







 线上微服务容器CPU达到200%,通过排查发现java进程占用100%。通过jstack分析发现DubboSaveRegistryCache-thread-1线程处于死循环,因存储.lock缓存文件失败导致。问题根源在于磁盘空间满,Dubbo默认缓存路径在/root目录。解决方案包括扩展磁盘空间或改变Dubbo缓存路径,以及调整RocketMQ日志输出目录避免占用过多空间。
线上微服务容器CPU达到200%,通过排查发现java进程占用100%。通过jstack分析发现DubboSaveRegistryCache-thread-1线程处于死循环,因存储.lock缓存文件失败导致。问题根源在于磁盘空间满,Dubbo默认缓存路径在/root目录。解决方案包括扩展磁盘空间或改变Dubbo缓存路径,以及调整RocketMQ日志输出目录避免占用过多空间。
声明:本内容为本人工作中亲身经历事件,并非模拟、测试案例。
问题描述
线上发现某微服务所在容器CPU爆满,达到200%,之所以是200%是因为此微服务容器共部署2台集群,而通过在宿主机上查看的占用情况,就会发现2个容器共占比达200%(容器是通过比例占用宿主机资源),此时不论进入到哪个微服务容器使用top命令,都能看到对应的java进程占用已达到100%,如下图:
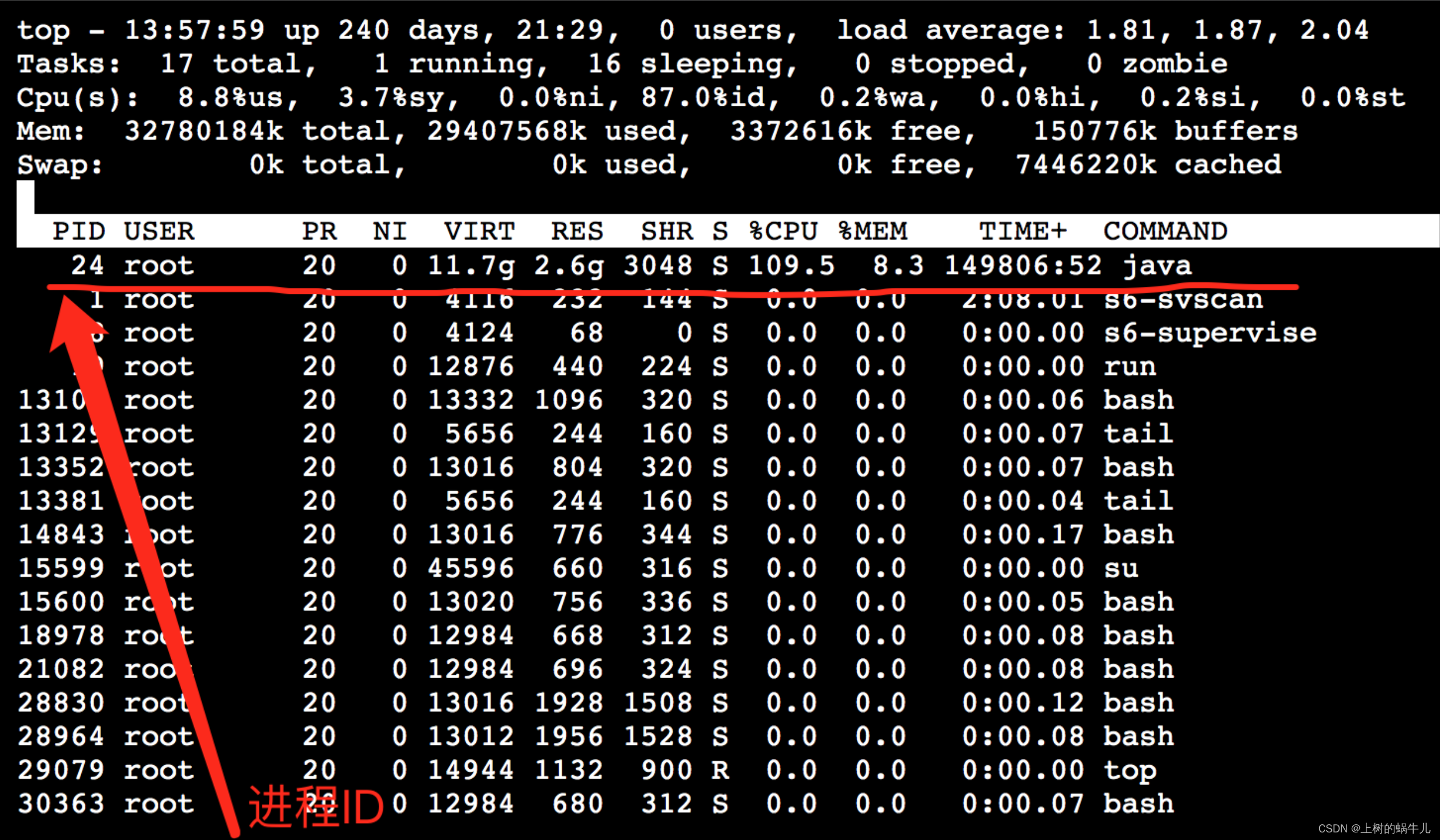
查到进程
查到进程ID后,可以进一步查询进程中究竟哪个线程占用CPU过高,使用命令 top -H -p24
# 使用命令
top -H -p24
获得进程ID为24的线程数据,如下图:
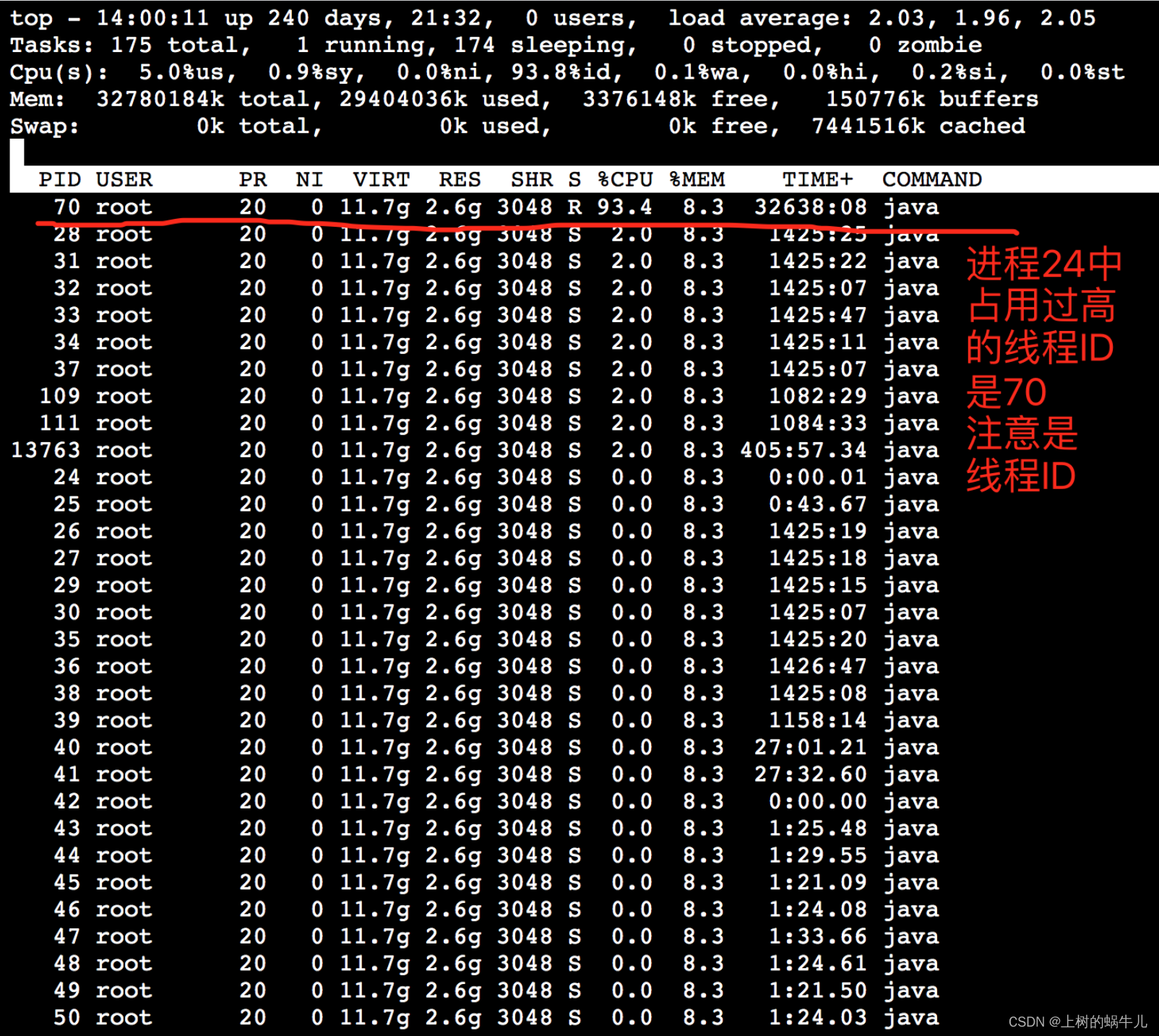
查看进程堆栈信息
