







 超级会员免费看
超级会员免费看
 本文介绍了如何使用IP-Adapter模型仅用一张图片实现风格转换,以及InstantID如何融合IP-Adapter与UNet进行人脸特征注入。此外,探讨了生图模型加速技术,包括算子加速如TensorRT ONNX、蒸馏加速如LCM模型(4步出图)和ADD SD Turbo(2步生图)。这些方法旨在提高模型生成图片的速度和效率。
本文介绍了如何使用IP-Adapter模型仅用一张图片实现风格转换,以及InstantID如何融合IP-Adapter与UNet进行人脸特征注入。此外,探讨了生图模型加速技术,包括算子加速如TensorRT ONNX、蒸馏加速如LCM模型(4步出图)和ADD SD Turbo(2步生图)。这些方法旨在提高模型生成图片的速度和效率。
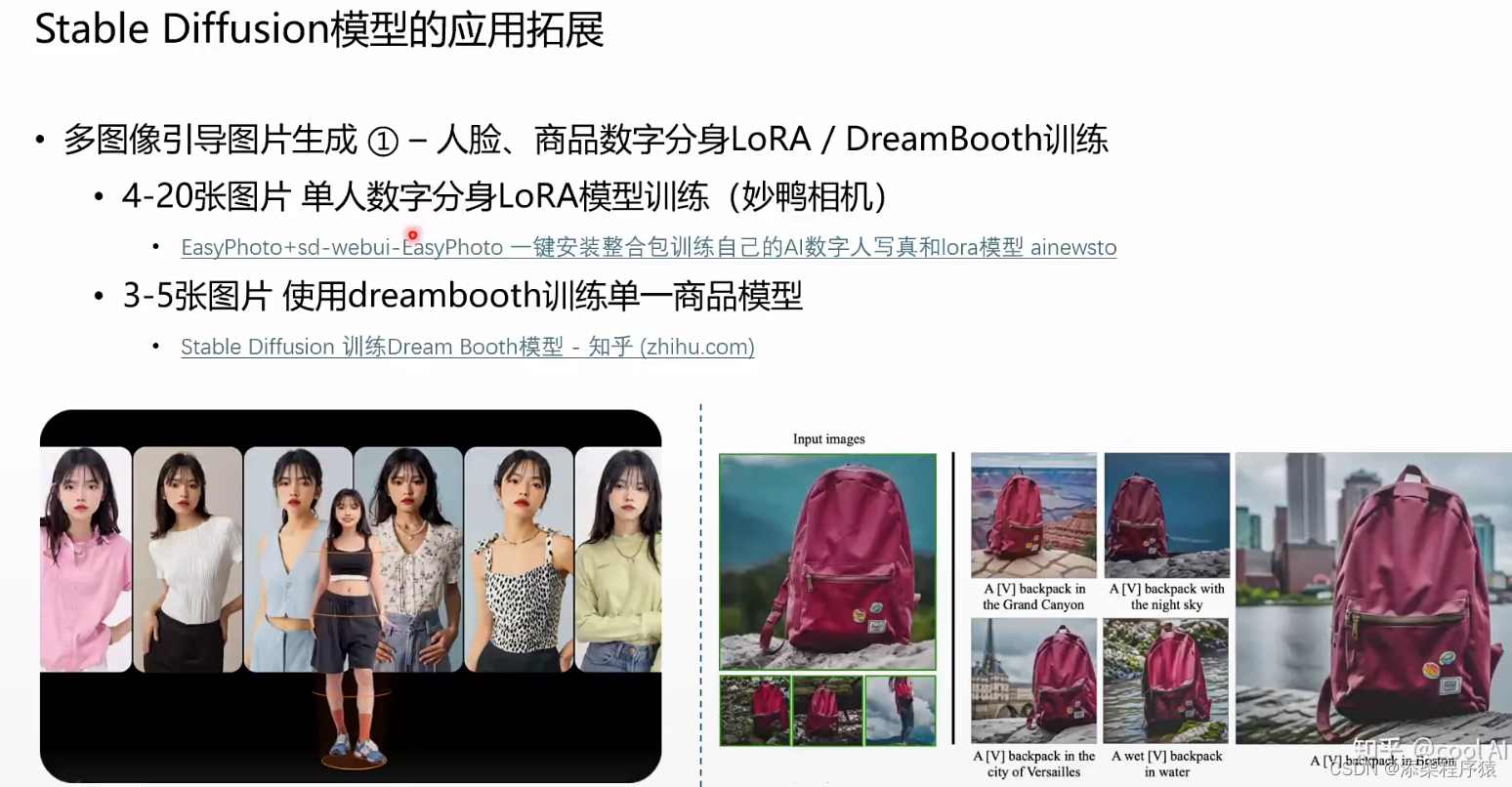
然后我们继续来看这里的stable diffusion中我们说,如果使用loRA/DreamBooth训练,生成
数字分身,或者多场景下同一个物体不同表现,那么需要用到4到20张图片,但是

