







然后我们再来看LlamaIndex开发框架提供了:
更多的数据连机器,包括内置的以及三方的,可以用来轻松的提取各种文档的数据,包括音频,视频,图片等的内容:
<div class="alert alert-info">
<b>更多 Data Connectors</b>
<ul>
<li>内置的<a href="https://llamahub.ai/l/readers/llama-index-readers-file">文件加载器</a></li>
<li>连接三方服务的<a href="https://docs.llamaindex.ai/en/stable/module_guides/loading/connector/modules/">数据加载器</a>,例如数据库</li>
<li>更多加载器可以在 <a href="https://llamahub.ai/">LlamaHub</a> 上找到</li>
</ul>
</div>
上面已经给出了对应的地址,可以看到,这里面有非常多的,三方的数据加载工具都是可以用的.
可以点击DataLoaders这个就是数据加载器,有很多
https://llamahub.ai/?tab=readers
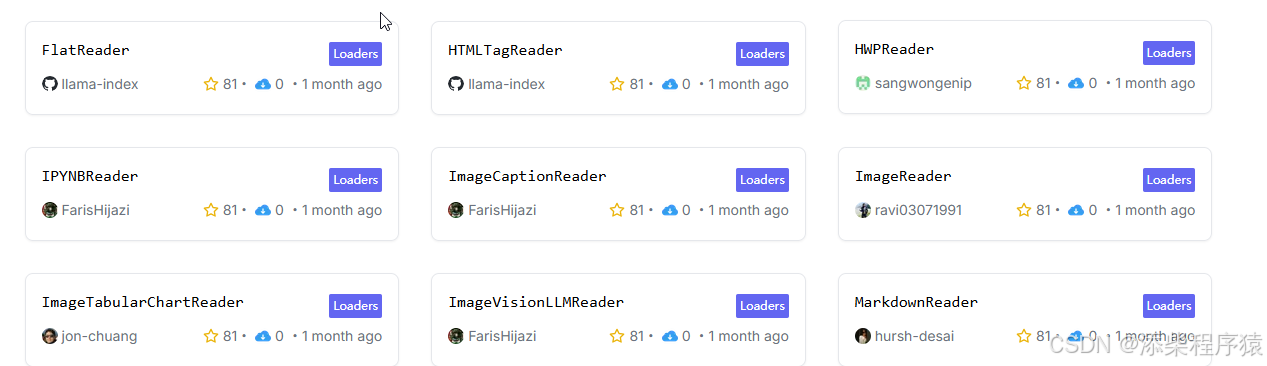
可以在搜索框中进行搜索,可以看到这里就有ImageCaptionReader等等,它们是使用一些神经网络模型来进行提取图片或者音频
视频内容的,这里找到以后都可以使用.
https://docs.llamaindex.ai/en/stable/module_guides/loading/connector/modules/
然后这个是LlamaIndex 的开发文档,可以去看
https://llamahub.ai/l/readers/llama-index-readers-file
然后这个是llamaindex的readers可以看到,他是放到GitHub上了,可以去GitHub去看
https://github.com/run-llama/llama_index/tree/main/llama-index-integrations/readers/llama-index-readers-file/llama_index/readers/file
可以去GitHub查看也是可以的.

然后再来看文本的切分和解析,可以看到也就是文本的chunking,切块
在LlamaIndex中把文档定义为一个Document容纳后,可以把Document切分为一个个的Node,
其实就是一个个的文本块,也叫chunk.
### 4.1、使用 TextSplitters 对文本做切分
例如:`TokenTextSplitter` 按指定 token 数切分文本
先来看一个案例,用来切分文本的,按照token数来切分文本的.
from llama_index.core import Document
from llama_index.core.node_parser import TokenTextSplitter
node_parser = TokenTextSplitter(
chunk_size=100, # 每个 chunk 的最大长度
chunk_overlap=50 # chunk 之间重叠长度
)
nodes = node_parser.get_nodes_from_documents(
documents, show_progress=False
)
show_json(nodes[0].json())
show_json(nodes[1].json())
注意上面用的这个show_json上一节有源码
下面是切分以后的结果.
