







 超级会员免费看
超级会员免费看
 本文探讨了在Hadoop MapReduce中,设置不同数量的reduce任务(分区数)对执行的影响。当设置的分区数少于实际需要的分区时,会导致IO异常;设置为1则所有数据由一个reduce处理,生成一个分区文件;若分区数大于实际需求,会创建空的分区文件,造成资源浪费。自定义分区类时,分区号需从0开始且连续。
本文探讨了在Hadoop MapReduce中,设置不同数量的reduce任务(分区数)对执行的影响。当设置的分区数少于实际需要的分区时,会导致IO异常;设置为1则所有数据由一个reduce处理,生成一个分区文件;若分区数大于实际需求,会创建空的分区文件,造成资源浪费。自定义分区类时,分区号需从0开始且连续。
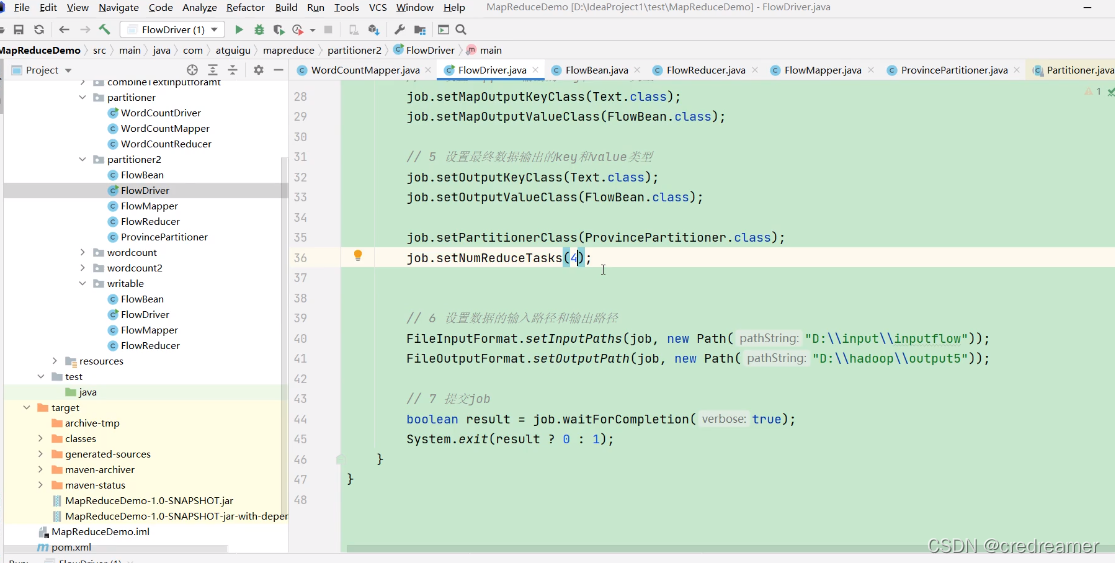
1.然后我们再来看,上一节我们执行的时候设置的job.setNumReduceTasks(5),我们分成了5个分区,那么如果我们设置成4,可以看到上面
会怎么样?
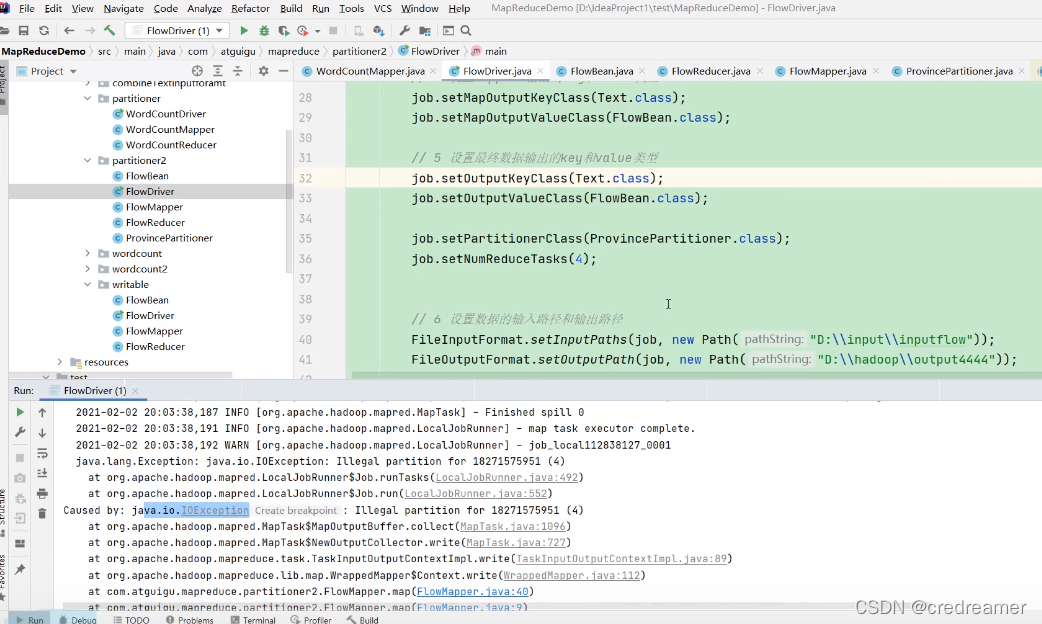 2.设置以后执行可以看到,报错了对吧,报的是io异常,为什么?
