







 超级会员免费看
超级会员免费看
 本文探讨Hadoop3.x中的MapReduce框架,重点在于MapTask和ReduceTask的工作原理。MapTask通过InputFormat组件自定义数据输入格式,并使用Mapper进行处理,接着通过shuffle过程进行排序、分区和压缩。ReduceTask利用OutputFormat将结果写入文件或数据库。MapTask的数量决定了数据处理的并行度,但过多或过少都会影响效率。数据切片逻辑上分配数据,确保快速读取,切片大小通常与HDFS块大小一致,以优化读取性能。
本文探讨Hadoop3.x中的MapReduce框架,重点在于MapTask和ReduceTask的工作原理。MapTask通过InputFormat组件自定义数据输入格式,并使用Mapper进行处理,接着通过shuffle过程进行排序、分区和压缩。ReduceTask利用OutputFormat将结果写入文件或数据库。MapTask的数量决定了数据处理的并行度,但过多或过少都会影响效率。数据切片逻辑上分配数据,确保快速读取,切片大小通常与HDFS块大小一致,以优化读取性能。
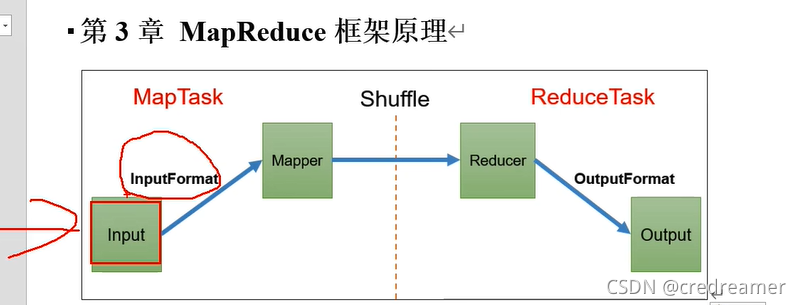
然后我们来看MapReduce的框架原理,这里是很重要的,其中MapTask用来处理map阶段的任务,
然后reduceTask用来处理reduce阶段的任务.
那么MapTask主要做了什么事呢?首先他决定了,数据输入的格式,比如,默认的输入可是是k,v的
格式,这里的k,就是输入文本中的,行号,也叫偏移量,然后v是一行的内容.
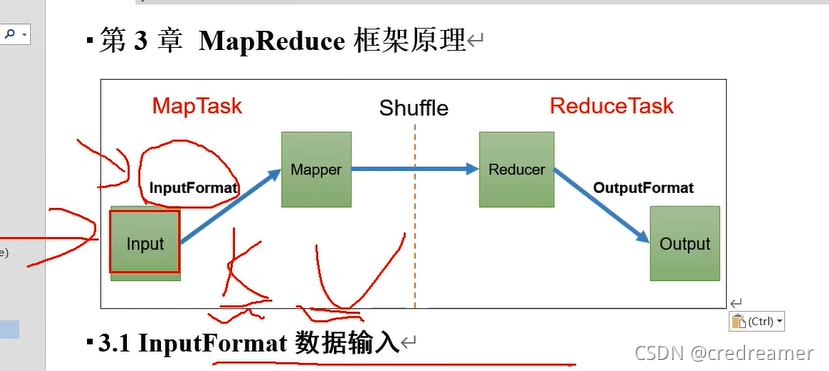
那么问题来了,既然默认的maptask的读入数据的格式是k,v格式的,而且k就是偏移量就是行号,v
就是一行的内容,那么可不可以修改呢,比如想让他按照自己想要的格式读入,其实是可以的,这里有个
组件是InputFormat组件,这个组件就是输入格式组件,这个就允许我们自己定义读入数据的格式.
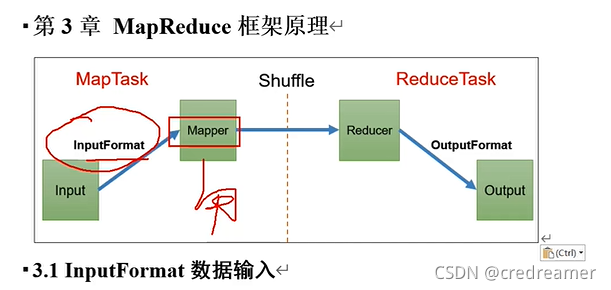
然后MapTask通过InputFormat组件,

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