那么接下来的思路:目前得到了主进程ID=24,也获取了主进程中线程ID=70的CPU占用过高,那么通过查看进程的堆栈信息,从中找到线程70的日志信息,再具体分析问题所在。
注意:由于通过jstack命令只能打印出/导出进程的堆栈信息,所以我们需要从中找到线程ID=70的日志
我们先通过命令导出进程堆栈信息
# 使用命令
jstack 24
当然也可以通过管道把线程ID=70的信息过滤出来
但是注意,堆栈信息中的线程ID值使用的是16进制显示,堆栈信息中会用nid=0x46来显示,即nid的值就是线程ID的16进制,所以需要先通过命令 printf “%x\n” 70 来将70转换成16进制 ,结果是46,最终需要使用命令
jstack 24 | grep ’nid=0x46’
来截取线程ID=70的堆栈信息,结果如下:

堆栈详细内容如下:
"DubboSaveRegistryCache-thread-1" #34 daemon prio=5 os_prio=0 tid=0x00007f19491ad800 nid=0x46 runnable [0x00007f18a37fc000]
java.lang.Thread.State: RUNNABLE
at java.io.FileOutputStream.writeBytes(Native Method)
at java.io.FileOutputStream.write(FileOutputStream.java:326)
at sun.nio.cs.StreamEncoder.writeBytes(StreamEncoder.java:221)
at sun.nio.cs.StreamEncoder.implWrite(StreamEncoder.java:282)
