







 超级会员免费看
超级会员免费看
 本文介绍了HBase的数据读取流程,包括客户端如何通过ZooKeeper定位元数据,元数据在哪个regionServer上,以及数据查询的具体步骤。分析了由于这个复杂流程导致的HBase读取效率较低的问题。
本文介绍了HBase的数据读取流程,包括客户端如何通过ZooKeeper定位元数据,元数据在哪个regionServer上,以及数据查询的具体步骤。分析了由于这个复杂流程导致的HBase读取效率较低的问题。
技术交流QQ群【JAVA,C++,Python,.NET,BigData,AI】:170933152
然后我们看一下hbase的,数据读取流程
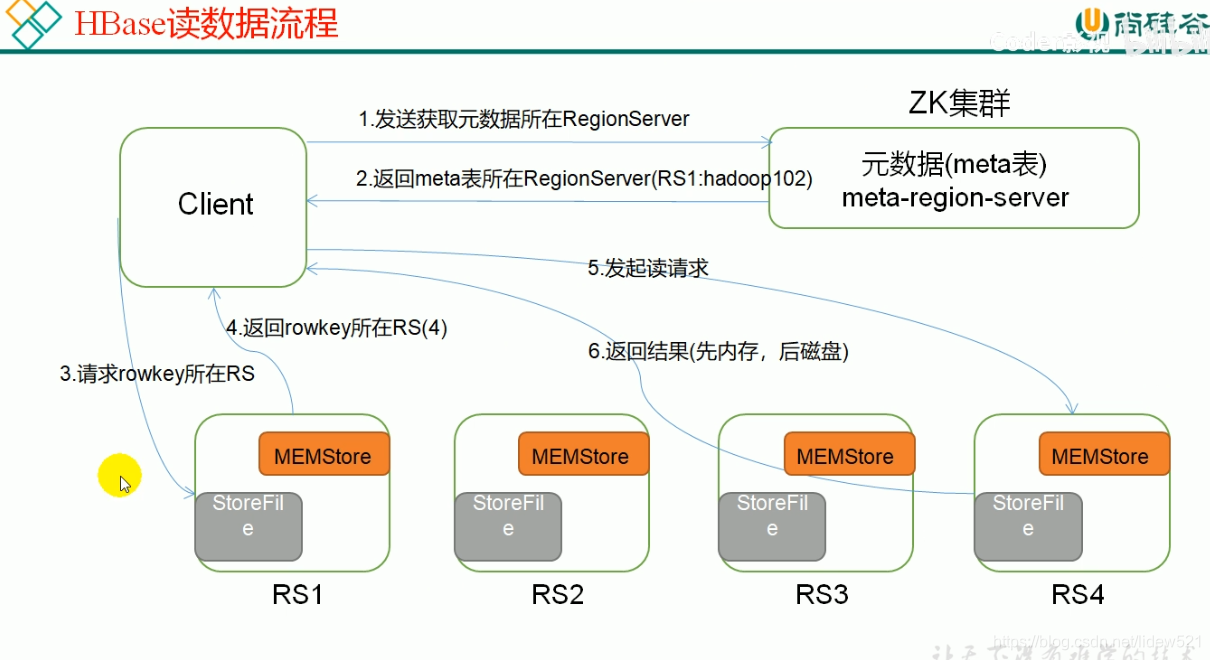
我们可以看看上面这个是hbase的读取数据的过程,这个太抽象,一会我们自己画一个
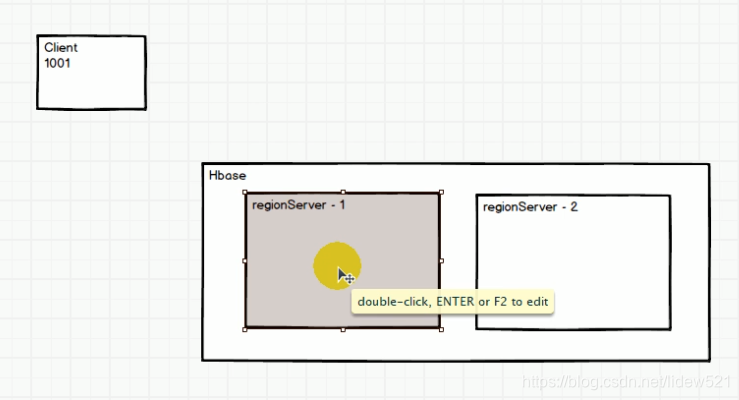
比如我们有个客户端client,他需要读取,一个表的1001 ,这个数据
但是我们知道数据是存在regionServer中的,但是reginServer有两个我们知道现在我们有1,2这两个regionServer
我们怎么知道这个数据,具体是在regionServer1上还是regionServer2上呢?
首先我们去看一下hbase的网页端.
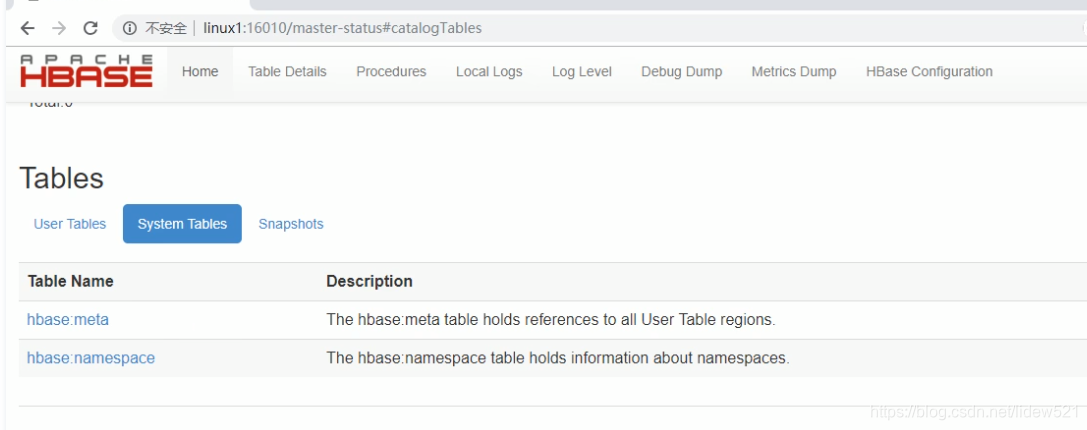
可以看到他有个
hbase:meta 这个表

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