使用IP adapter就可以只用一张图片,就可以刻画出不同风格的图片
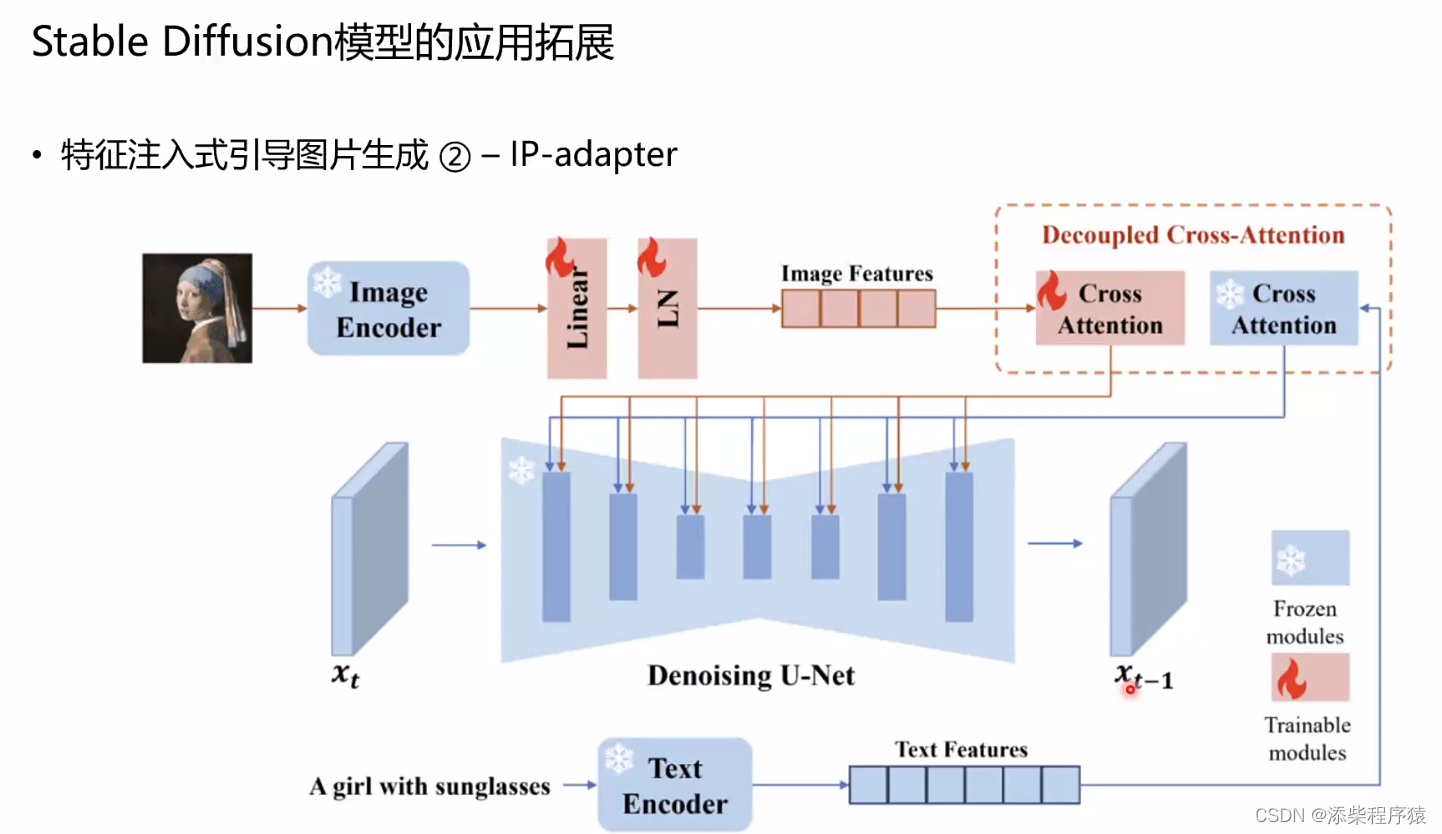
让的做法是,首先使用image encoder对图片进行编码,提取图像特征,decoupled cross-attention,然后解耦交叉注意力,然后
然后这里带雪花的部分是冻结原有的参数,然后火的,表示可训练的参数.
“decoupled cross-attention” 这个术语在深度学习和自然语言处理(NLP)的上下文中较为常见,特别是在涉及Transformer架构和自注意力机制(self-attention)的变体中。
-
<

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











