







 本文介绍了MySQL中的索引优化,包括前缀索引、覆盖索引、脏页处理和查询优化。前缀索引可以节省空间但增加查询次数,选择合适的长度很重要。脏页可能导致MySQL偶尔性能波动,脏页比例和redo log满是常见原因。删除数据时表文件大小不变,因为空洞和数据页复用。COUNT(*)操作在InnoDB中较慢,因为需要逐行读取。ORDER BY操作取决于索引使用和排序方式,全字段排序可能涉及外部排序。SQL语句的性能差异可能源自函数操作、类型转换和字符串编码。最后讨论了幻读现象和间隙锁的作用,以及更新操作可能的锁竞争。
本文介绍了MySQL中的索引优化,包括前缀索引、覆盖索引、脏页处理和查询优化。前缀索引可以节省空间但增加查询次数,选择合适的长度很重要。脏页可能导致MySQL偶尔性能波动,脏页比例和redo log满是常见原因。删除数据时表文件大小不变,因为空洞和数据页复用。COUNT(*)操作在InnoDB中较慢,因为需要逐行读取。ORDER BY操作取决于索引使用和排序方式,全字段排序可能涉及外部排序。SQL语句的性能差异可能源自函数操作、类型转换和字符串编码。最后讨论了幻读现象和间隙锁的作用,以及更新操作可能的锁竞争。
11、怎么给字符串加索引
比如email这个字段,如果email字段没有索引,那么这个语句只能做全表扫描
mysql支持前缀索引,所以可以定义字符串一部分为索引。
alter table s add index index1(email);
alter table s add index index2(email(6))
存储图:
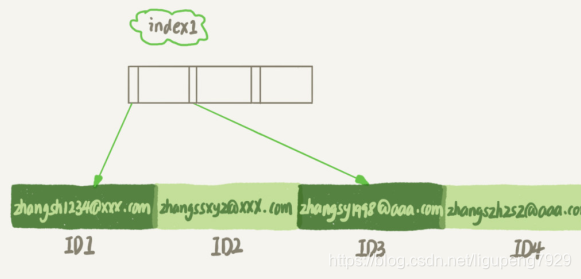
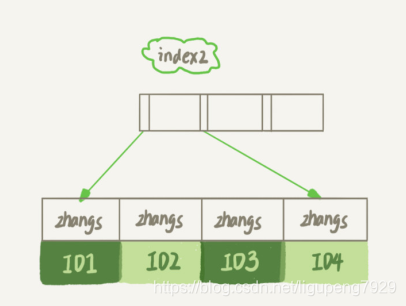
前缀索引这个占用的空间更小,但是会增加额外的记录扫描次数
如果使用index1:
1.从index1索引树找到满足值‘zhangssxyz@xxx.com’,取得ID2的值
2.到主键上查找主键值是ID2的行,判断email值正确,将这行记录加入结果集,然后取index索引上查找位置下一条记录发现不满足条件,循环结束
这个过程,只需要回主键索引取一次数据,所以系统认为只扫描了一行
如果使用index2:
1.从index2索引树找到满足索引值是'zhangs'记录,然找到ID1,到主键查找主键值为ID1的行,判断email值是不是'zhangsss...com',如果不是丢弃,然后取下一条记录,接着判断,如果值对,记录加入结果集,然后重复,直到取到值不是‘zhanggs’时,循环结束
使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本
在建立索引时关注的是区分度,区分度越高越好。
前缀索引对覆盖索引的影响
如果使用email整个字符串的索引结构的话,可以利用覆盖索引,从index1查到结果后直接返回了,不需要回到ID索引再查一次,而如果使用index2(即email(6)索引结构的话),就不得不回到ID索引再去判断email字段的值
使用前缀索引就用不上覆盖索引对查询性能的优化了,这也是选择是否使用前缀索引考虑的一个因素
其他方式:
比如身份证前6位是地址码,所以可以创建12以上的前缀索引,但是索引选取越长,占用的磁盘空间就大,搜索效率越低
即占用更小的空间,也能达到相同的查询效率:
第一种:倒序存储
第二种:使用hash字段。在表上再创建一个整数字段,来保存身份证的校验码,同时再这个字段创建索引
每次插入新纪录的时候,同时用crc32()这个函数得到校验码填到这个新字段。
相同点:都不支持范围查询,只支持等值查询
区别:从查询效率上看,使用hash字段方式查询性能更稳定,因为crc32算出来值虽然有冲突概率但是非常小,而倒序存储毕竟还是用的前缀索引方式,也就是说还是会增加扫描行数、
小结:
1、直接创建完整索引,这样比较占用空间
2、创建前缀索引,节省空间,但是会增加查询扫描次数,并且不能使用覆盖索引
3、倒序存储,再创建前缀索引,用于绕过字符串本身前缀区分度不够问题
4、创建hash字段索引,查询性能稳定,有额外的存储和计算消耗,跟第三种方式一样,都不支持范围扫描
12、为什么我的MySQL会抖一下
在工作中,有种这样的场景,一条SQL语句,正常执行的时候特别快,但是有时也不知道怎么回事,它就会变得特别慢,而且这样的场景很难浮现,它不只随机,而且持续时间还很短。
InnoDB在处理更新语句的时候,只做了一个写日志这一个磁盘操作,这个日志叫做redo log(重做日志),在更新内存写完redo log后,就返回给客户端,本次更新成功
当内存数据也跟磁盘数据也内容不一致的时候,我们称这个内存页为“脏页”。内存数据写入(flush)到磁盘后,内存和磁盘上的数据也的内容就一致了,称为“干净页”
平常执行很快的更新操作,其实就在写内存和日志,而MySQL偶尔抖一下这个瞬间,可能就是在刷脏页(flush)
第一种场景:InnoDB的redo log写满了。这个时候系统会停止所有更新操作,把chekpoint往前推进,redo log留出来空间继续写
