







 超级会员免费看
超级会员免费看
 本文介绍了如何使用Python中的轮廓系数来评估聚类效果,并找到最佳的类别数目。通过`make_blobs`生成数据集,利用KMeans进行聚类,通过`silhouette_score`计算轮廓系数,绘制得分曲线,最终确定最佳聚类数为3。
本文介绍了如何使用Python中的轮廓系数来评估聚类效果,并找到最佳的类别数目。通过`make_blobs`生成数据集,利用KMeans进行聚类,通过`silhouette_score`计算轮廓系数,绘制得分曲线,最终确定最佳聚类数为3。
然后我们来看看,如何使用轮廓系数来,判断我们应该分为几类数据
首先导包:
import numpy as np 导入数学计算包
from sklearn import datasets 导入数据生成包
from sklearn.cluster import KMeans 导入聚类算法包
from sklearn.metrics import silhouette_score#轮廓系数 导入轮廓系数包
import matplotlib.pyplot as plt 导入画图包
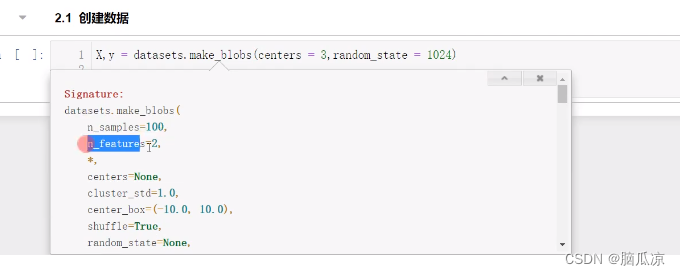
然后我们再来看,
X,y = datasets.make_blobs(centers = 3,random_state =1024)
这里这个意思使用make_blobs 生成,3种分类的数据,并且,我们指定了centers是3,表示3种分类,然后指定了random_state=1024 表示,每次按照1024这种规则生成随机数据集

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











