



论文地址:https://arxiv.org/abs/2401.15884
到目前为止,RAG 已成为解决情境学习数据相关性的公认且完善的标准。但是,当检索到不准确的数据时,模型的行为令人担忧。
2024 年 2 月 5 日
检索质量评估器,就是类似ragas这类框架的配合。
介绍
随着自然语言处理技术的发展,基于检索的生成(Retrieval Augmented Generation,简称RAG)领域不断涌现出创新成果。其中,一种称为代理RAG(Agentic RAG)的前沿进展尤为引人注目,它通过引入分层代理机制来革新RAG的执行方式。这种代理架构允许模型跨越多种文档源,采取层次化、多维度的搜索策略,将来自不同来源的信息融合成一个连贯且精准的答案。
与此同时,众多研究聚焦于检索信息的品质分类及其在生成上下文中的学习效果,以期更好地理解和利用检索到的知识。然而,鉴于检索错误可能导致生成结果的不准确甚至误导性,科研人员提出了纠正性检索增强生成(Corrective Retrieval Augmented Generation,CRAG)这一概念,旨在强化生成过程对检索错误的抵抗力。
CRAG的核心部件之一是一款轻巧高效的检索评估器,它能对针对特定查询所获得的检索文档进行全面质量评估,并基于评估结果产出一个反映文档可信程度的置信度指标。根据这个置信度,系统将有针对性地触发不同的知识检索行动,以确保生成结果的准确性。
考虑到静态和有限规模语料库在信息检索方面的局限性,CRAG巧妙地结合了大规模网络搜索技术,借此拓宽检索视野,增加信息来源的多样性和广度,从而增强检索结果的质量。
为进一步优化检索文档的利用效率,CRAG采用了一种独特的分解-重组算法,该算法首先将检索到的文档解构为关键信息块,随后针对性地筛选重要信息,摒弃无关紧要的细节,最后再将其重新组织成有利于生成过程的结构化知识。
CRAG的设计极具通用性,能够作为即插即用的组件,轻松地与各类基于RAG的生成方法紧密结合。实验证据显示,在涵盖短篇及长篇生成任务的四个代表性数据集上,CRAG的应用均能显著提升原有RAG方法的性能表现,有力证明了其在提高生成系统稳健性和知识利用率方面的卓越成效。
CRAG概述
考虑到下方的图表,构建了一个检索评估器来评估检索到的文档与输入的相关性。基于此,可以触发不同的知识检索动作,如正确、错误、模糊的置信度估计。
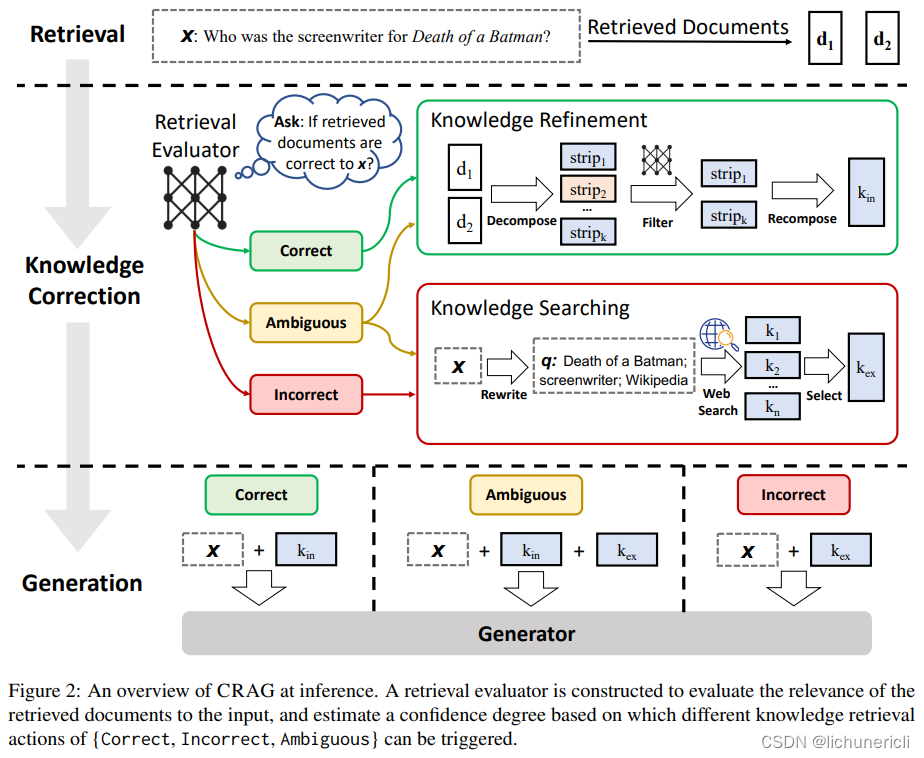
为了应对大型语言模型在生成文本时可能出现的不准确性和臆想问题,研究者们提出了纠正性检索增强生成(Corrective Retrieval-Augmented Generation, CRAG)这一创新方法,旨在增强生成过程对检索结果的自我纠错能力和文档利用率。CRAG的核心在于设计了一个轻量级的检索评估器,该评估器扮演着关键角色,通过对给定查询所检索到的文档进行全面质量评估,衡量其与输入请求的相关性和可靠性。