at sun.nio.cs.StreamEncoder.write(StreamEncoder.java:125)
- locked <0x00000000f5eb46a0> (a java.io.OutputStreamWriter)
at java.io.OutputStreamWriter.write(OutputStreamWriter.java:207)
at java.io.BufferedWriter.flushBuffer(BufferedWriter.java:129)
- locked <0x00000000f5eb46a0> (a java.io.OutputStreamWriter)
at java.io.BufferedWriter.write(BufferedWriter.java:230)
- locked <0x00000000f5eb46a0> (a java.io.OutputStreamWriter)
at java.io.Writer.write(Writer.java:157)
at java.util.Properties.store0(Properties.java:840)
- locked <0x00000000810c7ed8> (a java.util.Properties)
at java.util.Properties.store(Properties.java:818)
at com.alibaba.dubbo.registry.support.AbstractRegistry.doSaveProperties(AbstractRegistry.java:187)
at com.alibaba.dubbo.registry.support.AbstractRegistry$SaveProperties.run(AbstractRegistry.java:534)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
分析堆栈信息
初步分析:DubboSaveRegistryCache-thread-1该线程处于运行状态RUNNABLE,且占用CPU过高,通过堆栈信息可看到由dubbo如下代码引起:
at com.alibaba.dubbo.registry.support.AbstractRegistry.doSaveProperties(AbstractRegistry.java:187)
at com.alibaba.dubbo.registry.support.AbstractRegistry$SaveProperties.run(AbstractRegistry.java:534)
查看问题源码
此时我们知道引起的原因,结合我们实际使用场景,基本能大致定位问题的所在,不过为了追根究底我们可以继续查看一下引发问题的源码,此处我们继续查看一下dubbo的源码:注意查看源码一定要查看当前项目中使用的dubbo的版本。
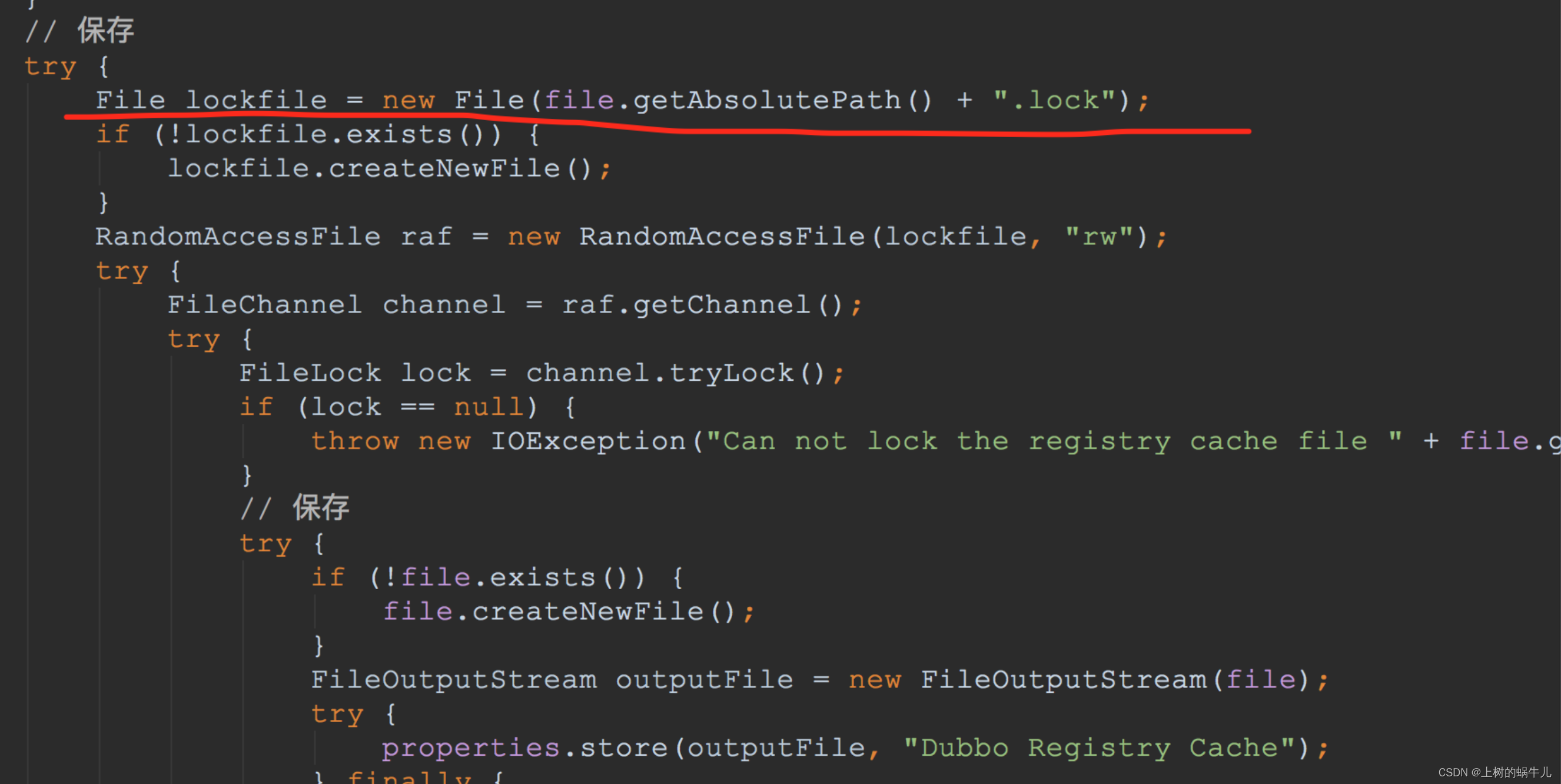

通过源码,我们初步分析应该是存储.lock本地缓存文件时报错,被catch后继续循环保存,即进入死循环,通过我们线上阿里云日志中对业务日志的打印情况也能确认,我们的业务日志并没有打印出来,因为死循环后执行不到打日志的代码语句。
定位问题
定位到问题后,知道为什么cpu占用过高的原因了,那么为什么会写入缓存文件失败呢?
