




 本文探讨了构建垂直领域大模型的方法,包括继续预训练、领域微调数据构建、减缓幻觉及知识召回。通过继续预训练注入领域知识,结合SFT和RLHF增强模型能力。此外,介绍了Self-Instruct、Self-QA和Self-KG等数据生成技术,以及如何通过Generate with Citation、Factual Consistency Evaluation确保生成内容的准确性。垂直领域模型已在法律、医疗和教育等领域取得初步成果,有望成为解决实际问题的工具。
本文探讨了构建垂直领域大模型的方法,包括继续预训练、领域微调数据构建、减缓幻觉及知识召回。通过继续预训练注入领域知识,结合SFT和RLHF增强模型能力。此外,介绍了Self-Instruct、Self-QA和Self-KG等数据生成技术,以及如何通过Generate with Citation、Factual Consistency Evaluation确保生成内容的准确性。垂直领域模型已在法律、医疗和教育等领域取得初步成果,有望成为解决实际问题的工具。
本文将系统介绍如何做一个垂直领域的大模型,包括继续预训练,领域微调数据构建,减缓幻觉,知识召回多个方面。

通用大模型的尴尬

你会为一个闲聊的玩具买单吗?
虽然2023年以来几乎很多公司都发出了自己的通用大模型,但是都还停留在“开放闲聊”阶段,这种泛娱乐的方式是不能带来实际生产力的。所以,以“开放闲聊”为产品形态的ChatGPT,“尝鲜“的流量在6月达到巅峰之后,就开始了出现下滑。
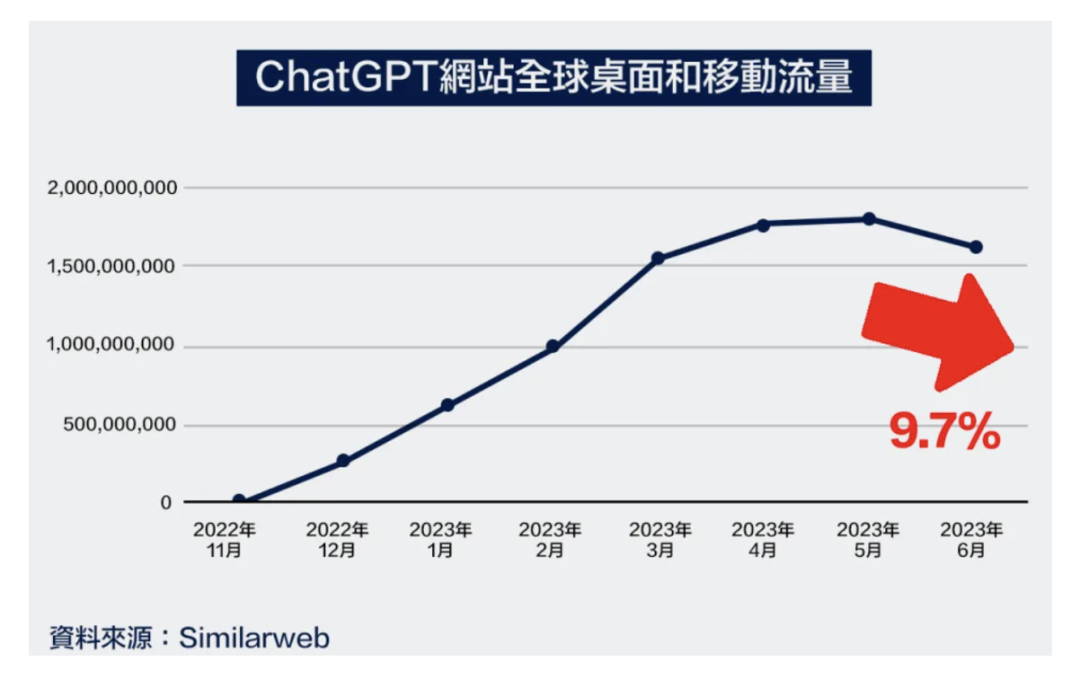
大模型不能只会开放闲聊,人们需要的是能实实在在解决问题,提高生产力和工作效率的工具。

