







概念:
进程是操作系统中执行的一个程序,操作系统以进程为单位分配存储空间,每个进程都要自己的地址空间。Python既支持多进程又支持多线程,因此使用Python实现并发编程主要有3种方式:多进程、多线程、多进程+多线程。
| 区别 | 进程 | 线程 |
|---|---|---|
| 根本区别 | 作为资源分配的单位 | 调度和执行的单位 |
| 开销 | 每一个进程都有独立的代码和数据空间,进程间的切换会有较大的开销 | 线程可以看出是轻量级的进程,多个线程共享内存,线程切换的开销小 |
| 所处环境 | 在操作系统中,同时运行的多个任务 | 在程序中多个顺序流同时执行 |
| 分配内存 | 系统在运行的时候为每一个进程分配不同的内存区域 | 线程所使用的资源是他所属进程的资源 |
| 包含关系 | 一个进程内可以拥有多个线程 | 线程是进程的一部分,所有线程有时候称为是轻量级的进程 |
在Python3中,多进程编程使用multiprocessing 模块和subprocess 模块,轻松完成从单进程到并发执行的转换。
进程的创建及调用:
multiprocessing支持子进程、通信和共享数据。语法格式如下:
| Process([group [, target [, name [, args [, kwargs]]]]]) |
|---|
其中target表示调用对象,args表示调用对象的位置参数元组。kwargs表示调用对象的字典。name为别名。group参数未使用,值始终为None。
Process的实例方法、Process的实例属性如下表所示。
| 方法 | 描述 |
|---|---|
| is_alive() | 如果p仍然运行,返回True |
| join([timeout] | 等待进程p终止。Timeout是可选的超时期限,进程可以被链接无数次,但如果连接自身则会出错 |
| run() | 进程启动时运行的方法。默认情况下,会调用传递给Process构造函数的target。定义进程的另一种方法是继承Process类并重新实现run()函数 |
| start() | 启动进程,这将运行代表进程的子进程,并调用该子进程中的run()函数 |
| terminate() | 强制终止进程。如果调用此函数,进程p将被立即终止,同时不会进行任何清理动作。如果进程p创建了它自己的子进程,这些进程将变为僵尸进程。使用此方法时需要特别小心。如果p保存了一个锁或参与了进程间通信,那么终止它可能会导致死锁或I/O损坏 |
Process实例属性表
| 方法 | 描述 |
|---|---|
| name | 进程的名称 |
| pid | 进程的整数进程ID |
创建子进程及属性等使用方法
"""
Version: 0.1
Author: Luicy
Date: 2020-3-20
"""
from multiprocessing import Process
import os
import time
def clock(interval):
for i in range(3):
print("当前的时间为:{}" .format(time.ctime()))
time.sleep(interval)
if __name__ == '__main__':
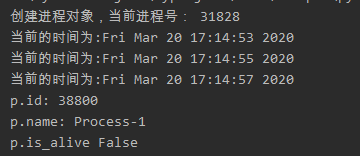
print("创建进程对象,当前进程号:", os.getpid())
p = Process(target=clock, args=(2,))
#调用子进程
p.start()
p.join() #等待进程p终止
#获取进程的pid、名字、判断进程是否活着
print("p.id:", p.pid)
print('p.name:', p.name)
print('p.is_alive', p.is_alive())
执行结果:
我们从下面两个例子来看看使用多进程和不使用的区别:
1、不使用多进程
from random import randint
from time import time, sleep
def download_task(filename):
print('开始下载%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
if __name__ == '__main__':
start = time()
download_task('Python从入门到住院.pdf')
download_task('Tough Love.avi')
end = time()
print('总共耗费了%.2f秒.' % (end - start))
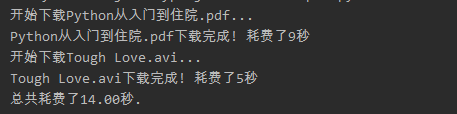
从上面的例子可以看出,如果程序中的代码只能按顺序一点点的往下执行,那么即使执行两个毫不相关的下载任务,也需要先等待一个文件下载完成后才能开始下一个下载任务,很显然这并不合理也没有效率。
2、使用多进程
from random import randint
from time import time, sleep
import os
from multiprocessing import Process
def download_task(filename):
print('启动下载进程,进程号[%d].' % os.getpid())
print('开始下载%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
if __name__ == '__main__':
start = time()
print('主进程号[%d].' % os.getpid())
p1 = Process(target=download_task, args=("Python从入门到住院.pdf",))
p1.start()
p2 = Process(target=download_task, args=("Tough Love.avi",))
