌基于java封装好的开源库,它的性能、实用性,比我们自己造的轮子更好。
它的优势主要体现在下面两个方面:
- Guava提供了许多高级集合类型,如Multiset、Multimap、BiMap和Table,这些类型扩展了Java标准库中的基础集合,使得开发者能够更方便地处理复杂的数据结构。
- Guava还提供了实用的集合工具类,如Iterables、Maps、Sets等,这些工具类提供了许多有用的静态方法,用于简化集合的创建、遍历、转换和过滤等操作
接下来我们从实战角度看下这些最常用的工具类到底该如何使用!!
2.maven引入
<!--guava工具类 -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.3-jre</version>
</dependency>
3.代码搞起来
- Multiset实现集合个数统计
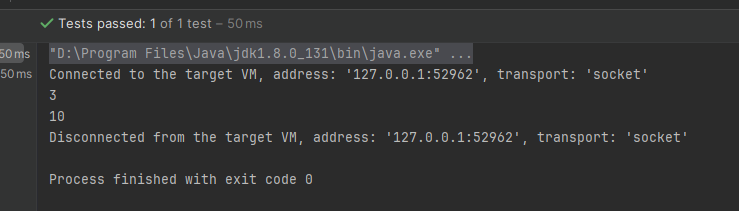
@Test
public void testMultiset() {
List<String> words = Arrays.asList("张三", "李四", "张三", "王五", "张三", "李四");
// 创建Multiset
Multiset<String> nameMultiset = HashMultiset.create();
nameMultiset.addAll(words);
// 查询张三重复次数
System.out.println(nameMultiset.count("张三"));
// 给李四设置固定的次数
nameMultiset.setCount("李四", 10);
System.out.println(nameMultiset.count("李四"));
}
执行结果
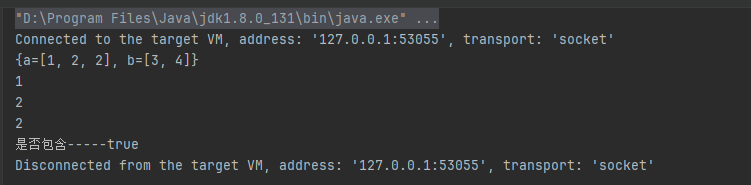
- ArrayListMultimap可以放入重复key,并且会把key相同的value放到List集合
@Test
public void testMultimap() {
ArrayListMultimap<String, Integer> multimap = ArrayListMultimap.create();
multimap.put("a", 1);
multimap.put("a", 2);
multimap.put("a", 2);
multimap.put("b", 3);
multimap.put("b", 4);
System.out.println(multimap); // {a=[1, 2, 2], b=[3, 4]}
// 转为map :Map<K, Collection<V>>
Map<String, Collection<Integer>> map = multimap.asMap();
// 返回一个集合
List<Integer> aList = multimap.get("a");
aList.forEach(System.out::println);
// 是否包含
System.out.println("是否包含-----"+map.containsKey("a"));
}
执行结果
- HashBiMap既可以按照key取,也可以按照value取
@Test
public void testBiMap() {
HashBiMap<String, Integer> biMap = HashBiMap.create();
biMap.put("apple", 1);
biMap.put("banana", 2);
biMap.put("cherry", 3);
Integer apple = biMap.get("apple");
System.out.println("apple对应的key为------" + apple);
String s = biMap.inverse().get(2);
System.out.println("2对应的value为------" + s);
}
执行结果

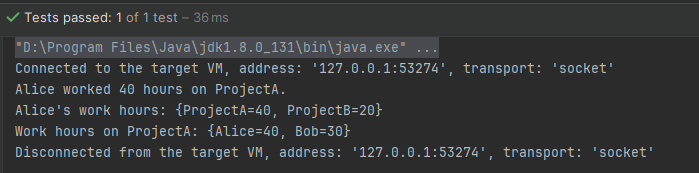
- Table是一种特殊的数据结构,它允许你使用两个键(通常被称为行键和列键)来映射一个值。你可以将Table视为一个二维的Map, 其中每个单元格都由行键和列键唯一确定,并存储一个值。
@Test
public void testTable() {
// 创建一个Table实例
Table<String, String, Integer> workHoursTable = HashBasedTable.create();
// 添加数据
workHoursTable.put("Alice", "ProjectA", 40);
workHoursTable.put("Bob", "ProjectA", 30);
workHoursTable.put("Alice", "ProjectB", 20);
workHoursTable.put("Charlie", "ProjectC", 50);
// 检索数据
Integer aliceProjectAHours = workHoursTable.get("Alice", "ProjectA");
System.out.println("Alice worked " + aliceProjectAHours + " hours on ProjectA.");