例如我们需要一个能帮助写SQL的大模型,这个模型能跟专业的数据工程师一样,准确地给出可信赖的SQL语句,让人们放心的在生产环境执行。如果模型没理解人们的意图,或者不会写,也能进行拒识,而不是“强行”给出一个错误的SQL。
这就要求大模型能忠实于领域内的要求,同时克服“幻觉”,严谨准确地进行作答。当下作为通才的通用大模型很难有这样的能力。
垂直大模型产品
基于上面的思考,开始涌现出越来越多的垂域大模型,这些模型只针对一个特定的领域,甚至只能针对一两个场景。但是已经能初步的产品化落地,不再是一个只会「闲聊的玩具」,开始真的帮人们在解决问题。
下面是一些垂直领域大模型产品化的例子:
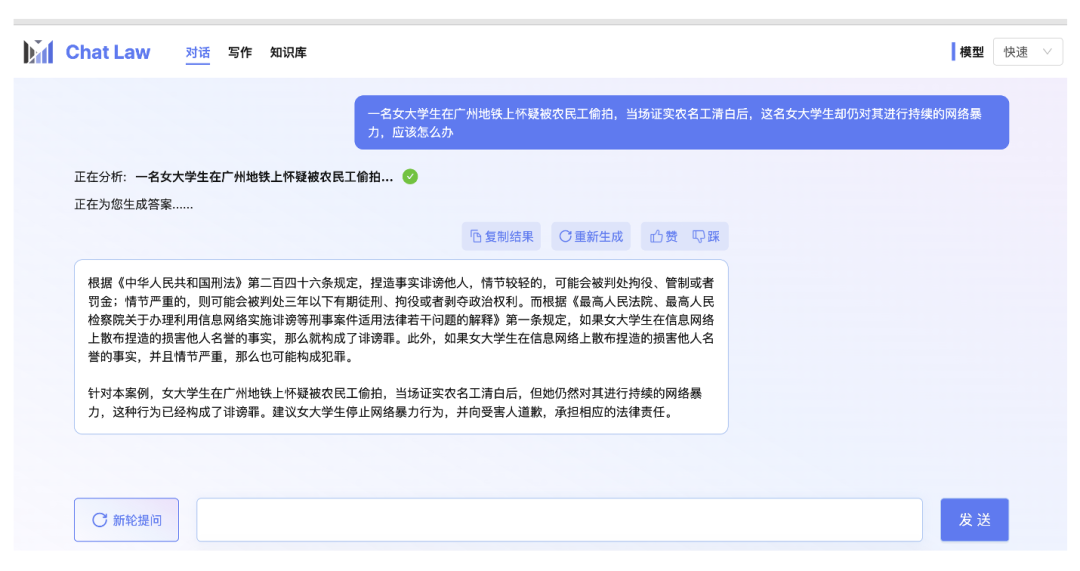
法律大模型 法律大模型具备提供基础的法律咨询,完成简单的法律专业文书写作等功能。https://github.com/PKU-YuanGroup/ChatLaw (北京大学)
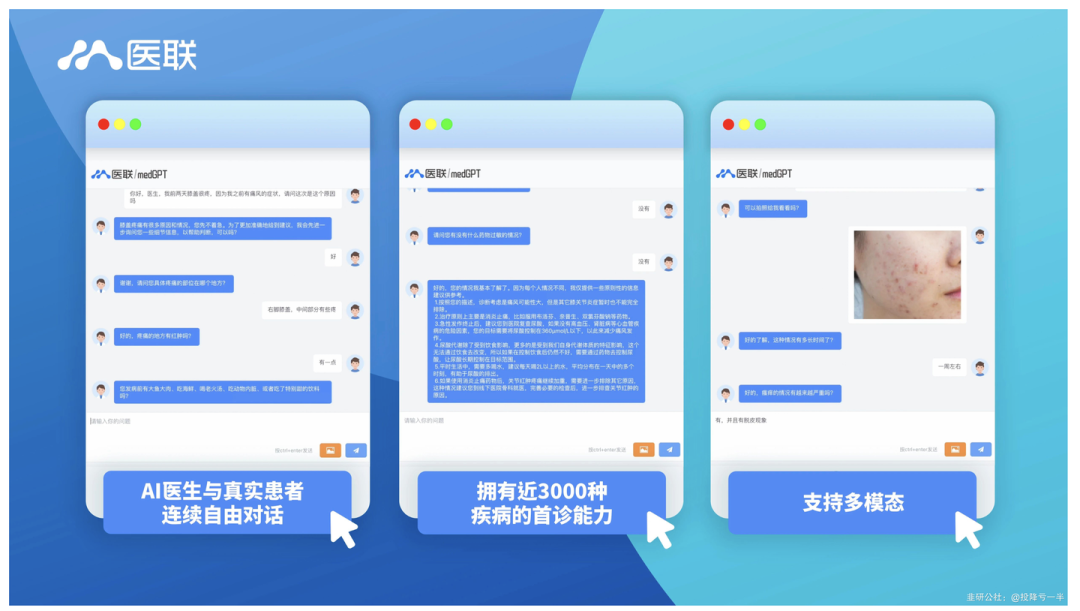
医疗大模型 医疗大模型能给人们进行问诊,并支持多模态的输入。https://www.jiuyangongshe.com/a/dvb0030135 (医联)
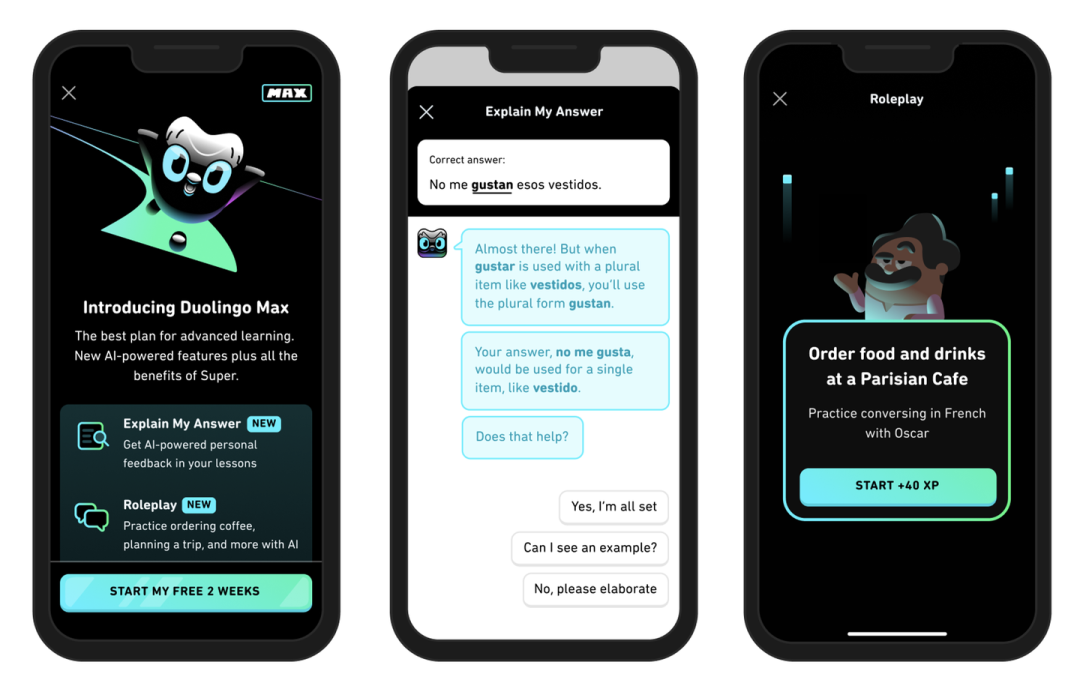
教育大模型 多邻国的教育大模型能提供语言学习上的支持,例如答案解析,学习内容规划等。https://blog.duolingo.com/duolingo-max/ (多邻国)
金融大模型 金融领域大模型数量众多,基本的应用场景也围绕金融的日常工作,例如研报解读等。