通过查看业务代码发现我们的微服务工程并没有指定registry cache file的路径,那么会使用默认路径,通过源码发现默认使用如下路径:
String filename = url.getParameter(Constants.FILE_KEY, System.getProperty("user.home") + "/.dubbo/dubbo-registry-" + url.getParameter(Constants.APPLICATION_KEY) + "-" + url.getAddress() + ".cache");
因为容器用的root账户启动的服务,所以user.home对应的是/root用户目录,即/root/.dubbo/dubbo-registry-...为存储目录,那么为什么失败呢?
首先怀疑目录权限问题 或 存储空间打满问题
进入容器查看目录:cd /root, du -h 如下:
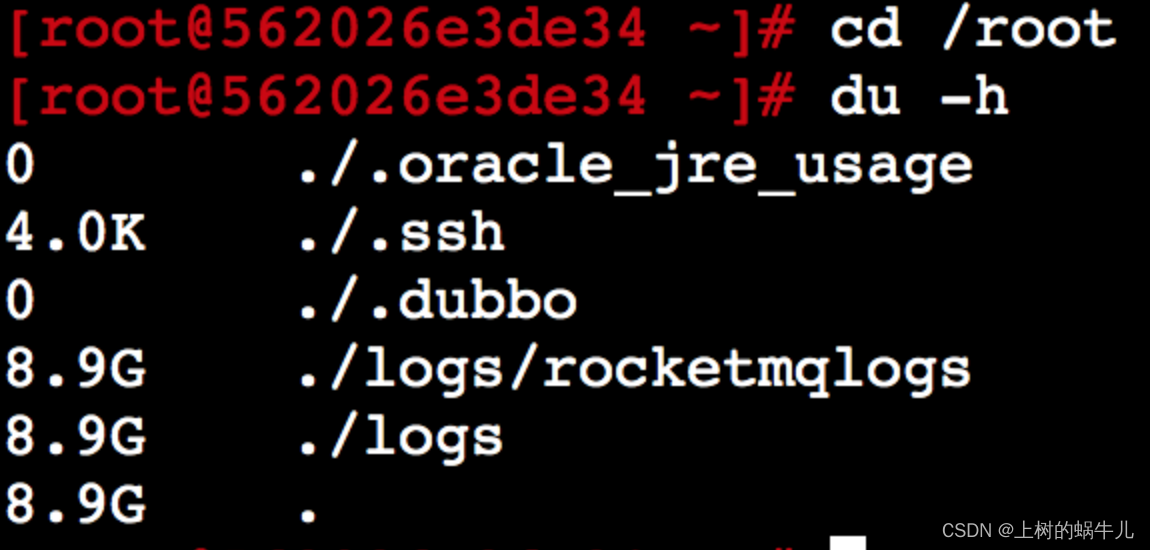
由图可知,dubbo缓存确实在/root下,但是大小是0字节,说明没存成功,/root目录权限应该不会有问题,那么就是磁盘空间问题?