在CRAG框架内,检索评估器对每份文档计算出一个量化置信度值,基于这个置信度指标,系统能够智能化地触发不同类型的知识检索动作,如确认文档正确、标记文档错误或标识文档含义模糊不清。特别是当评估器判定检索结果可能不准确或模棱两可时,CRAG系统并不满足于现有静态和有限大小语料库内的检索结果,而是前瞻性地引入大规模网络搜索技术,从更广阔的互联网环境中搜索补充信息,从而扩展和丰富原始检索结果的覆盖范围和多样性。
此外,CRAG还引入了一种精细化处理检索文档内容的策略,即采用分解-再重组算法贯穿整个检索和利用流程。这一算法通过细致筛选和重组检索到的文档内容,侧重关注那些对生成任务至关重要的关键信息,同时有效滤除冗余和不相关的上下文背景,确保RAG系统能高效利用并提炼出最有价值的知识点,最大程度地减少了无关要素对生成过程的影响。
总之,CRAG作为一个即插即用的解决方案,不仅提高了检索准确性,而且增强了生成系统对检索失败场景的适应性和鲁棒性。经由在涵盖短篇和长篇生成任务的不同数据集上的广泛实验验证,CRAG成功地显著提升了基于RAG方法的性能表现,彰显了其在不同场景下的广泛应用潜力和普适性。
检索评估器
从上述图表中可以清楚地看出,检索评估器的准确性在决定整个系统性能方面起着至关重要的作用。该算法确保了检索信息的精炼,优化了关键见解的提取并最小化了非必要元素的包含,从而提高了检索数据的使用效率。

CRAG(纠正性检索增强生成)中的检索评估器是为了解决大型语言模型在生成过程中过于依赖检索结果且可能遇到检索错误的问题而特别设计的。为了提升检索结果的质量和生成的鲁棒性,该评估器具备以下特点:
- 轻量化设计:构建了一个轻量级的检索评估器,它的主要功能是对每个输入查询所得到的检索文档进行整体质量评估。
- 触发三种知识检索动作:根据评估器对每份检索文档与输入问题相关性的量化评估,系统可以触发“正确”、“不正确”或“模糊”这三种不同的知识检索操作。
- 量化置信度:评估器会给出一个基于文档相关性的置信度分数,这个分数用于决定后续处理流程——如果认为检索结果不准确或存在歧义,系统将触发相应的纠正机制。
- 网络搜索整合:对于不正确或模糊的检索结果,CRAG会借助大规模网络搜索技术拓展检索范围,从而找到更多相关的、高质量的知识来源。
- 信息细化:在检索和利用阶段使用了分解-再组合算法,该算法能精细筛选出检索文档中对生成任务至关重要的部分,同时剔除冗余和非关键信息,确保了检索数据的有效利用。
因此,CRAG的检索评估器通过综合分析和智能判断检索文档的相关性和可靠性,实现了对检索结果的实时评估和自动纠正,提高了整个生成系统的稳定性和准确性。但需要注意的是,构建这样一个评估器还需要进行微调以适应不同的RAG框架,同时也要警惕由网络搜索引入的潜在偏差,因为互联网资源质量参差不齐,未经充分筛选的数据可能会引入噪声或误导性信息。
构建CRAG(纠正性检索增强生成)中的轻量级检索评估器采用了如下步骤:
- 模型选择与初始化:选用T5-large预训练模型作为基础模型,它相比当前最新的大型语言模型更为小巧,拥有较小的参数规模。这意味着它可以更快捷高效地执行评估任务,并降低计算成本。
