







 超级会员免费看
超级会员免费看
 本文探讨了Hive在不同版本中与MapReduce、Spark、Tez的关系,强调了Hive-on-MR在新版本中的弃用。在实践中,作者展示了创建Hive表、执行查询的过程,并指出Hive将数据存储在HDFS的路径。同时,文章揭示了Hive默认使用Derby存储元数据,但Derby不支持多客户端共享,导致无法同时启动多个Hive客户端,因此建议将元数据存储改为MySQL。
本文探讨了Hive在不同版本中与MapReduce、Spark、Tez的关系,强调了Hive-on-MR在新版本中的弃用。在实践中,作者展示了创建Hive表、执行查询的过程,并指出Hive将数据存储在HDFS的路径。同时,文章揭示了Hive默认使用Derby存储元数据,但Derby不支持多客户端共享,导致无法同时启动多个Hive客户端,因此建议将元数据存储改为MySQL。
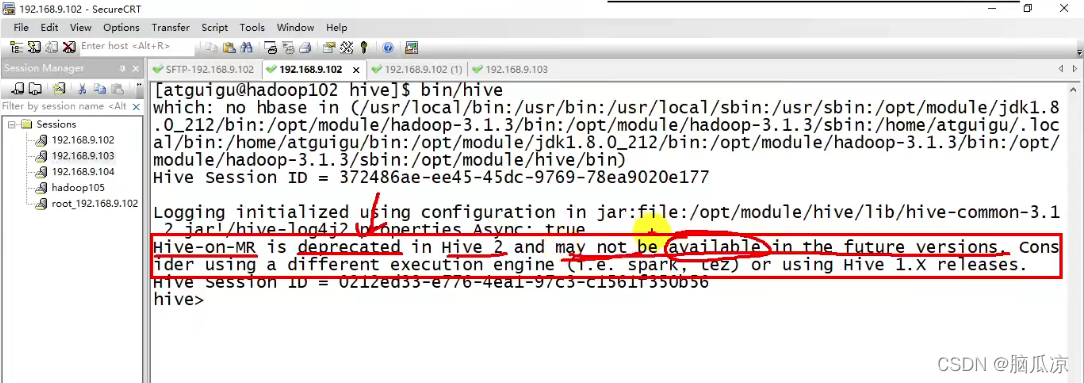
上一节我们按照了hive,然后我们启动看看,
bin/hive
可以看到说hive-on-mr这个已经是不被期望实用的,在hive2版本中,也许会在将来版本中不支持了
也就是说,我们知道hive是基于hadoop集群的,hive运行在hadoop的MapReduce计算框架上的.
但是hive-on-mr是早期版本这样用,现在不推荐这样,现在主要是,可以在spark,以及tez的基础上
运行对吧.
或者说,你可以继续使用hive的1.x版本也可以,这个是支持hive-on-mr,也就是让hive在hadoop集群
中执行.
这里我们就知道了,hive,有一套自己的sql,它仅仅是有一套自己的sql机制,依据这套sql机制会生成一个个的map,reduce任务,然后hive要依赖于,hadoop的计算能力,或者spark,或者tez的计算能力.
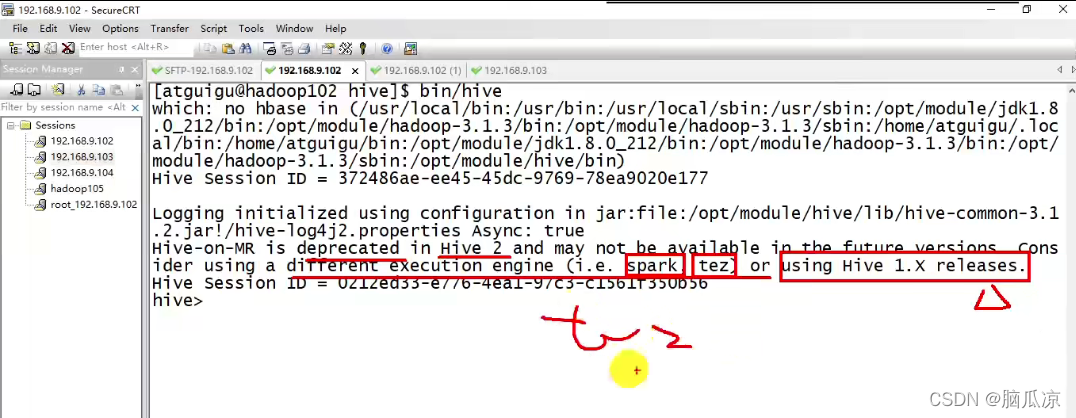
所以可以看到上面说了,早期版本,hive要依赖于hadoop的MapReduce,
这个在hive 1.

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











