







 超级会员免费看
超级会员免费看
 本文分享了大数据HBase面试中可能遇到的问题,主要探讨稀疏表和密集表的区别。密集表如MySQL,所有列数据通常都存储;而稀疏表在HBase中体现,允许按需存储数据,无数据的列不占用内存,避免内存碎片,提高存储效率。
本文分享了大数据HBase面试中可能遇到的问题,主要探讨稀疏表和密集表的区别。密集表如MySQL,所有列数据通常都存储;而稀疏表在HBase中体现,允许按需存储数据,无数据的列不占用内存,避免内存碎片,提高存储效率。
技术交流QQ群【JAVA,C++,Python,.NET,BigData,AI】:170933152
记录一些面试时候可能会问道的问题,不记录,有时候现想,想出来的问题,没那么经典...可能就乱问了...不太好.
经常更新,工作中碰到觉得不错的技术要点,技术细节会记录在这里.
1.说说什么是稀疏表,什么是密集表?
然后hbase中还有个稀疏表的概念
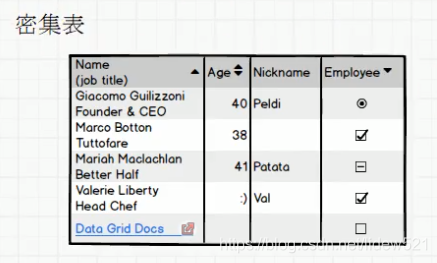
密集表是比如mysql的那种表
而稀疏表可以看看:
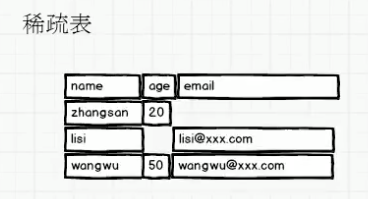
他是这样放的数据,可以看到,我虽然有3列
但是每行的数据不一样,如果我一个用户没有年龄我可以不存年龄,直接连内存都不占用.
有啥就存啥.也不会产生内存碎片的问题.虽然lisi和他的邮箱直接有空闲,但是在数据存在内存中的时候,他是连续的
像这样存数据的形式的表,叫做稀疏表.


















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











