







 超级会员免费看
超级会员免费看
 本文档详细介绍了在CentOS7.9系统上安装DataEase开源BI工具的步骤,包括检查系统架构、下载安装包、解压、配置文件修改以避免IP冲突,以及卸载旧版本和执行安装脚本的过程。安装完成后,用户可以开始使用DataEase进行数据处理和分析。
本文档详细介绍了在CentOS7.9系统上安装DataEase开源BI工具的步骤,包括检查系统架构、下载安装包、解压、配置文件修改以避免IP冲突,以及卸载旧版本和执行安装脚本的过程。安装完成后,用户可以开始使用DataEase进行数据处理和分析。
我这里用的是Centos7.9安装的

可以通过uname -p来查看一下我们的电脑架构,可以看到是x86_64架构的
我们下第一个,这个是x86架构的,第二个arm架构的

然后解压到/opt/module中
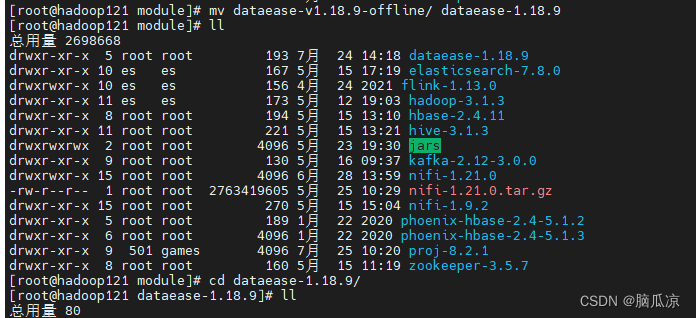
然后再去重命名一下文件夹.
我这里用的是Centos7.9安装的
可以通过uname -p来查看一下我们的电脑架构,可以看到是x86_64架构的
我们下第一个,这个是x86架构的,第二个arm架构的
然后解压到/opt/module中
然后再去重命名一下文件夹.

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