{
"id_": "0a1eee9a-635a-4391-8b74-75bf3c648f0e",
"embedding": null,
"metadata": {
"document_id": "FULadzkWmovlfkxSgLPcE4oWnPf"
},
"excluded_embed_metadata_keys": [],
"excluded_llm_metadata_keys": [],
"relationships": {
"1": {
"node_id": "9cd5baeb-1c59-448a-9c95-df7fb634b6bb",
"node_type": "4",
"metadata": {
"document_id": "FULadzkWmovlfkxSgLPcE4oWnPf"
},
"hash": "aa5f32dabade1da0e01c23cb16e160b624565d09a4a2a07fb7f7fd4d45aac88a",
"class_name": "RelatedNodeInfo"
},
"3": {
"node_id": "1a1aa20f-a88a-49a6-a0c6-fd13700022e4",
"node_type": "1",
"metadata": {},
"hash": "654c6cbdd5a23946a84e84e6f3a474de2a442191b2be2d817ba7f04286b1a980",
"class_name": "RelatedNodeInfo"
}
},
"text": "AI 大模型全栈工程师培养计划 - AGIClass.ai\n\n由 AGI 课堂推出的社群型会员制课程,传授大模型的原理、应用开发技术和行业认知,助你成为",
"mimetype": "text/plain",
"start_char_idx": 0,
"end_char_idx": 76,
"text_template": "{metadata_str}\n\n{content}",
"metadata_template": "{key}: {value}",
"metadata_seperator": "\n",
"class_name": "TextNode"
}
{
"id_": "1a1aa20f-a88a-49a6-a0c6-fd13700022e4",
"embedding": null,
"metadata": {
"document_id": "FULadzkWmovlfkxSgLPcE4oWnPf"
},
"excluded_embed_metadata_keys": [],
"excluded_llm_metadata_keys": [],
"relationships": {
"1": {
"node_id": "9cd5baeb-1c59-448a-9c95-df7fb634b6bb",
"node_type": "4",
"metadata": {
"document_id": "FULadzkWmovlfkxSgLPcE4oWnPf"
},
"hash": "aa5f32dabade1da0e01c23cb16e160b624565d09a4a2a07fb7f7fd4d45aac88a",
"class_name": "RelatedNodeInfo"
},
"2": {
"node_id": "0a1eee9a-635a-4391-8b74-75bf3c648f0e",
"node_type": "1",
"metadata": {
"document_id": "FULadzkWmovlfkxSgLPcE4oWnPf"
},
"hash": "b08e60a1cf7fa55aa8c010d792766208dcbb34e58aeead16dca005eab4e1df8f",
"class_name": "RelatedNodeInfo"
},
"3": {
"node_id": "54c6a119-d914-4690-aa3c-1275d55efe5a",
"node_type": "1",
"metadata": {},
"hash": "06d6c13287ff7e2f033a1aae487198dbfdec3d954aab0fd9b4866ce833200afb",
"class_name": "RelatedNodeInfo"
}
},
"text": "AGI 课堂推出的社群型会员制课程,传授大模型的原理、应用开发技术和行业认知,助你成为 ChatGPT 浪潮中的超级个体\n什么是 AI",
"mimetype": "text/plain",
"start_char_idx": 33,
"end_char_idx": 100,
"text_template": "{metadata_str}\n\n{content}",
"metadata_template": "{key}: {value}",
"metadata_seperator": "\n",
"class_name": "TextNode"
}
可以看到切完以后的结果可以看到这里有,relationships,记录了1,2,3...这个是为了,用来保证切分后,
文本块之间的顺序等添加了一些属性.
LlamaIndex 提供了丰富的 `TextSplitter`,例如:
- [`SentenceSplitter`](https://docs.llamaindex.ai/en/stable/api_reference/node_parsers/sentence_splitter/):在切分指定长度的 chunk 同时尽量保证句子边界不被切断;
- [`CodeSplitter`](https://docs.llamaindex.ai/en/stable/api_reference/node_parsers/code/):根据 AST(编译器的抽象句法树)切分代码,保证代码功能片段完整;
- [`SemanticSplitterNodeParser`](https://docs.llamaindex.ai/en/stable/api_reference/node_parsers/semantic_splitter/):根据语义相关性对将文本切分为片段。
然后LlamaIndex提供了丰富的文本切分工具:比如:

1.SentenceSplitter:切的时候可以尽量保证一个完整的句子不被切开.
2.CodeSplitter:切的时候如果是代码,尽量不会把一整段代码切开,这样就不能运行了.
3.SemanticSplitterNodeParser:可以根据语义进行切分,把一个意思的内容切到一块.
都是一些更高级的切分工具.
然后还提供了
这种NodeParsers这种的工具,主要是对,有文档结构的,比如markdown文档,它里面就是有结果的,比如几级标题啊等
还有docx中也是有文档的几级标题等,有结果的文档,他可以把文档的内部结构解析出来.
然后我们来做一个使用MarkdownNodeParser来进行markdown文档解析的功能:
比如我们来解析这个markdown文档.
