







 超级会员免费看
超级会员免费看
 本文介绍了Hadoop MapReduce的工作原理,通过举例说明如何将任务拆分成多个小任务并行处理,再通过Reduce阶段合并结果,提升计算速度。Map阶段将数据切分为128M块并行处理,Reduce阶段的并发任务也可并行执行。然而,MapReduce仅支持一个Map和一个Reduce阶段,若业务逻辑复杂,需要多个步骤处理,会导致效率降低,此时更适合使用Spark等支持内存处理的框架。
本文介绍了Hadoop MapReduce的工作原理,通过举例说明如何将任务拆分成多个小任务并行处理,再通过Reduce阶段合并结果,提升计算速度。Map阶段将数据切分为128M块并行处理,Reduce阶段的并发任务也可并行执行。然而,MapReduce仅支持一个Map和一个Reduce阶段,若业务逻辑复杂,需要多个步骤处理,会导致效率降低,此时更适合使用Spark等支持内存处理的框架。
然后我们再来看一下这个MapReduce是如何工作的,再说一遍吧,这个MapReduce,已经说了n遍了,这里大体再说一遍.
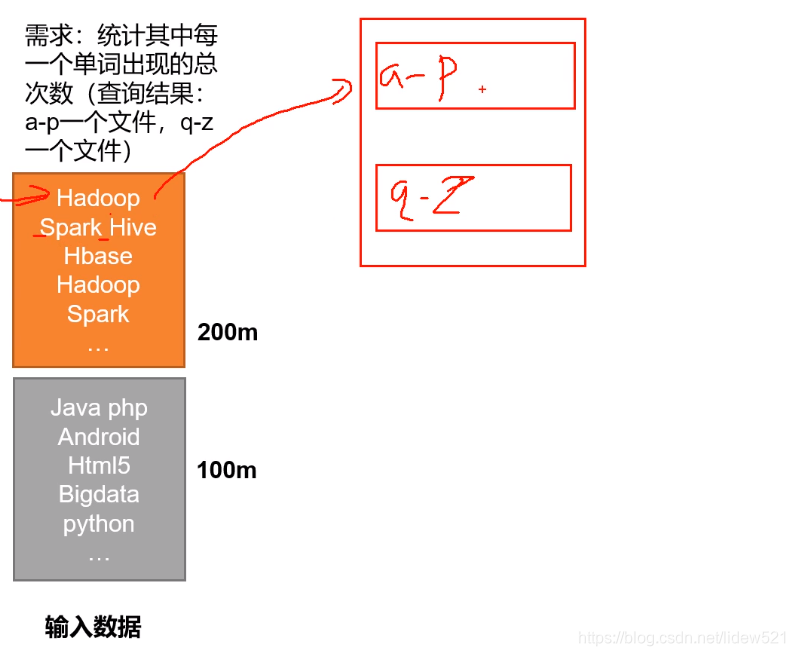
比如上面我们有个需求,我们需要把统计两本书中的,a-p 开头的单词出现的个数,放到一起,然后
q-z开头的单词出现的个数,放到一起,比如这里第一本书大小是200m,第二本书大小是,100m,这个时候.如果让你去做这个工作怎么做?
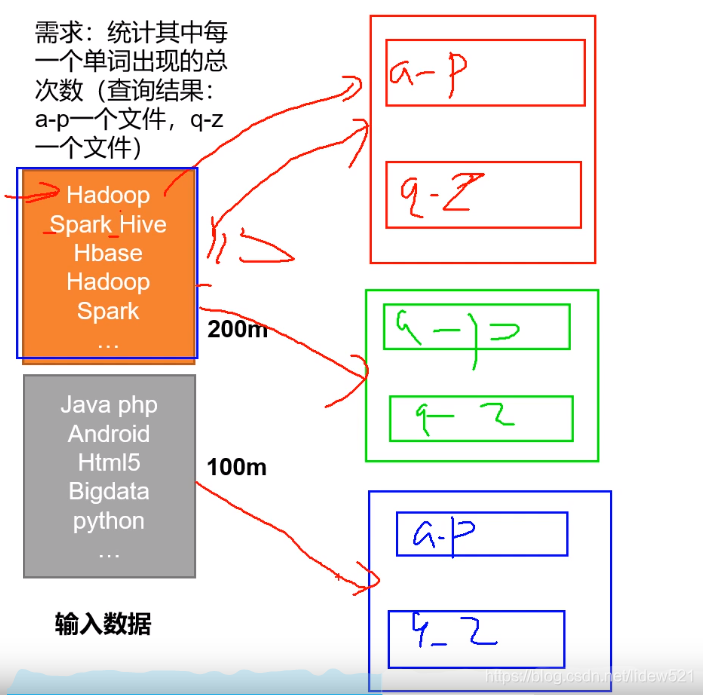
首先拿到两张纸,一张放a-p的结果,一张放q-z的统计结果,
然后去读,第一行,比如碰到了hadoop,h在a-p,就在a-p的那个纸上写上hadoop 1出现了一次了表示,
然后再去读取,Spark Hive,读到这个单词的时候,会按照空格,把spark,弄出来,然后把hive也弄出来,
把s放到q-z那张纸上去,写上spark 1,然后把hive 写到a-p那张纸上去,写上hive 1.这样来做.
但一个人做太慢了,这个是你可

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











