







 超级会员免费看
超级会员免费看
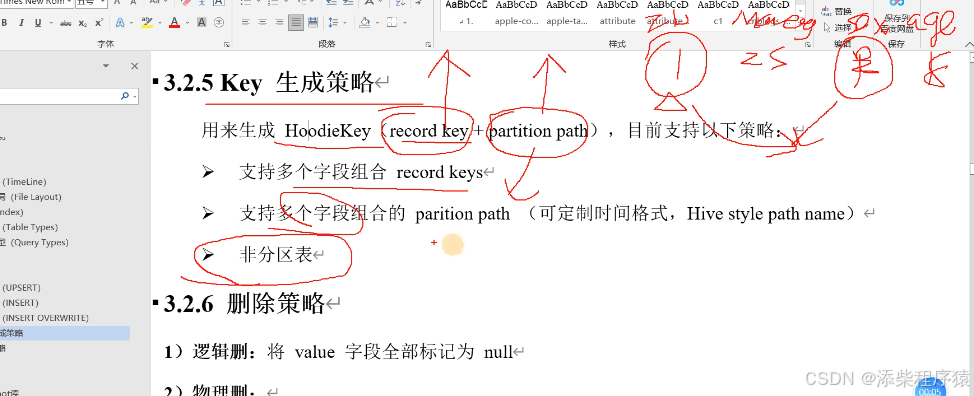
然后再来看一下hudi中表的,主键生成策略,可以看到
1.支持多字段组合,比如有 id name sex age字段,那么你可以只用id做为主键,也可以用id +name组合做为主键
另外record key 主键+ 分区路径组合成了hoodieKey主键
2.然后看看什么是非分区表
在Apache Hudi中,"非分区表"是指没有按照特定列进行分区的表。在Hudi中,数据可以通过分区来组织,这类似于Hive中的分区表,其中数据根据某些列的值(如日期或地区)被分割成不同的分区。分区有助于优化查询性能,因为查询可以仅针对相关的分区进行,而不是扫描整个数据集。
以下是关于Hudi中非分区表的一些关键点:
数据组织:
非分区表没有按照任何分区键进行组织。所有数据都存储在同一个目录下,而不是分散到不同的分区目录中。
查询性能:
由于非分区表没有分区结构,查询时可能需要扫描整个数据集,这可能会导致查询性能不如分区表。
数据管理:
管理非分区表通常更简单,因为你不需要考虑分区键和分区策略。这对于数据量较小或不需要按特定维度查询的场景来说可能是一个优势。
文件布局:
在Hudi中,即使是非分区表,数据仍然会被组织成文件组,每个文件组包含基础文件和增量日志文件。这些文件组根据Hudi的文件分配策略来管理。
使用场景:
非分区表适用于那些不需要按时间、地区或其

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2835
2835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