2.设置以后执行可以看到,报错了对吧,报的是io异常,为什么?
因为我们我们如果设置4,但是我们自定义的partitioner中,是需要5的,这个时候去找5,这个分区文件就找不到自然就报错了.
去5分区,写数据的时候,没办法写就报io异常了.
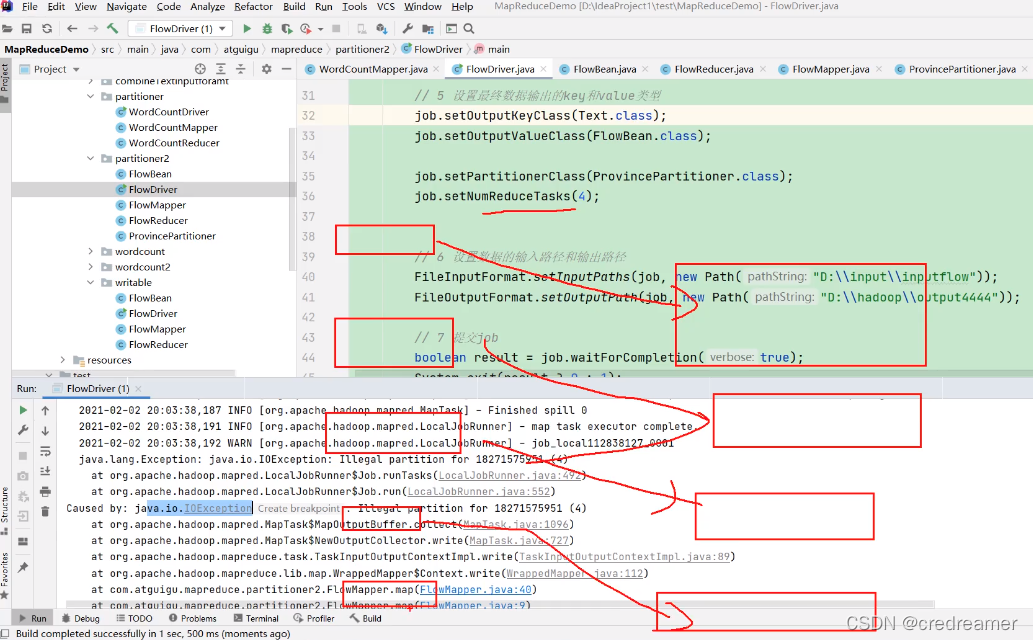
3.上面是分析,可以看到没有5分区,非要向5分区中写入数据就报错了io异常.
1.然后我们再来看,上一节我们执行的时候设置的job.setNumReduceTasks(5),我们分成了5个分区,那么如果我们设置成4,可以看到上面
会怎么样?
2.设置以后执行可以看到,报错了对吧,报的是io异常,为什么?
因为我们我们如果设置4,但是我们自定义的partitioner中,是需要5的,这个时候去找5,这个分区文件就找不到自然就报错了.
去5分区,写数据的时候,没办法写就报io异常了.
3.上面是分析,可以看到没有5分区,非要向5分区中写入数据就报错了io异常.

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























