







 超级会员免费看
超级会员免费看
 本文详细解读了Hudi数据湖中COW和MOR表的查询类型,包括快照查询、增量查询和读优化查询的原理。快照查询返回全量最新数据,MOR表在查询时可能需要即时合并;COW表直接返回最新Parquet文件。增量查询仅获取特定时间点之后的数据,读优化查询则可能不包含未合并的增量数据。
本文详细解读了Hudi数据湖中COW和MOR表的查询类型,包括快照查询、增量查询和读优化查询的原理。快照查询返回全量最新数据,MOR表在查询时可能需要即时合并;COW表直接返回最新Parquet文件。增量查询仅获取特定时间点之后的数据,读优化查询则可能不包含未合并的增量数据。

然后我们再来看一下hudi支持的三种查询类型,这里
首先有快照查询,这里其实我们就记住,全量最新就可以了,就是说,他会把全量的,最新的数据返回,
对于MOR表读时合并的表中:你读取的时候,他会即时的把最新文件片中的.parquet这个文件和增量文件.log文件合并起来,然后提供给你,接近实时的表,大概有几分钟的时间.
对于COW这种表来说,其实就直接把最新的.parquet文件直接返回就可以了,因为COW写时复制表,里面最新的.parquet文件就包含了最新的数据了.
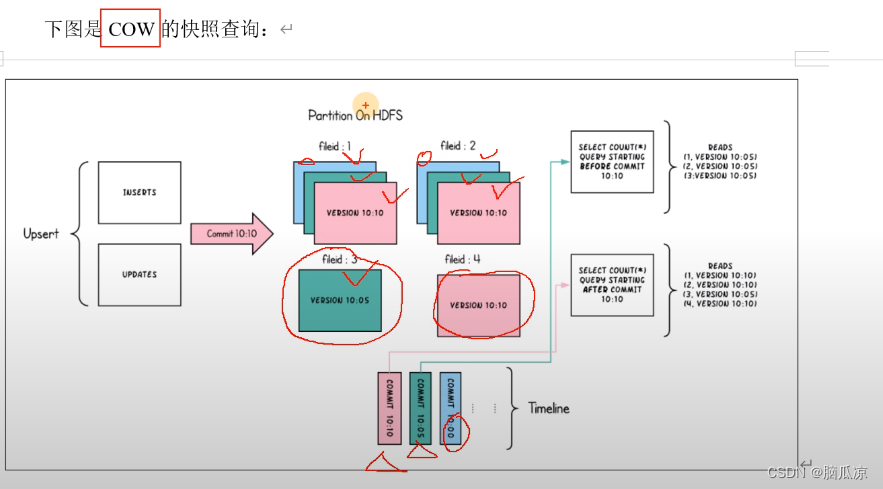
我们看一下这个而是COW表,写时复制表,这里面可以看到,
这里的fileid1 fileid2 3 4这个是一个个的文件组,然后10.00的时候来了一批数据,这个时候
数据设计到fileid1文件组和fileid2文件组的更新,然后还有
10.05的时候涉及到fileid1和fileid2文件组的更新和fileid3文件组的新数据的插入.
10.10分的时候,又来了一批数据,涉及到,fileid1文件组和fileid2文件组的更新和fileid4文件组的插入

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











