







 超级会员免费看
超级会员免费看
 本文介绍了大数据技术生态,重点讨论Hadoop在其中的角色。数据来源包括数据库、文件日志和非结构化数据。数据传输层涉及Sqoop、Hive、Flume和Kafka。Hadoop的HDFS用于存储,HBase进行列式存储。资源管理层由YARN管理,计算层包括MapReduce、Spark Core和Flink。离线计算如Hive、Mahout和Spark MLlib用于数据分析,实时计算则有Spark Streaming和Storm。任务调度层利用Oozie和Azkaban,Zookeeper用于配置管理。最后,业务模型和数据可视化将处理后的数据呈现给用户。
本文介绍了大数据技术生态,重点讨论Hadoop在其中的角色。数据来源包括数据库、文件日志和非结构化数据。数据传输层涉及Sqoop、Hive、Flume和Kafka。Hadoop的HDFS用于存储,HBase进行列式存储。资源管理层由YARN管理,计算层包括MapReduce、Spark Core和Flink。离线计算如Hive、Mahout和Spark MLlib用于数据分析,实时计算则有Spark Streaming和Storm。任务调度层利用Oozie和Azkaban,Zookeeper用于配置管理。最后,业务模型和数据可视化将处理后的数据呈现给用户。
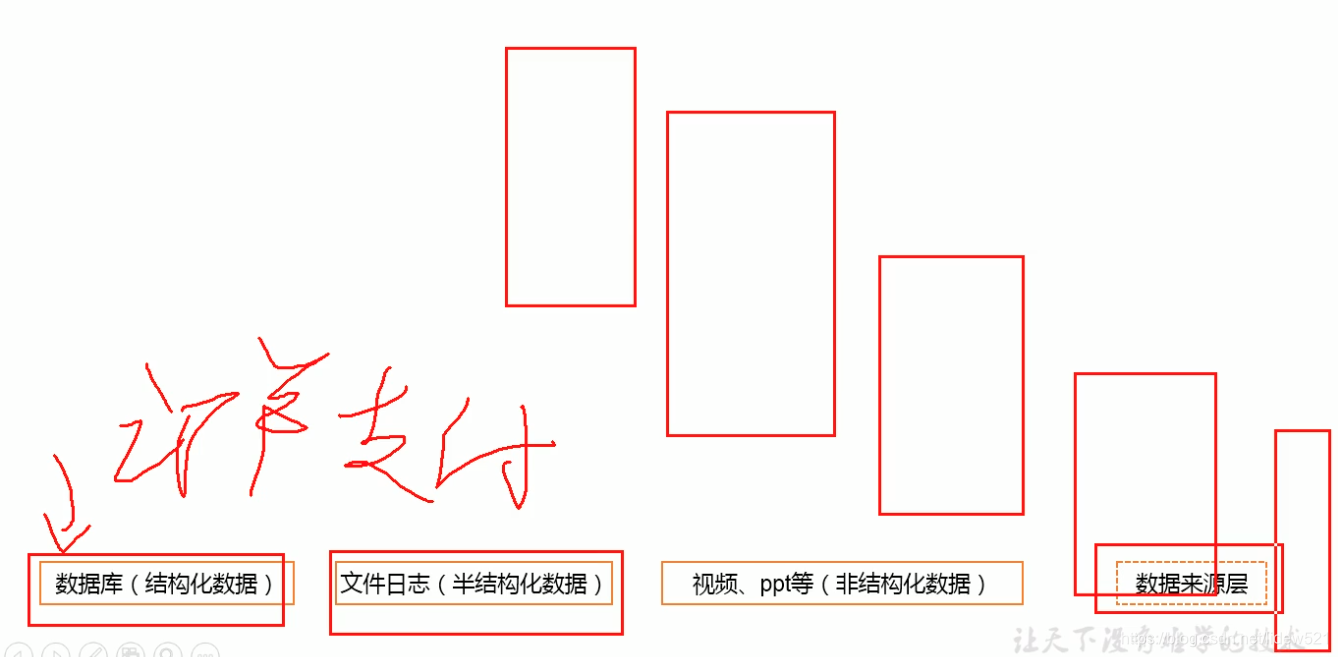
然后我们来看看,既然说到大数据,我们来看看他的整个的技术体系.
可以看到,首先最底层是数据来源层.
可以看到我们的数据,可以来至于
1.数据库,结构化的数据,比如订单信息
2.还有文件日志,半结构化的数据,比如用户的行为数据,使用习惯数据等,这种数据
3.然后还有一些文档,视频,ppt非结构化数据
这是我们数据的来源.
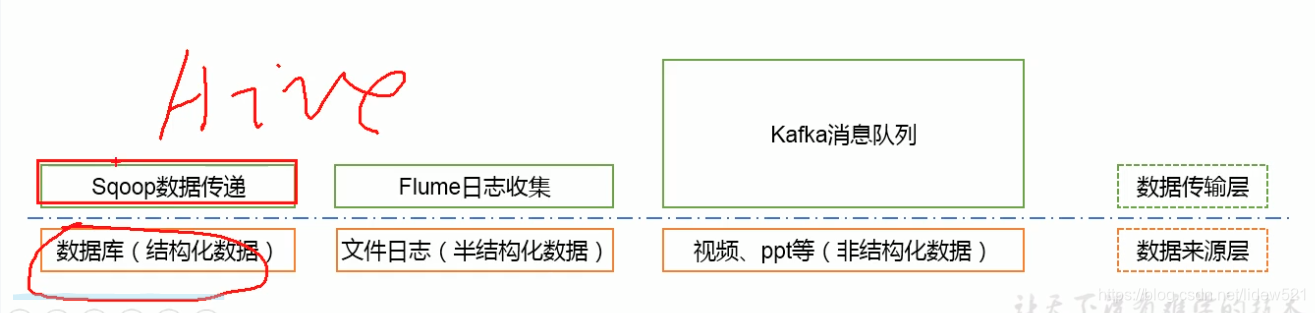
然后再上一层是数据传输层.
上面我们是收集到了数据,但是我们把数据放在哪呢?
我们知道我们需要放到hadoop的hdfs的分布式存储中去,这样的话,需要把,上面的的数据来源层的数据
通过
1.结构化的数据可以通过sqoop,把数据插入到hdfs中去
hive是对数据进行查询的,他提供了类似sql的用法,可以对hdfs中的数据进行查询.
3.然后flume可以非常方便的来获取日志信息,负责日志信息的收集
4.然后kafka是消息队列,可以用来传输各种非结构化数据,
这个是数据传输层<

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











