







 超级会员免费看
超级会员免费看
 本文详细介绍了Hadoop3.x中MapReduce的工作流程,包括数据切片、任务提交给YARN、MapTask的启动、数据处理、环形缓冲区的工作原理、数据排序与合并、以及ReduceTask的执行过程。重点讲解了环形缓冲区的溢写策略和数据的归并排序,确保相同Key的数据被放到一起,以便于Reduce阶段的处理。
本文详细介绍了Hadoop3.x中MapReduce的工作流程,包括数据切片、任务提交给YARN、MapTask的启动、数据处理、环形缓冲区的工作原理、数据排序与合并、以及ReduceTask的执行过程。重点讲解了环形缓冲区的溢写策略和数据的归并排序,确保相同Key的数据被放到一起,以便于Reduce阶段的处理。
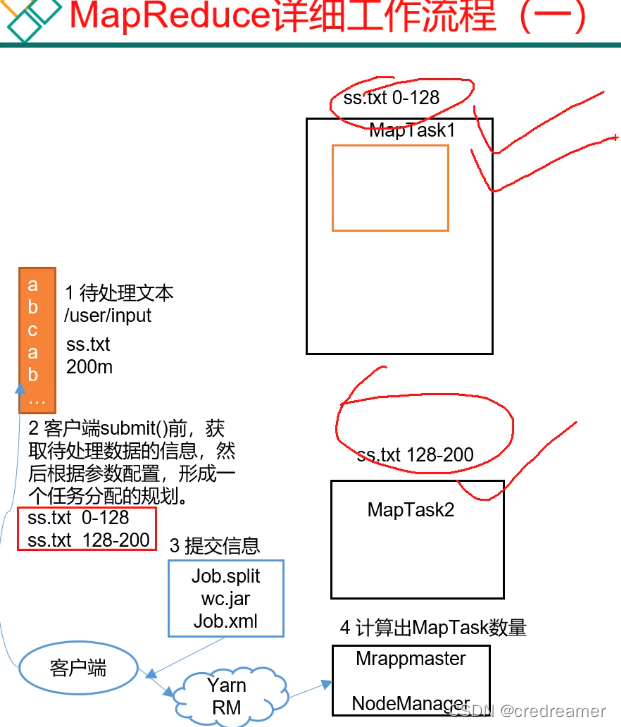
1.然后我们再去看MapReduce的详细工作流程,可以看到比如首先我们有个200m的文件ss.txt,然后首先,我们写的客户端程序,首先去
获取待处理的数据,然后根据参数配置,形成任务规划,实际上就是切片对吧.
2.然后客户端把切片好的信息,提交给yarn,这里提交的信息有job.split用来分片的,wc.jar是我们自己的处理数据的jar包,然后job.xml是
我们这个程序中配置的一些参数.
3.然后提交给yarn rm 以后,然后会首先提交给这个mrappmaster,然后我们之前说结构的时候说过,这个mrappmaster就是系统的老大,他会
去根据提交的信息,去读取有几个切片,然后开启对应的maptask去处理数据.可以看到上面就开启了两个maptask对吧.
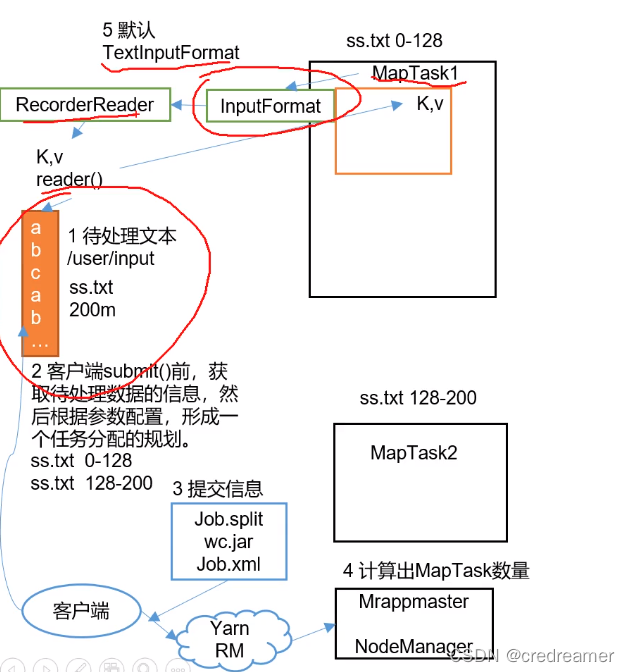
4.然后maptask启动以后,他首先就去找inputformat对吧,这个inputformat我们说默认加载的是TextInputFormat对吧,然后这TextInputFormat有两个
方法,一个是RecorderReader,一个是isSplitable,是否可切割对吧,然

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











