







 超级会员免费看
超级会员免费看
 本文详细介绍了Hadoop3.x中MapReduce的ReduceTask工作机制,包括数据拉取、合并排序和Reduce阶段。ReduceTask的并行度可设置,通过实验发现设置为16时处理时间最短。根据集群性能和任务需求选择合适的ReduceTask数量,处理数据倾斜问题,并讨论全局排序与汇总场景下的设置策略。
本文详细介绍了Hadoop3.x中MapReduce的ReduceTask工作机制,包括数据拉取、合并排序和Reduce阶段。ReduceTask的并行度可设置,通过实验发现设置为16时处理时间最短。根据集群性能和任务需求选择合适的ReduceTask数量,处理数据倾斜问题,并讨论全局排序与汇总场景下的设置策略。
然后我们继续看一下maptask的工作机制,这个前面也有提过了,
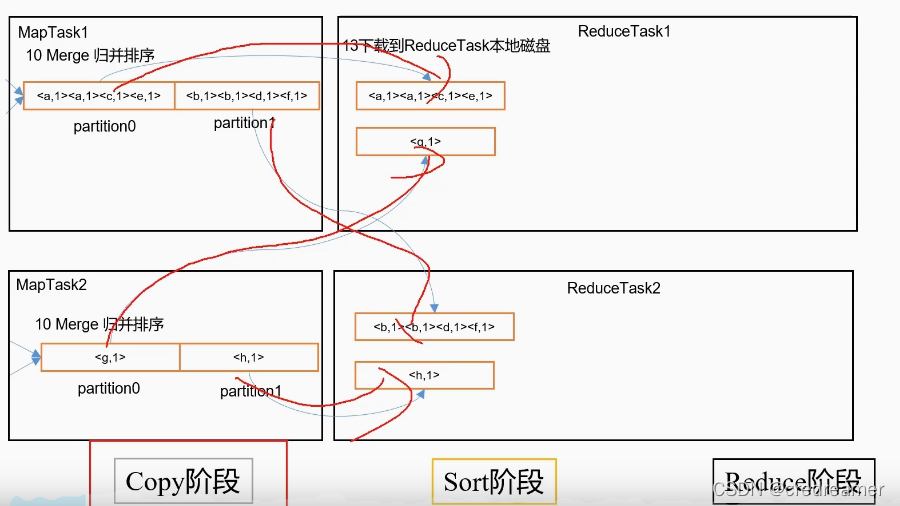
可以看到左边是maptask处理完的数据,然后到了reduceTask阶段,会首先把数据
拉取过来当然,是按照分区拉取的对吧.这是copy阶段
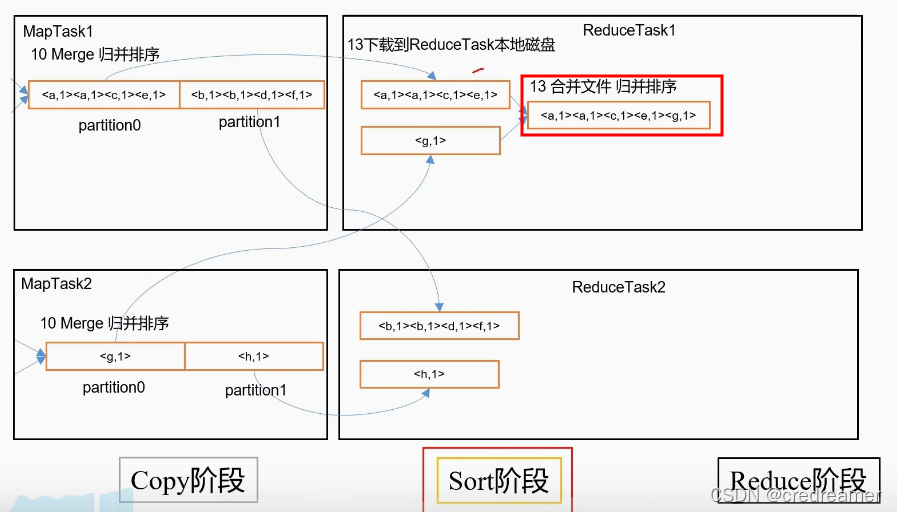
数据拿过来以后,对数据进行合并归并排序,可以看到,不同maptask中的,分区0,会给弄到一个
reduceTask中去,合并排序,同理,分区1,会弄到一个reduceTask2中....
这个阶段是sort阶段.
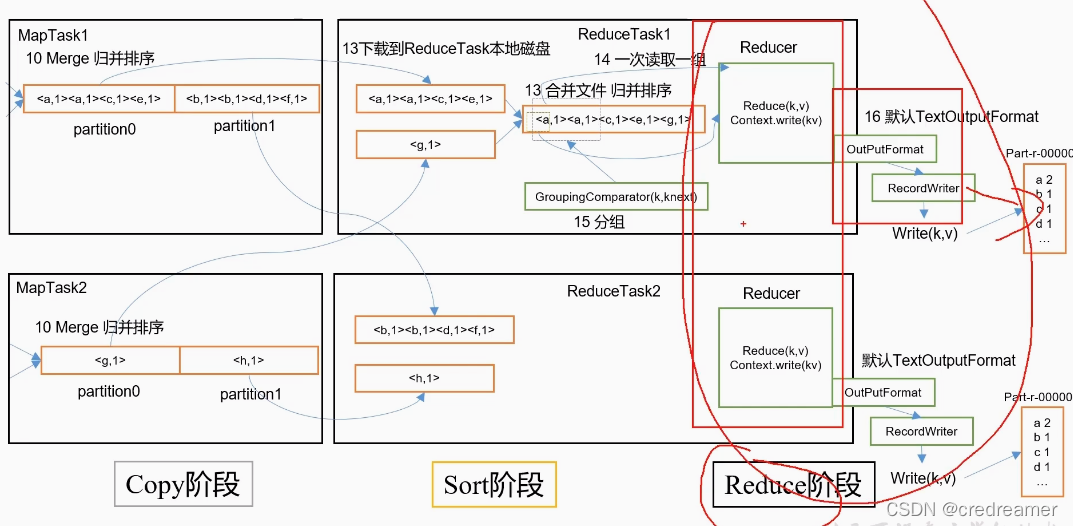
归并排序后的数据,同样的key,会一块输入到reducer中去,处理,然后利用outputformat,
把数据结果输出到文件,这个过程就是reduce阶段了.

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











