







 超级会员免费看
超级会员免费看
 本文介绍了如何使用Hadoop3.x的MapReduce实现二次排序。在之前的实践中,我们完成了全排序,将手机号及总流量进行了倒序排列。现在,我们将进一步实现,当总流量相同时,依据上行流量进行正序排序。通过修改实体类,当总流量(sumFlow)相等时,根据上行流量(upFlow)进行比较,确保在总流量相同的情况下,上行流量正序排列。经过调整,最终结果展示出预期的排序效果。
本文介绍了如何使用Hadoop3.x的MapReduce实现二次排序。在之前的实践中,我们完成了全排序,将手机号及总流量进行了倒序排列。现在,我们将进一步实现,当总流量相同时,依据上行流量进行正序排序。通过修改实体类,当总流量(sumFlow)相等时,根据上行流量(upFlow)进行比较,确保在总流量相同的情况下,上行流量正序排列。经过调整,最终结果展示出预期的排序效果。
前面我们已经利用MapReduce实现了,自定义的全排序,那么如果我们
想实现二次排序怎么做,先看看需求,
我们之前做的程序,第一次实现的是,把手机号一样的,上行流量,下行流量,总流量合计出来,
上一节我们用的全排序,是把所有手机号的,总流量倒序排了一下输出了,然后
这次,我们要二次排序,也就是如果我们判断了,总流量一样的话,我们再去按照,上行流量
正序去排序.
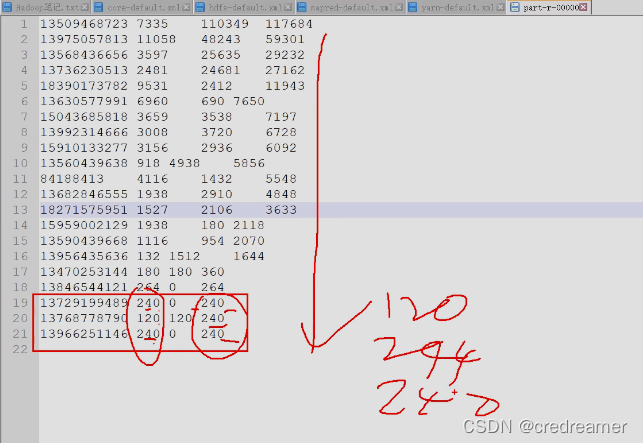
可以看到上面是上次我们输出的文件,可以看到,总流量都是240的时候,上行流量,他们分别是
240 120 240 是没有顺序的对吧,
我们希望,如果总流量一样,上行流量是正序的是:
120,240,240这样
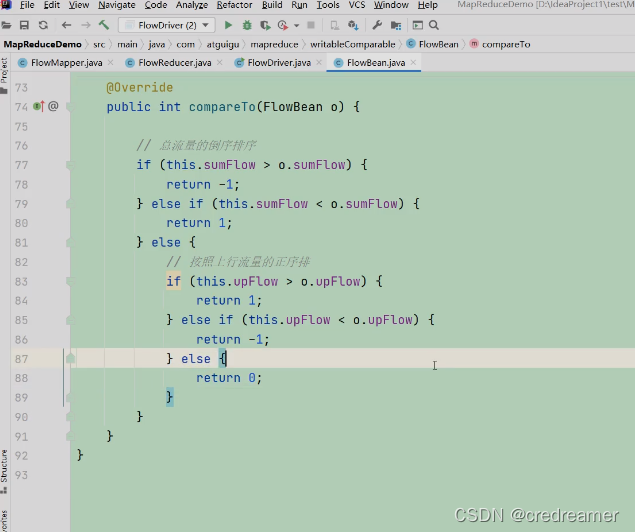
其实很简单,还是去修改我们的实体类,可以看到,如果sumFlow一样,也就是this.sumFlow = o.sumFlow的时候,那么再去判断,upFlow对吧,可以看到上面,sumFlow一样,又按照,
upFlow去排序了一下对吧,当this.upFlow > o.upFlow的时候,返

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