### 4.2、使用 NodeParsers 对有结构的文档做解析
例如:`MarkdownNodeParser`解析 markdown 文档
from llama_index.readers.file import FlatReader
from llama_index.core.node_parser import MarkdownNodeParser
from pathlib import Path
md_docs = FlatReader().load_data(Path("./data/ChatALL.md"))
parser = MarkdownNodeParser()
nodes = parser.get_nodes_from_documents(md_docs)
show_json(nodes[2].json())
show_json(nodes[3].json())
可以看到用法也是很简单.
{
"id_": "5c2eb25f-08ac-4b2e-9050-bc6efa90304a",
"embedding": null,
"metadata": {
"filename": "ChatALL.md",
"extension": ".md",
"Header_2": "功能"
},
"excluded_embed_metadata_keys": [],
"excluded_llm_metadata_keys": [],
"relationships": {
"1": {
"node_id": "f3be7692-141b-41a6-8b3f-58402aaf36c1",
"node_type": "4",
"metadata": {
"filename": "ChatALL.md",
"extension": ".md"
},
"hash": "45b9149e0039c1ef7fbbd74f96923875505cc77916de48734ba7767f6a16a87e",
"class_name": "RelatedNodeInfo"
},
"2": {
"node_id": "3722d2c3-6638-453c-8fe1-f2af97fc8452",
"node_type": "1",
"metadata": {
"filename": "ChatALL.md",
"extension": ".md",
"Header_2": "屏幕截图"
},
"hash": "f6065ad5e9929bc7ee14e3c4cc2d29c06788501df8887476c30b279ba8ffd594",
"class_name": "RelatedNodeInfo"
},
"3": {
"node_id": "c5dcf1d3-7a6a-48b0-b6d8-06457b182ac5",
"node_type": "1",
"metadata": {
"Header_2": "功能",
"Header_3": "这是你吗?"
},
"hash": "f54ac07d417fbcbd606e7cdd3de28c30804e2213218dec2e6157d5037a23e289",
"class_name": "RelatedNodeInfo"
}
},
"text": "功能\n\n基于大型语言模型(LLMs)的 AI 机器人非常神奇。然而,它们的行为可能是随机的,不同的机器人在不同的任务上表现也有差异。如果你想获得最佳体验,不要一个一个尝试。ChatALL(中文名:齐叨)可以把一条指令同时发给多个 AI,帮助您发现最好的回答。你需要做的只是[下载、安装](https://github.com/sunner/ChatALL/releases)和提问。",
"mimetype": "text/plain",
"start_char_idx": 459,
"end_char_idx": 650,
"text_template": "{metadata_str}\n\n{content}",
"metadata_template": "{key}: {value}",
"metadata_seperator": "\n",
"class_name": "TextNode"
}
{
"id_": "c5dcf1d3-7a6a-48b0-b6d8-06457b182ac5",
"embedding": null,
"metadata": {
"filename": "ChatALL.md",
"extension": ".md",
"Header_2": "功能",
"Header_3": "这是你吗?"
},
"excluded_embed_metadata_keys": [],
"excluded_llm_metadata_keys": [],
"relationships": {
"1": {
"node_id": "f3be7692-141b-41a6-8b3f-58402aaf36c1",
"node_type": "4",
"metadata": {
"filename": "ChatALL.md",
"extension": ".md"
},
"hash": "45b9149e0039c1ef7fbbd74f96923875505cc77916de48734ba7767f6a16a87e",
"class_name": "RelatedNodeInfo"
},
"2": {
"node_id": "5c2eb25f-08ac-4b2e-9050-bc6efa90304a",
"node_type": "1",
"metadata": {
"filename": "ChatALL.md",
"extension": ".md",
"Header_2": "功能"
},
"hash": "90172566aa1795d0f9ac33c954d0b98fde63bf9176950d0ea38e87e4ab6563ed",
"class_name": "RelatedNodeInfo"
},
"3": {
"node_id": "7d959c37-6ff9-4bfe-b499-c509a24088cb",
"node_type": "1",
"metadata": {
"Header_2": "功能",
"Header_3": "支持的 AI"
},
"hash": "1b2b11abec9fc74b725b6c344f37d44736e8e991a3eebdbcfa4ab682506c7b2e",
"class_name": "RelatedNodeInfo"
}
},
"text": "这是你吗?\n\nChatALL 的典型用户是:\n\n- 🤠**大模型重度玩家**,希望从大模型找到最好的答案,或者最好的创作\n- 🤓**大模型研究者**,直观比较各种大模型在不同领域的优劣\n- 😎**大模型应用开发者**,快速调试 prompt,寻找表现最佳的基础模型",
"mimetype": "text/plain",
"start_char_idx": 656,
"end_char_idx": 788,
"text_template": "{metadata_str}\n\n{content}",
"metadata_template": "{key}: {value}",
"metadata_seperator": "\n",
"class_name": "TextNode"
}
这个是切分出来的结果,然后
更多的 `NodeParser` 包括
[`HTMLNodeParser`](https://docs.llamaindex.ai/en/stable/api_reference/node_parsers/html/),
[`JSONNodeParser`](https://docs.llamaindex.ai/en/stable/api_reference/node_parsers/json/)等等。
NodeParser还提供了一些其他的结构化文档的解析,比如HTML的,JSON的等等.
