







 超级会员免费看
超级会员免费看
 本文介绍了如何在Hadoop3.x环境中实现MapReduce的序列化,以FlowBean类为例,详细讲解了实现writable接口、编写write和readFields方法、提供构造函数以及定义相关属性和方法的步骤。强调了序列化过程中属性读写顺序的重要性,并给出了toString方法的实现,便于查看和理解序列化结果。
本文介绍了如何在Hadoop3.x环境中实现MapReduce的序列化,以FlowBean类为例,详细讲解了实现writable接口、编写write和readFields方法、提供构造函数以及定义相关属性和方法的步骤。强调了序列化过程中属性读写顺序的重要性,并给出了toString方法的实现,便于查看和理解序列化结果。
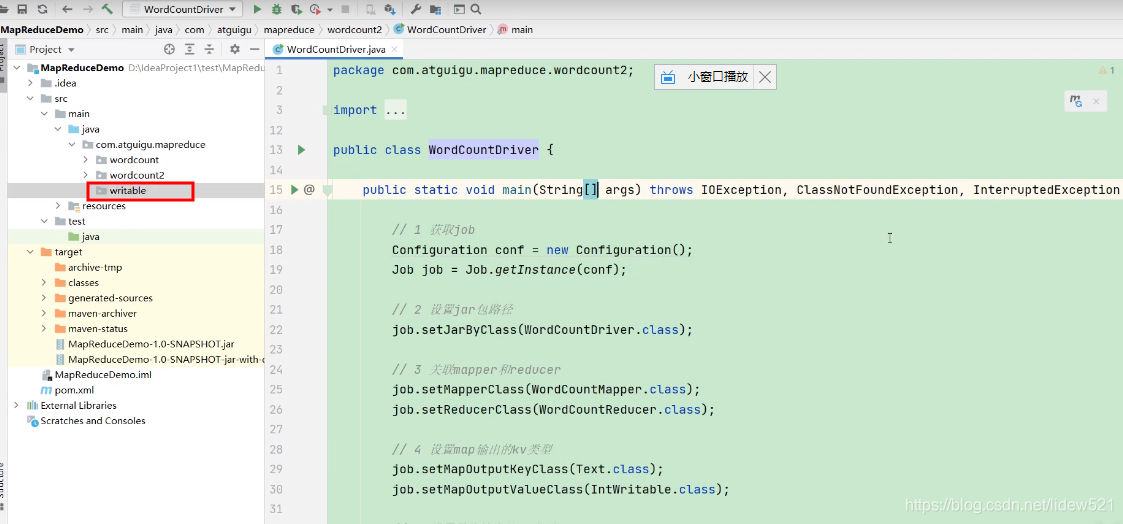
然后我们再来看,我们来写一下这个FlowBean,其实就是我们之前分析,这个hadoop序列化案例的时候,那个
用来承接上行流量,下行流量,总流量的,这个类,我们要为这个类实现hadoop的序列化.
好,首先我们去新建一个包:com.atguigu.mapreduce.writable
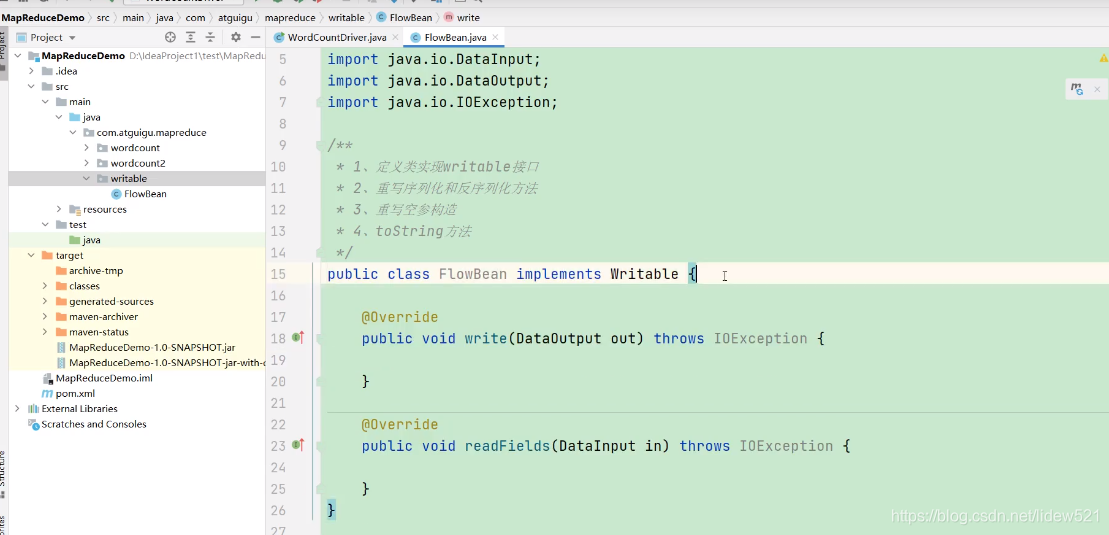
然后去新建一个类FlowBean,这个类中,我们通过上面的4步来实现这个FlowBean类.
可以看到首先我们去实现writable的接口
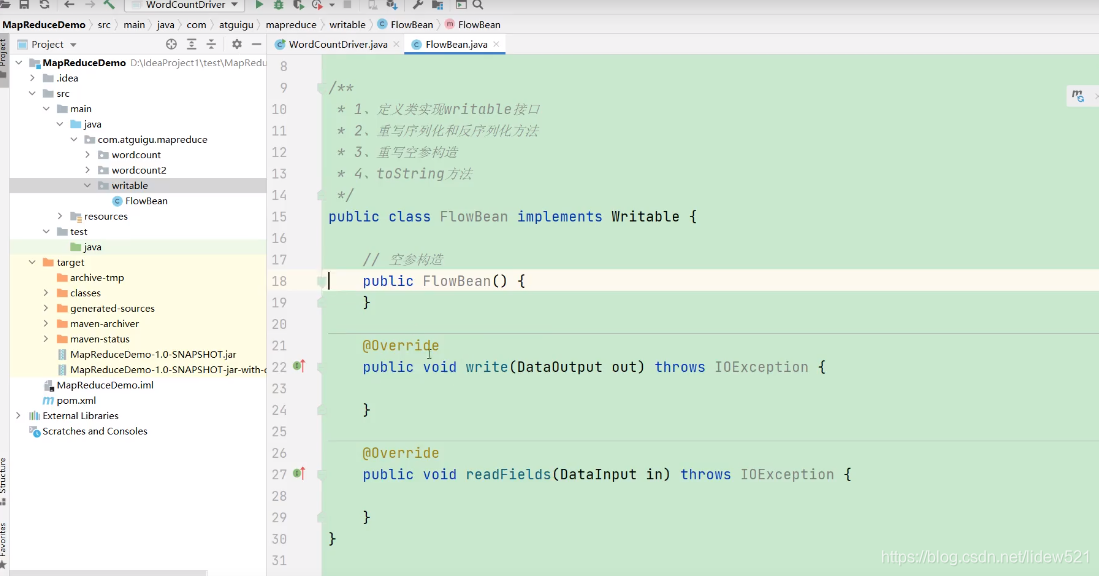
然后第二步我们重写write方法,有个readFields方法,重写这两个方法.
然后第三步,再去提供一个空参构造方法

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