垂直大模型基本套路
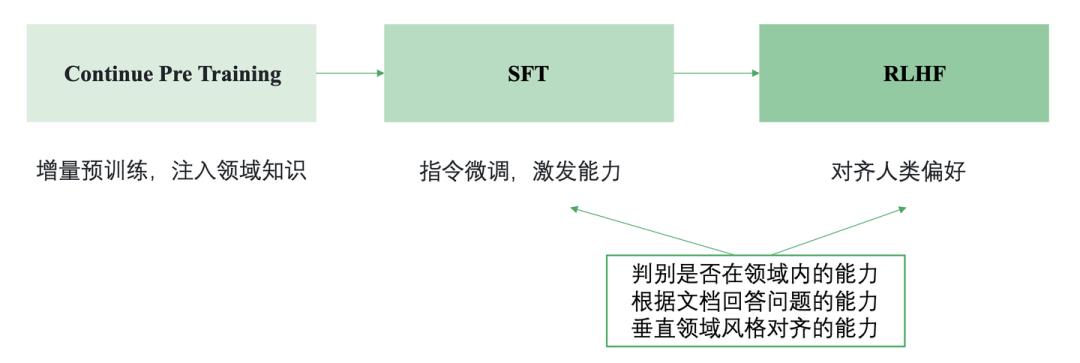
参考通用的大模型的训练流程,可以得出垂直领域大模型的基本套路。
-
Continue PreTraining: 一般垂直大模型是基于通用大模型进行二次的开发。为了给模型注入领域知识,就需要用领域内的语料进行继续的预训练。
-
SFT: 通过SFT可以激发大模型理解领域内各种问题并进行回答的能力(在有召回知识的基础上)
-
RLHF: 通过RLHF可以让大模型的回答对齐人们的偏好,比如行文的风格。
需要注意的是一般垂直领域大模型不会直接让模型生成答案,而是跟先检索相关的知识,然后基于召回的知识进行回答,也就是基于检索增强的生成(Retrieval Augmented Generation , RAG)。这种方式能减少模型的幻觉,保证答案的时效性,还能快速干预模型对特定问题的答案。
所以SFT和RLHF阶段主要要培养模型的三个能力:
(1) 领域内问题的判别能力,对领域外的问题需要能拒识 (2) 基于召回的知识回答问题的能力 (3) 领域内风格对齐的能力,例如什么问题要简短回答什么问题要翔实回答,以及措辞风格要与领域内的专业人士对齐。
下面本文将从继续预训练,领域微调数据构建,减少幻觉,知识召回四个方面进行具体的介绍。
继续预训练
重要的一步
通过继续预训练能给通用的大模型注入领域知识,领域内的专业词能更充分的学习。这部分只需要准备领域内的语料即可,然后进行LLM任务的继续训练。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