p2.start()
p1.join()
p2.join()
end = time()
print('总共耗费了%.2f秒.' % (end - start))
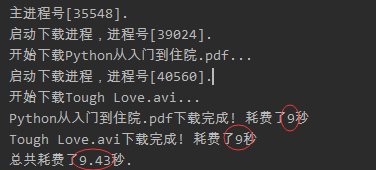
在上面的代码中,我们通过Process类创建了进程对象,通过target参数我们传入一个函数来表示进程启动后要执行的代码,后面的args是一个元组,它代表了传递给函数的参数。Process对象的start方法用来启动进程,而join方法表示等待进程执行结束。运行上面的代码可以明显发现两个下载任务**“同时”**启动了,而且程序的执行时间将大大缩短,不再是两个任务的时间总和。
多个进程之间数据不共享
"""
多个进程之间数据不共享
Version: 0.1
Author: Luicy
Date: 2020-3-20
"""
from multiprocessing import Process
num = 10
def work1():
global num
num += 5
print('子进程1运行后num的值为:', num)
def work2():
global num
num += 10
print('子进程2运行后num的值为:', num)
if __name__ == '__main__':
print('父进程开始运行')
p1 = Process(target=work1)
p2 = Process(target=work2)
p1.start()
p2.start()
p1.join()
p2.join()
print("多任务执行完成后,num的值为:%d" %num)

进程之间的通信
使用multiprocessing模块中的Queue类,它是可以被多个进程共享的队列,从而达到进程之间的通信。
from multiprocessing import Process, Queue
import time
def write(q):
if not q.full():
for i in ["a","b","c"]:
print("开始写入数据%s." % i)
q.put(i)
time.sleep(1)
else:
print("队列已满!")
def reader(q):
while True:
if not q.empty():
print("读取到的数据为%s." % q.get())
time.sleep(1)
else:
break
if __name__ == '__main__':
#创建队列
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=reader, args=(q,))
pw.start()
pw.join()
pr.start()
pr.join()

线程
线程也是实现多任务的一种方式,一个进程可以拥有多个线程,其中每个线程共享当前进程的资源。
在Python中可以通过“_thread”和threading(推荐使用)这两个模块来处理线程。
Threading模块
在Python3程序中,可以通过如下两种方式来创建线程:
- 通过threading.Thread直接在线程中运行函数
- 通过继承类threading.Thread来创建线程
在Python中使用threading.Thread的基本语法格式如下所示:
| Thread(group=None, target=None, name=None, args=(), kwargs={}) |
|---|
其中target: 要执行的方法;name: 线程名;args/kwargs: 要传入方法的参数。
Thread类的方法如表所示:
| 方法 | 描述 |
|---|---|
| run() | 用于表示线程活动的方法 |
| start() | 启动线程的方法 |
| join([time]) | 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生 |
| isAlive() | 返回线程是否活动的 |
| getName() | 返回线程名 |
| setName() | 设置线程名 |
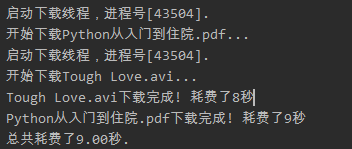
我们把刚才下载文件的例子通过threading.Thread直接在线程中运行函数的方式来实现一遍。
"""
使用多线程的情况 - 模拟多个下载任务
Version: 0.1
Author: Luicy
Date: 2020-3-20
"""
from threading import Thread
from time import time, sleep
from random import randint
import os
def download(filename):
print("启动下载线程,进程号[%d]." % os.getpid())
print("开始下载%s..." % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
if __name__ == '__main__':
start = time()
t1 = Thread(target=download, args=("Python从入门到住院.pdf",))
t1.start()
t2 = Thread(target=download, args=("Tough Love.avi",))
t2.start()
t1.join()
t2.join()
end = time()
print('总共耗费了%.2f秒.' % (end - start))
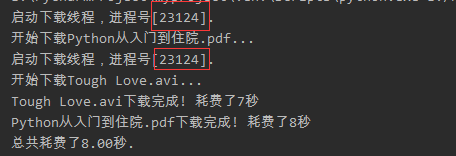
通过继承类threading.Thread的方式来创建线程
"""
使用多线程的情况 - 模拟多个下载任务
Version: 0.1
Author: Luicy