使用命令df查看下全部系统磁盘情况:
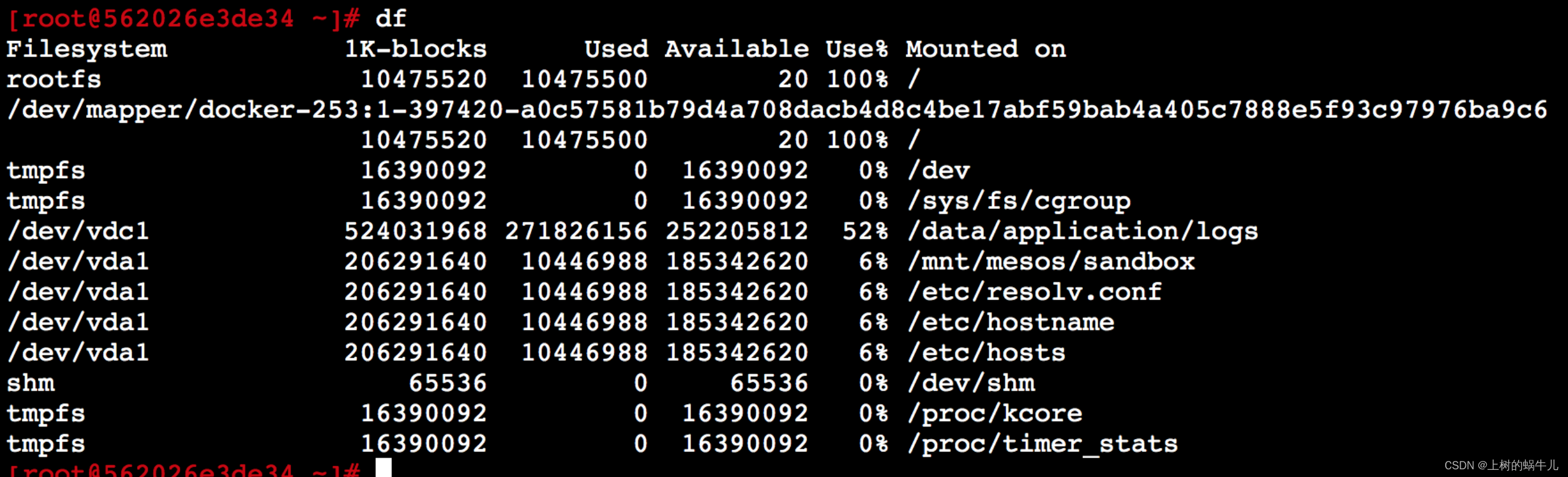
由图发现上边的2个磁盘是100%打满了,那么在确定下是不是/root目录挂载到了这2个磁盘中的一个就可以了。
# 使用命令
df -h /root

由图可知,/root目录正是挂载到了如下磁盘或叫文件系统下,而该磁盘已用尽,所以无法保存。
/dev/mapper/docker-253:1-397420-a0c57581b79d4a708dacb4d8c4be17abf59bab4a405c7888e5f93c97976ba9c6
至此问题已确定,有2种解决方法,如下:
- 扩展如下磁盘大小
/dev/mapper/docker-253:1-397420-a0c57581b79d4a708dacb4d8c4be17abf59bab4a405c7888e5f93c97976ba9c6- 更改dubbo.registry.file缓存文件存储目录
问题真解决了吗?
我们再来看一下/root目录的占用情况
我们发现虽然dubbo注册信息保存到这里失败了,那么引起这个目录打满的原因其实是logs文件件太大导致的,而logs目录中保存的是rocketmqlogs目录,该目录正是rocketmq的默认日志输出目录,那他应该输出到/root目录吗?
显而易见,rocketmq的日志应该存放到我们业务日志目录,通过docker磁盘映射到专门收集日志的文件系统,这样我们自己如果有ELK或阿里云日志等日志收集系统才能采集到mq的日志,所以我们项目集成rocketmq的时候一定要规划好它的日志输出目录,尽量不要使用他的默认目录,否则在k8s环境下很容易导致我们这里遇到的目录打满等莫名其妙的问题。
最终解决方案
当然至此,我们在微服务项目中修改一下rocketmq的日志输出目录就可以了,然后把/root中目前已存在的rocketmq日志移走或删除即可。至于怎么取修改rocketmq的默认日志输出目录,大家可以到rocketmq官网查看,比较简单,此处就不再赘述了。


















 5297
5297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











