







 超级会员免费看
超级会员免费看
 本文详细介绍了在Hadoop3.x中编写MapReduce程序的规范,包括Mapper和Reducer的实现,以及MapTask和ReduceTask的工作过程。Mapper类需要继承Hadoop提供的基类,输入为k,v对,业务逻辑在map方法中处理。Reducer同样继承Reducer类,输入是Mapper的输出,业务逻辑在reduce方法中执行。最后,Driver部分负责将整个程序提交给YARN集群进行计算。"
89207267,7265809,使用数位DP解决包含2018的数的数量,"['动态规划', '算法', '搜索算法', '编程问题', '数学']
本文详细介绍了在Hadoop3.x中编写MapReduce程序的规范,包括Mapper和Reducer的实现,以及MapTask和ReduceTask的工作过程。Mapper类需要继承Hadoop提供的基类,输入为k,v对,业务逻辑在map方法中处理。Reducer同样继承Reducer类,输入是Mapper的输出,业务逻辑在reduce方法中执行。最后,Driver部分负责将整个程序提交给YARN集群进行计算。"
89207267,7265809,使用数位DP解决包含2018的数的数量,"['动态规划', '算法', '搜索算法', '编程问题', '数学']

然后我们再来看看,如果我们自己去写一个MapReduce的程序,我们应该注意一些什么,
首先如果我们要写一个Mapper的话
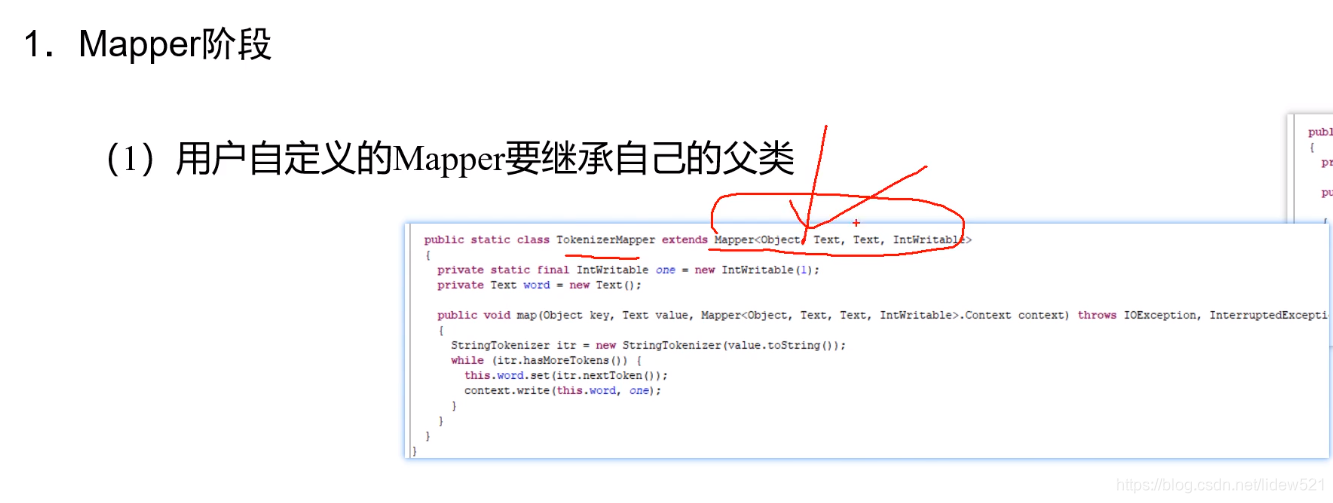
可以看到,首先我们自己写的Mapper这个类要继承hadoop提供的mapper类
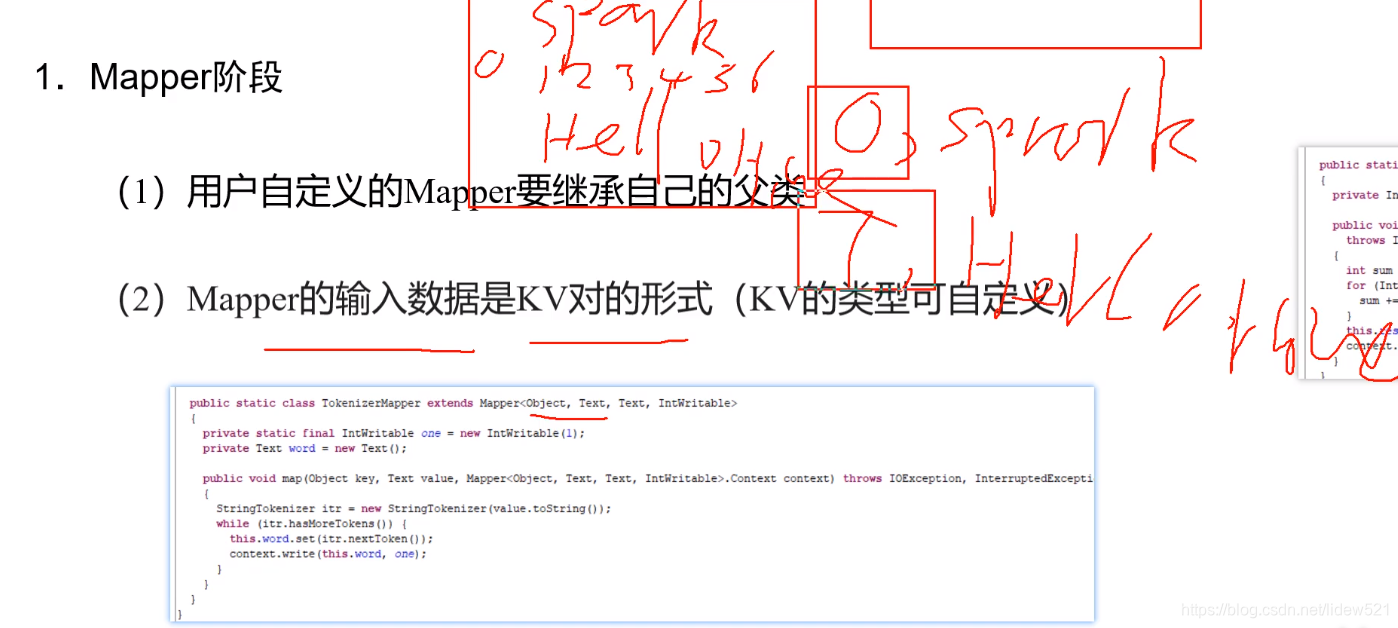
然后对于Mapper的输入是k,v对的形式,什么意思,就是说,MapReduce处理的时候,map处理的输入是个
k,v对的形式的数据,输入的,比如:
spark hello 如果一行的数据是这样的话,根据下标,0是开始位置,s表示下标1,p表示下标2,a表示下标3,r表示下标4,k表示下标5,空格是下标6,
h是下标7.
0123456789
那么作为一个输入的数据,就是0

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











