







 超级会员免费看
超级会员免费看
 本文详细介绍了Hadoop HDFS的读数据过程。首先,客户端通过Distributed FileSystem对象向NameNode请求文件,NameNode返回文件的元数据及最近且负载最低的DataNode。接着,客户端创建FSDataInputStream并请求DataNode1读取blk_1,依次读取所有块完成文件下载。整个过程考虑了距离和负载因素。
本文详细介绍了Hadoop HDFS的读数据过程。首先,客户端通过Distributed FileSystem对象向NameNode请求文件,NameNode返回文件的元数据及最近且负载最低的DataNode。接着,客户端创建FSDataInputStream并请求DataNode1读取blk_1,依次读取所有块完成文件下载。整个过程考虑了距离和负载因素。
然后我们再来看下,这个客户端去从hadoop的hdfs上面读取数据的一个过程.
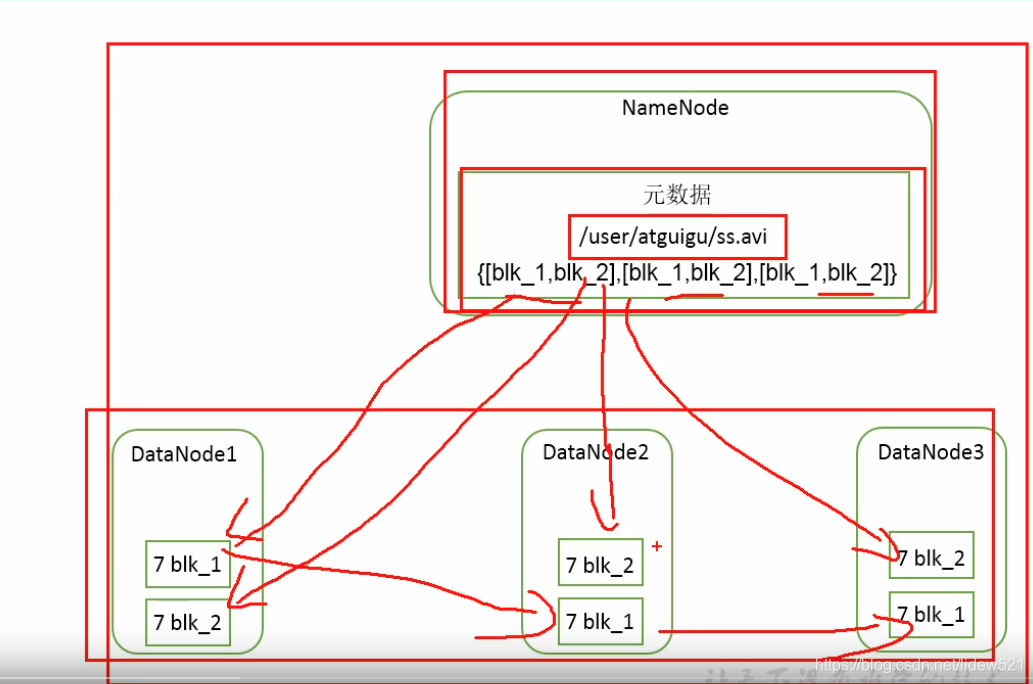
1.首先我们先看一下hadoop是怎么来存数据的.
2.首先对于namenode节点来说,我们说他存了元数据,比如他这里存了一个/usr/atguigu/ss.avi这个文件,注意他仅仅是存了一个元数据,比如名字,路径.
然后namenode还存了,比如我这个文件有两个block块,比如是blk_1,和blk_2,这两个块.然后为了安全起见,这个namenode也会把这两个块信息,存3个副本放起来.
3.然后namenode上面记录的这个文件的blk_1这个块,可以看到记录了他存在了datanode1上面一份具体的块的数据,在datanode2上面存了一份具体的块的数据,在datanode3上面存了一份具体的块的数据
4.然后同样namenode上面记录的这个文件的blk_2这个块,可以看到记录了他存在了datanode1上面一份具体的块的数据,在datanode2上面存了一份具体的块的数据,在datanode3上面存了一份具体的块的数据
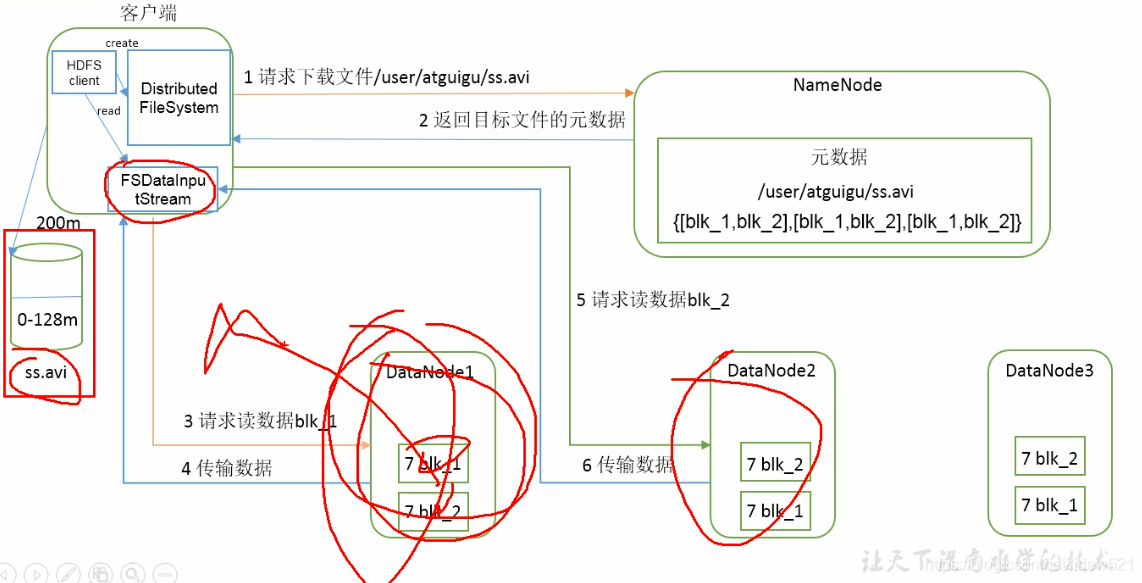
然后我们再去看文件下载的

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











