







 超级会员免费看
超级会员免费看
 Apache Iceberg是一种表格式管理工具,位于数据存储和计算引擎之间,如Spark。相较于Hive,Netflix因Hive元数据查询速度慢而创建了Iceberg。Hive的分区方式导致大量目录,查询时需通过MySQL获取分区信息后再在HDFS上逐个扫描,而Iceberg将元数据存储在内部,直接定位到HDFS具体文件,显著提高查询效率。
Apache Iceberg是一种表格式管理工具,位于数据存储和计算引擎之间,如Spark。相较于Hive,Netflix因Hive元数据查询速度慢而创建了Iceberg。Hive的分区方式导致大量目录,查询时需通过MySQL获取分区信息后再在HDFS上逐个扫描,而Iceberg将元数据存储在内部,直接定位到HDFS具体文件,显著提高查询效率。
 可以看到Iceberg处于,数据存储之上,计算引擎之下,中间的这个部分。
可以看到Iceberg处于,数据存储之上,计算引擎之下,中间的这个部分。
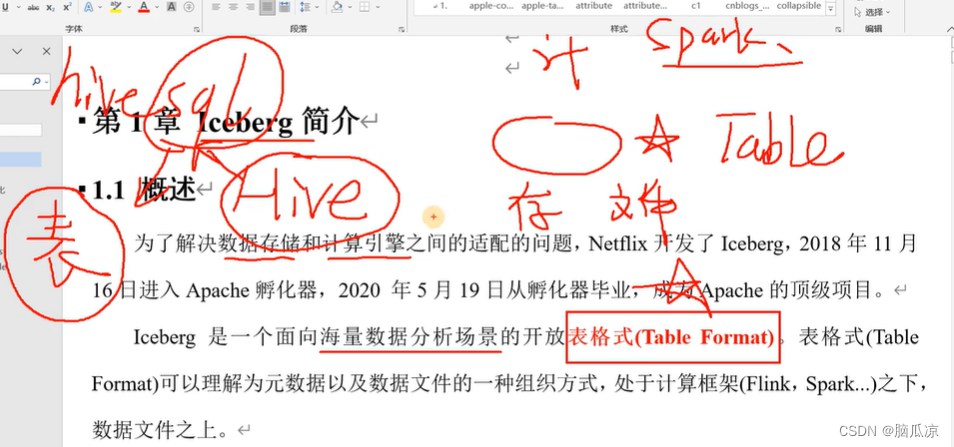
然后我们再来看,主要是iceberg是表格式的,这里他在存储之上,在计算引擎之下,这里的计算引擎可以是spark,如果类比hive,那么iceberg也提供了类似表格的管理方式。

然后继续来看,这里iceberg,我们对比一下hive来说,因为Netflix公司,就那个拍电影的公司,之前用的也是hive处理,但是发现了一个问题,
因为我们知道hive支持数据的分区,分区其实就是一个个的目录对吧,对应他在hdfs上的一个个的目录,比如我们要以一个小时为一个分区,那么,一天就有24个分区,也就是在hdfs上有24个目录,然后,如果一个月,一年呢?就7,8000个分区,也就是在hdfs上有7,8000个目录,来存储这一个表的信息。
然后我们后期要查询数据,那么我们知道hive依赖比如mysql,来存储

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











