







 超级会员免费看
超级会员免费看
 本文探讨了Flink与Spark在流处理上的差异。Flink以其无批处理概念,实现真正毫秒级响应,而Spark基于微批处理,延迟可达数百毫秒至秒级别。Flink采用数据流模型,事件驱动,处理效率更高;Spark则依赖RDD模型和DAG划分的Stage,处理速度相对较慢。
本文探讨了Flink与Spark在流处理上的差异。Flink以其无批处理概念,实现真正毫秒级响应,而Spark基于微批处理,延迟可达数百毫秒至秒级别。Flink采用数据流模型,事件驱动,处理效率更高;Spark则依赖RDD模型和DAG划分的Stage,处理速度相对较慢。
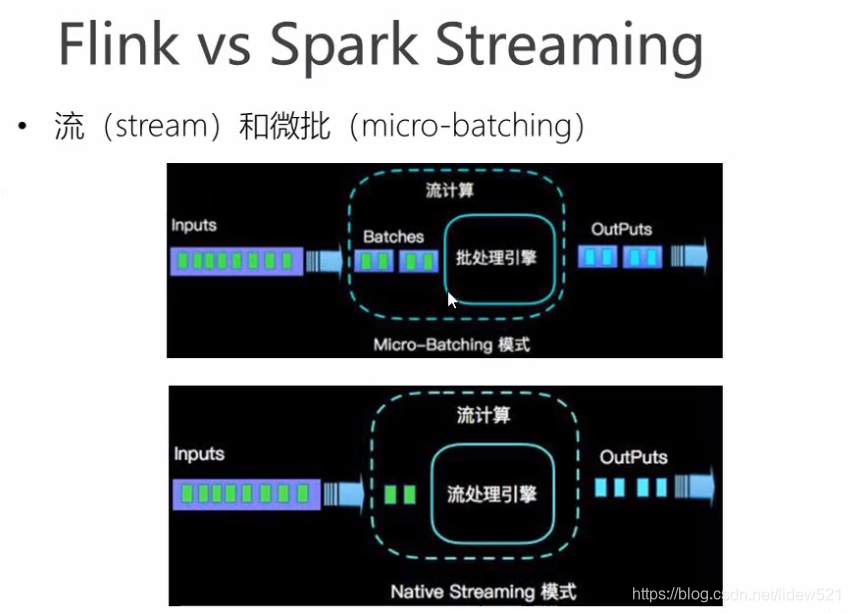
然后我们再来比较一下spark和flink,可以看到
spark是虽然也是说是做流的处理,但是spark的架构实现是,基于微批处理的,也就是
来了数据,先攒一攒,攒够了一批以后,才去处理,他的延时,可以得到几百毫秒,甚至秒级别的,主要是因为,他还是基于,批处理的概念,进行数据处理
实际上就是把这个批处理,做的足够的小.只要足够的小,速度就会快一些,但是再小,也会受限于,批处理的这种设计.
所以spark的数据处理速度还是会慢一些.
但是对于flink来说,就不一样了,他没有批处理的概念,他就是来一条数据,就处理一条数据,所以flink可以做到
真正的毫秒级的数据处理.

我们可以看到spark采用了rdd模型,RDD是个数据集,也就是说,对于spark来说,
因为rdd是个数据集合,也就是spark处理数据的时候会把数据,攒一攒再处理,所以这就是spark慢的原因.
而flink是基于数据模型的数据流,以及事件序列,这个速度快来了数据就处

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











