



 本文探讨了数据库性能优化中的数据扫描瓶颈问题,提出了四种解决方案:列存储、Index Only Scan、MPP架构和Hyperloglog预估值计算。通过人大金仓的MPP数据库KADB实例,展示了这些优化技术的实际应用和效果,为数据库性能提升提供了有效策略。
本文探讨了数据库性能优化中的数据扫描瓶颈问题,提出了四种解决方案:列存储、Index Only Scan、MPP架构和Hyperloglog预估值计算。通过人大金仓的MPP数据库KADB实例,展示了这些优化技术的实际应用和效果,为数据库性能提升提供了有效策略。
大多数用户在体验数据库时,接触到的最早的sql语句就是count(),因此用户判断数据库性能时通常也会通过count()进行比较。但在执行时通常会出现一个问题:对某个表做count(*)时需对全表数据进行扫描,当表中包含数据量较大的字段时,IO将会成为数据扫描的瓶颈。
数据扫描瓶颈有哪些优化方式?
针对上述问题,为解决全表扫描带来的IO开销的方案大致可分为三类:第一类是减少扫描数据;第二类是通过并行方式扫描数据;第三类是通过预估值计算方式获取结果。根据上述三种方案,我们给出以下四种优化方式:
1、减少扫描数据
(1)使用列存
顾名思义,列存是按列存储的。当使用count()查询时,只需要扫描一列数据做count统计,而并非全表,这样,IO开销几乎是行存的1/列数,即效率是行存的列数倍。在实际使用中,因为每列字段长度的原因,使用列存时count()效率往往要比这个值还要高得多。
(2)使用Index only scan
使用主键的Index only scan,count(*)仅需扫描主键的索引链表即可,不必扫描所有的数据块,以此可大大减少IO开销。
2、并行扫描数据
(1)MPP架构
使用MPP架构的好处是让数据分布到各个计算节点上。这样,在使用count(*)查询时,每个计算节点都会去统计该节点的数据量,最终汇聚返回总的数据量,这种方式可以更好地利用CPU和磁盘达到并行扫描的效果,节省扫描时间。
3、预估值计算
(1)Hyperloglog
HyperLogLog算法来源于论文《HyperLogLog the analysis of a near-optimal cardinality estimation algorithm》,可以使用固定大小的字节计算任意大小的distinct value。由于HLL是概率计算算法,它依赖于数据的均匀分布,在使用时往往需要我们首先利用HLL对每个元素进行哈希,以使数据分布更加均匀。因此,任何可以哈希的数据类型都可以使用HLL算法做统计估算,HLL算法在数据库的估值统计计算方面起到了重要作用。
哪些产品能提供具体优化方案?
综合上述4种优化方式,人大金仓悉心打造的MPP数据库KADB具备以上所有特性方案,具体包括:
a) 列存
KADB支持可压缩列存储,压缩比可达1:10。建表语句如下:
create table t_count(id int, day date, sale numeric) with
(appendonly=true,orientation=column,compresstype=zlib,compresslevel=5);
b) Index only scan
KADB支持index only scan,执行计划如下:
explain select count(*) from t_count ;
QUERY PLAN
Aggregate (cost=17403254.38…17403254.39 rows=1 width=8)
-> Gather Motion 8:1 (slice1; segments: 8) (cost=17403254.27…17403254.37 rows=1 width=8)
-> Aggregate (cost=17403254.27…17403254.28 rows=1 width=8)
-> Index Only Scan using idx_t_count_id on t_count (cost=0.19…17153253.65 rows=12500031 width=0)
c) MPP架构
KADB是人大金仓基于Kingbase ES 单机数据库打造的MPP数据库,具有一切皆并行的特点。
d) Hyperloglog
KADB集成了HLL插件。具体操作如下:
创建HLL扩展:
create extension hll;
创建计数表,并插入1亿条数据,id列重复值较少:
create table t_count(id int, day date, sale numeric);
insert into t_count
select
a,
current_date - (random()*1095)::integer * ‘1 day’::interval,
random() * 10000 + 500
from
generate_series(1, 100000000) as a;
创建HLL统计表,记录按天维度的唯一值:
create table daily_id_hll
as select
day,
hll_add_agg(hll_hash_integer(id))
from
t_count
group by 1;
最终通过HLL算法预估出t_count的条数
select hll_cardinality(hll_union_agg(hll_add_agg)) from daily_id_hll;
hll_cardinality
101484331.466222
(1 row)
MPP数据库KADB优化效果如何?
在此,我们导入1亿条数据进行测试,数据总量大小为203GB,测试count()比对效率如下:
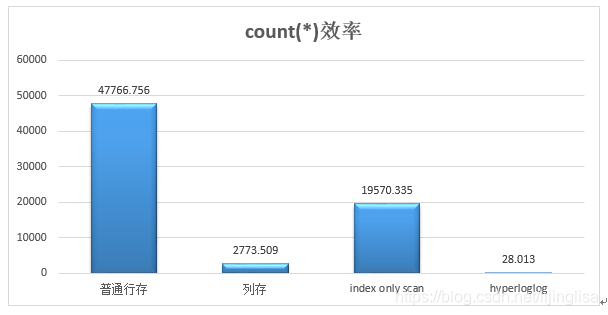
综上总述,KADB具备以上所有优化方式的解决方案能力,可根据不同需求优化count()查询。在用户实际应用场景中,面对实时性要求较高但准确度要求不太高的数据可视化服务,我们通常提供Hyperloglog优化方案;面对实时性要求不太高但准确度要求高的统计服务,我们通常提供列存优化方案。


















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









