







 超级会员免费看
超级会员免费看
 本文介绍了Hive的架构,包括元数据存储、CLI和JDBC操作方式,以及SQL解析、编译、优化和执行的过程。Hive默认使用Derby存储元数据,但通常会配置为使用MySQL。Hive依赖Hadoop进行数据存储,其使用过程中涉及SQL创建表、导入数据到HDFS,并通过MapReduce执行查询任务。
本文介绍了Hive的架构,包括元数据存储、CLI和JDBC操作方式,以及SQL解析、编译、优化和执行的过程。Hive默认使用Derby存储元数据,但通常会配置为使用MySQL。Hive依赖Hadoop进行数据存储,其使用过程中涉及SQL创建表、导入数据到HDFS,并通过MapReduce执行查询任务。
然后我们再来看一下hive的架构
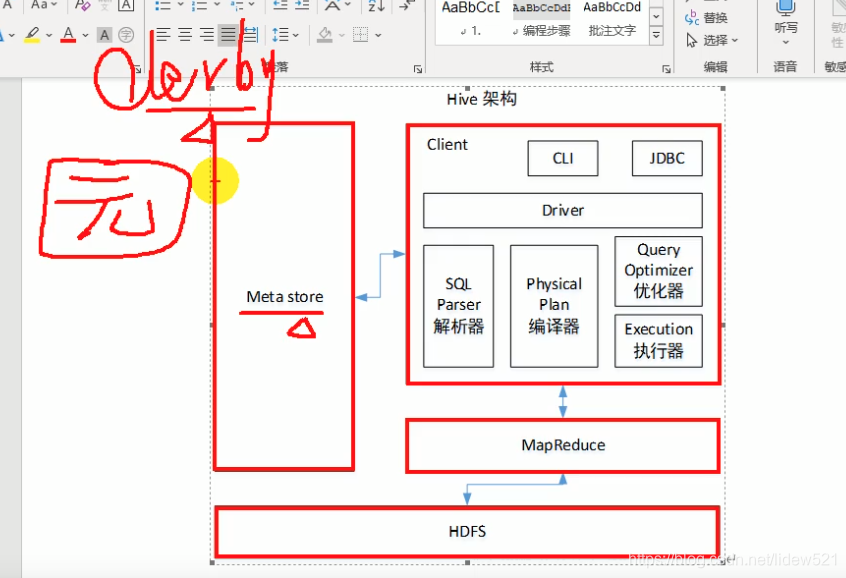
可以看到hive,左边有个元数据存储,就是存了一些元数据,通过这些元数据我们可以,找到具体我们存的实际的数据.
然后右边hive提供了cli命令行的方式操作hive以及jdbc的方式处理数据.
然后通过cli或者jdbc,连接hive以后,然后把写好的sql,经过sql parser解析器,解析sql以后,然后再编译sql,然后再优化sql,然后再去执行
sql,然后这个sql解析器,实际上做的就是把我们写的sql,转换成了mapper 和reducer,然后最终交给
mapreduce去执行,执行以后,把结果放到hdfs中去.
还要注意hive默认把元数据存到derby中去了,这个小数据库,不好用,用它还会有问题,所以后边我们会
配置这个元数据数据库,设置为mysql来用.
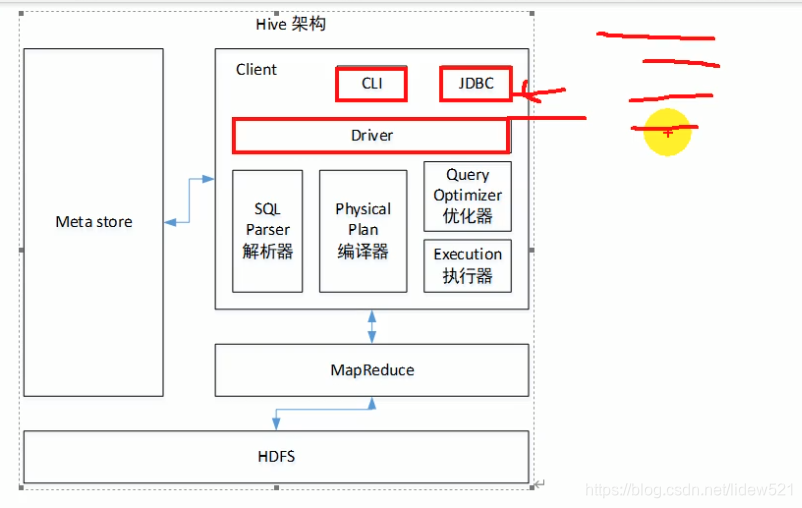
可以看到这里当需要jdbc连接hive的时候中间会用到这个hive的驱动.

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











