







 超级会员免费看
超级会员免费看
 本文通过一个简单的Word Count案例,介绍如何使用Spark框架进行大数据处理。首先展示了包含hello scala和hello spark的两个文本文件,然后阐述了统计单词频率的步骤:列出所有单词、合并相同单词并计算数量。这是理解Spark工作原理的一个基础实践。
本文通过一个简单的Word Count案例,介绍如何使用Spark框架进行大数据处理。首先展示了包含hello scala和hello spark的两个文本文件,然后阐述了统计单词频率的步骤:列出所有单词、合并相同单词并计算数量。这是理解Spark工作原理的一个基础实践。
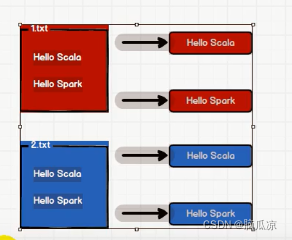
然后在做案例之前,我们先来去分析一案例。
可以看到左边有两个文件,一个是1.txt,一个是2.txt,每个文件当中都有两句话,一句话是hello scala,一句话是hello spark。我们就是要把这几句话中的单词都统计出来。
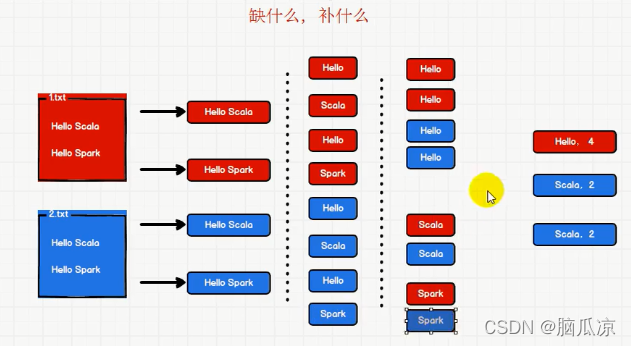
要统计出来这两个文件中所出现的单词的频率,
首先我们可以把两个文件中所有的单词都列出来,然后我们把所有的单词,相同的单词放在一块
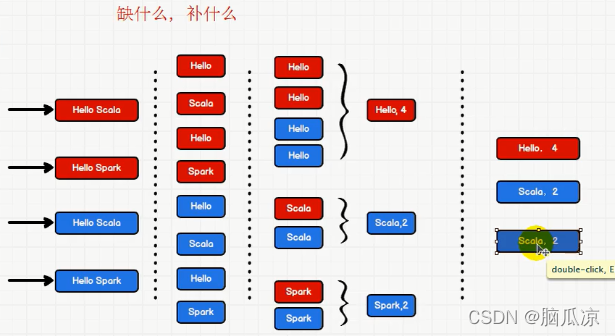
把单词放在一块了以后
然后我们就可以去统计所有单词的数量了
这就是我们实现这个案例的思路;
技术交流QQ群【JAVA,C++,Python,.NET,BigData,AI】:170933152
优快云账号:脑瓜凉
开通了个人技术微信公众号:脑瓜凉,有需要的朋友可以添加相互学习



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