这个可以具体的去看LlamaIndex的文档.上面是地址.
## 5、索引(Indexing)与检索(Retrieval)
然后数据加载和切分完了以后,然后我们来看:
就可以把数据可以灌入到向量数据库中.
**基础概念**:在「检索」相关的上下文中,「索引」即`index`, 通常是指为了实现快速检索而设计的特定「数据结构」。
索引的具体原理与实现不是本课程的教学重点,感兴趣的同学可以参考:
[传统索引](https://en.wikipedia.org/wiki/Search_engine_indexing)、
[向量索引](https://medium.com/kx-systems/vector-indexing-a-roadmap-for-vector-databases-65866f07daf5)
至于这里提到的索引,其实就是查找数据用的,跟传统索引是一个意义,那么
传统索引和 向量索引有什么区别?
这里提供了两篇文章可以去看看.
 +
+


### 5.1、向量检索
1. `SimpleVectorStore` 直接在内存中构建一个 Vector Store 并建索引
然后我们来看一下向量检索和索引的例子.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.node_parser import TokenTextSplitter
from llama_index.readers.file import PyMuPDFReader
# 加载 pdf 文档
documents = SimpleDirectoryReader(
"./data",
required_exts=[".pdf"], #只读取pdf文件
file_extractor={".pdf": PyMuPDFReader()} #指定pdf解析加载器
).load_data()
# 定义 Node Parser
node_parser = TokenTextSplitter(chunk_size=300, chunk_overlap=100)
#没给chunk文本块300个tocken #文字重叠允许100个token
# 切分文档 对文档进行切分
nodes = node_parser.get_nodes_from_documents(documents)
# 构建 index 构建索引
index = VectorStoreIndex(nodes)
# 获取 retriever 根据索引获得查询器,设置查询器返回两个结果.
vector_retriever = index.as_retriever(
similarity_top_k=2 # 返回2个结果
)
# 检索 开始查询.
results = vector_retriever.retrieve("Llama2有多少参数")
print(results[0].text)
print()
print(results[1].text)
an updated version of Llama 1, trained on a new mix of publicly available data. We also
increased the size of the pretraining corpus by 40%, doubled the context length of the model, and
adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with
7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper
but are not releasing.§
2. Llama 2-Chat, a fine-tuned version of Llama 2 that is optimized for dialogue use cases. We release
variants of this model with 7B, 13B, and 70B parameters as well.
We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs,
Llama 2 is a new technology that carries potential risks with use (Bender et al., 2021b; Weidinger et al., 2021;
Solaiman et al., 2023). Testing conducted to date has been in English and has not — and could not — cover
all scenarios. Therefore, before deploying any applications of
Koura Marie-Anne Lachaux Thibaut Lavril Jenya Lee Diana Liskovich
Yinghai Lu Yuning Mao Xavier Martinet Todor Mihaylov Pushkar Mishra
Igor Molybog Yixin Nie Andrew Poulton Jeremy Reizenstein Rashi Rungta Kalyan Saladi
Alan Schelten Ruan Silva Eric Michael Smith Ranjan Subramanian Xiaoqing Ellen Tan Binh Tang
Ross Taylor Adina Williams Jian Xiang Kuan Puxin Xu Zheng Yan Iliyan Zarov Yuchen Zhang
Angela Fan Melanie Kambadur Sharan Narang Aurelien Rodriguez Robert Stojnic
Sergey Edunov
Thomas Scialom∗
GenAI, Meta
Abstract
In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned
large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters.
Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our
models outperform open-source chat models on most benchmarks we tested, and based on
our human evaluations for helpfulness and safety, may be a suitable substitute for
可以看到上面就是查询到的两段文字,跟llama2的参数都是有关系的对吧.
<div class="alert alert-warning">
<p>LlamaIndex 默认的 Embedding 模型是 <code>OpenAIEmbedding(model="text-embedding-ada-002")</code>。</p>
<p>如何替换指定的 Embedding 模型见后面章节详解。</p>
</div>
这里注意,LlamaIndex默认用的向量化的模型是openAIEmbedding这个模型.具体的text-embedding-ada-002这个模型,
来进行向量化的.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