Date: 2020-3-20
"""
from threading import Thread
from time import time, sleep
from random import randint
import os
class DownloadTask(Thread):
def __init__(self, filename):
super().__init__()
self.filename = filename
def run(self):
print("启动下载线程,进程号[%d]." % os.getpid())
print("开始下载%s..." % self.filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (self.filename, time_to_download))
if __name__ == '__main__':
# 将多个下载任务放到多个线程中执行
# 通过自定义的线程类创建线程对象 线程启动后会回调执行run方法
start = time()
t1 = DownloadTask('Python从入门到住院.pdf')
t1.start()
t2 = DownloadTask('Tough Love.avi')
t2.start()
t1.join()
t2.join()
end = time()
print('总共耗费了%.2f秒.' % (end - start))
线程共享全局变量
在一个进程中所有线程共享全局变量,多线程之间的数据也有可能造成同时修改一个变量的现象,来看以下例子。
"""
多个线程共享数据 - 没有锁的情况
Version: 0.1
Author: Luicy
Date: 2020-3-23
"""
from threading import Thread
from time import sleep
class Account(object):
def __init__(self):
self._balance = 0
def deposit(self, money):
# 计算存款后的余额
new_balance = self._balance + money
print("初始值为%d.余额为%d.\n" % (self._balance, new_balance))
# 模拟受理存款业务需要0.01秒的时间
sleep(0.01)
# 修改账户余额
self._balance = new_balance
@property
def balance(self):
return self._balance
class AddMoneyThread(Thread):
def __init__(self, account, money):
super().__init__()
self._account = account
self._money = money
def run(self):
self._account.deposit(self._money)
if __name__ == '__main__':
account = Account()
threads = []
for i in range(1000):
t = AddMoneyThread(account, 1)
print("线程%s启动." % t.name, end="")
threads.append(t)
t.start()
for i in threads:
i.join()
print("账号余额为: ¥%d元" % account.balance)
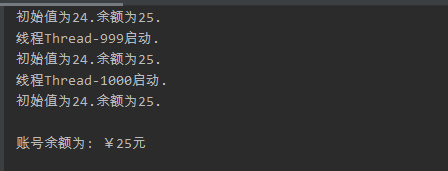
我们可以看到结果远远小于100,好的线程都是获取账户余额都是初始状态下的0的情况下执行new_balance = self._balance + mone,因此得到了错误的数据,这里银行账号就是临界资源,我们没有加保护(锁)导致结果混乱。
互斥锁
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,最简单的同步机制就是引入互斥锁。
锁有两种状态——锁定和未锁定。某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”状态,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
在上述存钱的程序中,银行账号就是我们要锁定的数据。
"""
多个线程共享数据 - 加锁的情况
Version: 0.1
Author: Luicy
Date: 2020-3-23
"""
from threading import Thread, Lock
from time import sleep
class Account(object):
# 先获取锁才能执行后续的代码
def __init__(self):
self._balance = 0
self._lock = Lock()
def deposit(self, money):
self._lock.acquire()
try:
# 计算存款后的余额
new_balance = self._balance + money
print("初始值为%d.余额为%d.\n" % (self._balance, new_balance))
# 模拟受理存款业务需要0.01秒的时间
sleep(0.01)
# 修改账户余额
self._balance = new_balance
finally:
# 释放锁放在finally中保证释放锁的操作一定执行
self._lock.release()
@property
def balance(self):
return self._balance
class AddMoneyThread(Thread):
def __init__(self, account, money):
super().__init__()
