







 超级会员免费看
超级会员免费看
 本文介绍了如何使用Hadoop3.x的MapReduce进行分区排序,具体实现了一个需求,即根据手机号前缀将数据分成不同分区,并在每个分区内部按照总流量降序、上行流量升序排序。通过创建自定义分区类`ProvincePartitioner2`,并设置分区数和任务,成功实现了预期的分区和排序效果。
本文介绍了如何使用Hadoop3.x的MapReduce进行分区排序,具体实现了一个需求,即根据手机号前缀将数据分成不同分区,并在每个分区内部按照总流量降序、上行流量升序排序。通过创建自定义分区类`ProvincePartitioner2`,并设置分区数和任务,成功实现了预期的分区和排序效果。
然后我们继续看,上一节,我们用二次排序,对,按照总流量倒序的基础上,如果总流量一样,我们
按照上行流量的升序又排序了一下,然后,这一次我们又有了新的需求,我们希望,
我们136开头的,放到一个分区文件中去,137开头的,放到一个文件中去,138开头的手机号,放到一个
分区文件中去,139的放到一个分区文件中去,然后其他的开头的,放到一个分区文件中去,这样怎么弄?
并且我们要求,每个结果文件的,内部都是有序的对吧.
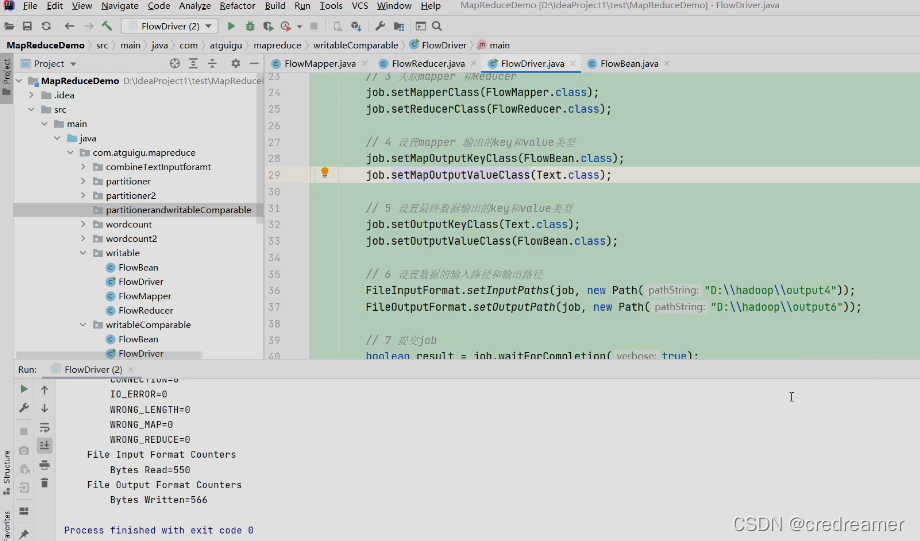
我们去实现一下,首先我们去新建一个包,
partitionerandwritableComparable这个包
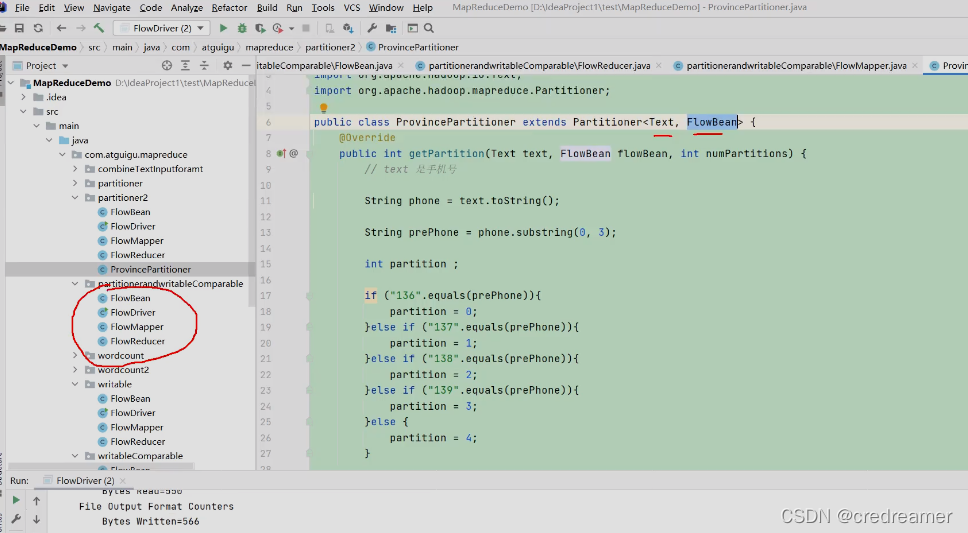
然后我们把之前的writableComparable的包中的程序文件,都copy过来,这样少写一些代码

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