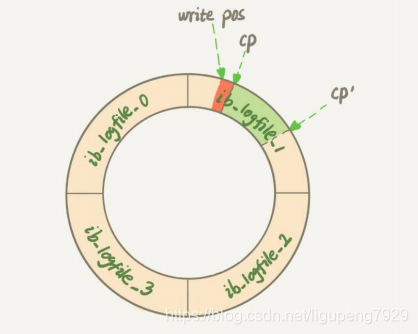
对应图,把checkpoint位置从CP推到CP`,浅绿色部分对应的所有脏页都flush到磁盘上。
第二种场景:系统内存不足。当需要新的内存页,而内存不够用的时候,就要淘汰一些数据也,空出内存给别的数据页使用。如果淘汰的是“脏页”,就要先flush到磁盘
在这里并没直接把内存淘汰,下次需要请求的时候,从磁盘读入数据页,然后拿redo log出来应用,这里其实从性能考虑的,如果刷脏页一定会写盘,就保证了每个数据页有两种状态
一种是内存里存在,内存里就肯定是正确结果,直接返回
另一种内存里没有数据,就可以肯定数据文件上市正确结果,读入内存后返回,这样效率最高
第三种场景:属于MySQL空闲的时候,这时系统没什么压力,就会把脏页进行flush到磁盘上
第四种场景:MySQL正常关闭的时候,这个时候会把内存的脏页都flush到磁盘上。这样下次MySQL启动的时候,就直接从磁盘上读数据,启动速度会很快
主要分析前两种:
第一种:是“redo log”写满了,要flush脏页。这种情况是innoDB尽量避免的,因为这个时候,整个系统不能再接受更新了,所有的更新必须堵住,如果你从监控上看,这个时候更新数会跌为0
第二种:内存不够用,要先将脏数据写到磁盘。这个情况是常态,InnoDB用缓存池(buffer pool)管理内存,缓冲池中的内存页有三种状态:
a>还没有使用的 b>使用了并且是干净页 c>使用了并且是脏页
当要读入的数据页没有在内存的时候,就必须到缓冲池中申请一个数据页。这个时候只能把最久不适用的数据页从内存中淘汰掉,如果淘汰的是干净页直接释放;如果是脏页就必须flush到磁盘,变成干净页,然后释放
但是出现这样的情况会明显影响性能:1>一个查询要淘汰的脏页个数太多,会导致查询时间明显变长;2>日志写满,更新全被堵住,写性能跌为0,这种情况对敏感业务是不能接受的。所以Innodb需要有控制脏页比例的机制来尽量避免上面两种情况
InnoDB刷脏页的控制策略:
首先需要innodb_io_capacity这个参数,告知InnoDB的磁盘能力,这样InnoDB才知道主机的IO能力,才能知道需要全力刷脏页的时候可以多快。一般这个值建议设置成磁盘的IOPS。磁盘的IOPS(磁盘性能指标)可以通过fio这个工具来测试。
实例:因为没有正确设置这个参数导致的问题比比皆是。之前就有公司一个库的性能问题,说MySQL的写入速度很慢,TPS很低,但是就看主机的IO压力并不大。经过一番排查发现罪魁祸首是这个参数设置出问题,他的主机磁盘用的SSD,但是innodb_io_capacity的值设置为300。于是,InnoDB认为这个系统的能力差,所以刷脏页刷的特别慢,甚至比脏页生成速度还蛮,这就造成脏页累积,影响了查询和更新性能
InnoDB怎么控制引擎按照“全力“的百分比来刷脏页:
InnoDB刷盘速度参考两个因素:1、脏页比例 2、redo log写盘速度
参数innodb_max_dirty_pages_pct是脏页比例上限,默认值是75%
InnoDB在后台刷脏页,而过程是要将内存页写入磁盘。所以无论是你的查询语句在需要内存的时候淘汰一个脏页,还是由于刷脏页的逻辑占用IO并可能影响到更新于巨,都会造成业务端感知到mysql抖一下的原因,所以要合理设置innodb_io_capacity的值不要让他接近75%
InnoDB刷新脏页的策略:
一旦一个查询请求需要在执行过程flush掉一个脏页时,这个查询就要比平常慢。而在mysql中有这样的一个机制,在准备刷一个脏页的时候,如果这个数据页旁边的数据页刚好也是脏页,就顺带一起刷掉,然后继续延续。
其中innodb_flush_neighbors参数就是控制这个行为的,值为1的时候出现这种‘连坐’机制,值为0的话自己刷自己的
情景对比:这个优化在机器硬盘的时候很有意义,可以减少很多随机IO。机械硬盘的随机IOPS一般只有几百,所以减少很多随机IO意味着性能大幅度提升
但是如果SSD这类IOPS比较高的设备,这个时候IOPS往往不是瓶颈,只刷自己的这样的话可以更快执行完必要的刷脏数据操作,减少SQL语句响应时间
在MYSQL 8.0 innodb_flush_neighbors默认值为0
总结:
在第二章的WAL的概念,这个机制后续需要刷脏页操作和执行时机。利用WAL技术,数据库将随机写转换成了顺序写,大大提升了数据库的性能,但是,由此也带来了内存脏页的问题,脏页会被后台线程自动flush,也会由数据页淘汰而出发flush,而刷脏页的过程由于会占用资源,可能会让你的更新和查询语句响应时间过长
表删掉一半,表文件大小不变?
当删除整个表的时候,可以使用drop table命令回收表空间。但是,当删除数据的场景是删除某些行,这时就遇到了表中数据被删掉,但是表空间却没有被回收
数据删除流程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3716
3716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