self._account = account
self._money = money
def run(self):
self._account.deposit(self._money)
if __name__ == '__main__':
account = Account()
threads = []
for i in range(1000):
t = AddMoneyThread(account, 1)
print("线程%s启动." % t.name, end="")
threads.append(t)
t.start()
for i in threads:
i.join()
print("账号余额为: ¥%d元" % account.balance)
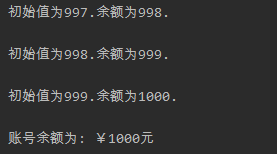
应用案例:
例1:将耗时间的任务放到线程中以获得更好的用户体验
有下载和关于两个按钮,不使用多线程点击下载按钮后整个程序被下载任务阻塞。
"""
Version: 0.1
Author: Luicy
Date: 2020-3-23
"""
import time
import tkinter
import tkinter.messagebox
def download():
# 模拟下载任务需要花费10秒钟时间
time.sleep(10)
tkinter.messagebox.showinfo('提示', '下载完成!')
def show_about():
tkinter.messagebox.showinfo('关于', '作者: Luicy(v1.0)')
def main():
top = tkinter.Tk()
top.title('单线程')
top.geometry('200x150')
top.wm_attributes('-topmost', True)
panel = tkinter.Frame(top)
button1 = tkinter.Button(panel, text='下载', command=download)
button1.pack(side='left')
button2 = tkinter.Button(panel, text='关于', command=show_about)
button2.pack(side='right')
panel.pack(side='bottom')
tkinter.mainloop()
if __name__ == '__main__':
main()
如果使用多线程将耗时间的任务放到一个独立的线程中执行,这样就不会因为执行耗时间的任务而阻塞了主线程,修改后的代码如下所示。
import time
import tkinter
import tkinter.messagebox
from threading import Thread
def main():
class DownloadTaskHandler(Thread):
def run(self):
time.sleep(10)
tkinter.messagebox.showinfo('提示', '下载完成!')
# 启用下载按钮
button1.config(state=tkinter.NORMAL)
def download():
# 禁用下载按钮
button1.config(state=tkinter.DISABLED)
# 通过daemon参数将线程设置为守护线程(主程序退出就不再保留执行)
# 在线程中处理耗时间的下载任务
DownloadTaskHandler(daemon=True).start()
def show_about():
tkinter.messagebox.showinfo('关于', '作者: Luicy(v1.0)')
top = tkinter.Tk()
top.title('单线程')
top.geometry('200x150')
top.wm_attributes('-topmost', 1)
panel = tkinter.Frame(top)
button1 = tkinter.Button(panel, text='下载', command=download)
button1.pack(side='left')
button2 = tkinter.Button(panel, text='关于', command=show_about)
button2.pack(side='right')
panel.pack(side='bottom')
tkinter.mainloop()
if __name__ == '__main__':
main()
例子2:使用多进程对复杂任务进行“分而治之”。
对1~100000000求和的计算密集型任务
from time import time
def main():
total = 0
number_list = [x for x in range(1, 100000001)]
start = time()
for number in number_list:
total += number
print(total)
end = time()
print('Execution time: %.3fs' % (end - start))
if __name__ == '__main__':
main()
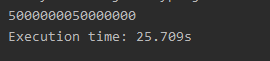
在上面的代码中,先创建了一个列表容器然后填入了100000000个数,这一步其实是比较耗时间的,我们将这个任务分解到8个进程中去执行。
待更新…
上面的部分内容和例子来自于github Python-100-Days-master及尚学堂公开视频。

















 1624
1624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