- 微调:通过在现有数据集上进行微调来训练检索评估器,使其能够识别和判断检索结果与查询之间的相关性。这些数据集例如PopQA等提供了金标准的相关信号,如问题对应维基百科页面标题等,可用于追踪并非完全相关但质量较高的篇章,以此作为评估器的正样本标签进行训练。
- 负样本构造:为了完善训练,随机采样生成负样本,也可以利用Self-RAG项目提供的版本作为负样本集合。
- 样本划分:在确保实验结果可比性的同时,合理划分数据集,保留一部分数据用于微调而不造成信息泄露,另一部分则用于测试。
- 预测与评估:在实际应用中,对于每个输入问题,检索系统通常会返回多份文档(例如10份)。将问题与每一份单独的文档拼接起来作为评估器的输入,然后评估器分别预测每一对问题-文档的相关性得分。
经过上述步骤,检索评估器能够在给定问题与检索文档之间计算相关性评分,进而基于这些评分确定检索结果是否正确,并相应地触发“正确”、“不正确”或“模糊”等不同级别的知识检索行动。最终,这个轻量级检索评估器成为CRAG系统中一个关键组成部分,它能在生成过程之前及时发现并纠正不相关或误导性的检索信息,从而显著改善生成文本的质量和准确性。
结论
本研究着重探讨了大型语言模型在生成文本时,当检索模块未能准确提供相关信息时,基于检索增强生成(RAG)方法面临的风险,即可能将错误或误导性的知识注入到生成的语言中。为解决这一关键难题,研究团队开发了一种名为纠正性检索增强生成(Corrective Retrieval Augmented Generation,CRAG)的新颖技术方案。
CRAG致力于提升生成过程的鲁棒性,设计为一种可无缝嵌入到现有RAG架构中的即插即用工具,旨在减轻因检索不准确而导致的问题影响。其核心技术包括部署一个轻量级的检索评估器,该评估器能够对针对特定查询检索到的文档进行详尽的评价,量化文档与查询的相关性及可靠性,并基于此触发三个不同等级的知识检索动作:正确的、错误的或模糊不清的。
为了应对静态和有限数据集检索存在的局限性,CRAG进一步结合了大规模的网络搜索功能,以扩展和增强检索结果的覆盖面和多样性,确保模型能够获取更全面、更新鲜的知识资源。同时,CRAG还创新性地应用了一种分解后再重组的算法流程,该算法在检索和利用文档信息的过程中发挥关键作用,通过精细化地挑选关键信息并过滤掉无关的冗余内容,显著提高了检索数据的实际利用率。
在实验环节中,研究者将CRAG成功地融入到标准RAG和先进的Self-RAG框架中,证实了CRAG对各类基于RAG方法的广泛适应性。通过在包括PopQA、Biography、Pub Health和Arc-Challenge在内的四个不同数据集上开展的实验表明,无论是在短篇还是长篇生成任务中,CRAG都能大幅度提升原有RAG方法的性能,展现出了强大的泛化能力和普遍适用性。然而,研究也指出,尽管CRAG在增强生成鲁棒性和提高检索效能方面取得了积极成果,但仍需继续深入研究如何更精确、更有效地检测和纠正错误知识,以及如何妥善应对网络搜索可能引入的潜在偏见问题,从而为未来的RAG研究奠定更为坚实的基础。

















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