// 使用row()方法获取特定行的映射
Map<String, Integer> aliceWorkHours = workHoursTable.row("Alice");
System.out.println("Alice's work hours: " + aliceWorkHours);
// 使用column()方法获取特定列的映射
Map<String, Integer> projectAWorkHours = workHoursTable.column("ProjectA");
System.out.println("Work hours on ProjectA: " + projectAWorkHours);
}
直接结果
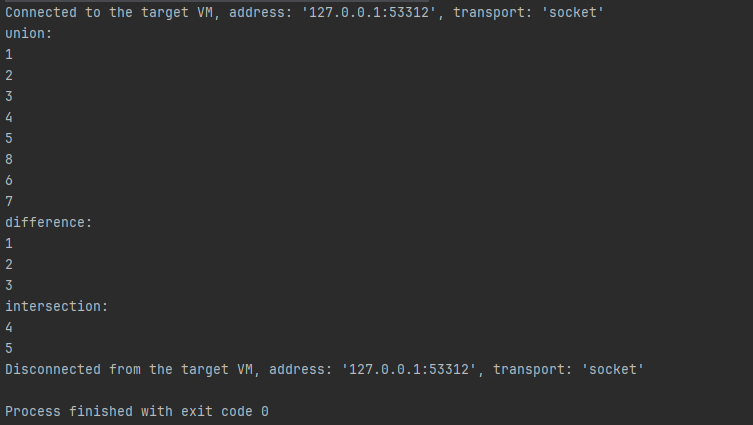
- 集合的交集,并集和差集
@Test
public void testSets() {
HashSet<Integer> setA = Sets.newHashSet(1, 2, 3, 4, 5);
HashSet<Integer> setB = Sets.newHashSet(4, 5, 6, 7, 8);
Sets.SetView<Integer> union = Sets.union(setA, setB);
System.out.println("union:");
for (Integer integer : union)
System.out.println(integer); //union 并集:12345867
Sets.SetView<Integer> difference = Sets.difference(setA, setB);
System.out.println("difference:");
for (Integer integer : difference)
System.out.println(integer); //difference 差集:123
Sets.SetView<Integer> intersection = Sets.intersection(setA, setB);
System.out.println("intersection:");
for (Integer integer : intersection)
System.out.println(integer); //intersection 交集:45
}
执行结果
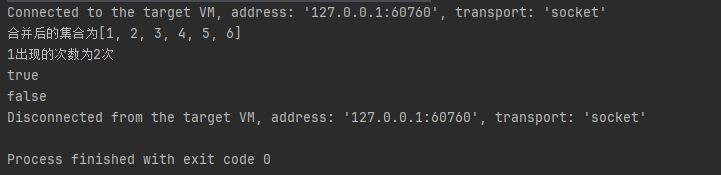
- Iterables使用
@Test
public void testIterables() {
//concat()合并多个集合,成为统一的一个可迭代集合
Iterable<Integer> iterable = Iterables.concat(Ints.asList(1, 2, 3), Ints.asList(4, 5, 6));
System.out.println("合并后的集合为" + iterable);
//frequency()返回对象在iterable中出现的次数
int frequency = Iterables.frequency(Ints.asList(1, 1, 2, 3, 4, 5), 1);
System.out.println("1出现的次数为" + frequency + "次");
//elementsEqual(Iterable,Iterable)如果两个iterable中的所有元素相等且顺序一致,返回true
boolean b = Iterables.elementsEqual(Ints.asList(1, 2, 3), Ints.asList(1, 2, 3));
System.out.println(b);//true
boolean b1 = Iterables.elementsEqual(Ints.asList(1, 3, 2), Ints.asList(1, 2, 3));
System.out.println(b1);//false
}
执行结果
- Lists的使用
@Test
public void testLists() {
//reverse(List)返回给定List的反转视图
List<Integer> integers = Ints.asList(1, 2, 3, 4, 5);
List<Integer> reverse = Lists.reverse(integers);
System.out.println(reverse);//[5, 4, 3, 2, 1]
//partition(List,int) 把List按指定大小分割
int frequency = Iterables.frequency(Ints.asList(1, 1, 2, 3, 4, 5), 1);
System.out.println("1出现的次数为" + frequency + "次");
List<List<Integer>> partition = Lists.partition(reverse, 2);
System.out.println(partition);//[[5, 4], [3, 2], [1]]
}

















 6080
6080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









