




 分布式深度神经网络(DDNN)允许在云端、边缘和终端设备上进行推理,实现传感器融合、系统容错性和数据隐私。DDNN通过在分布式计算层次结构中映射神经网络部分并进行联合训练,减少了通信成本,提高了精度。实验表明,DDNN比传统方法更节省通信资源,同时保持高精度,并具备容错性和隐私保护能力。
分布式深度神经网络(DDNN)允许在云端、边缘和终端设备上进行推理,实现传感器融合、系统容错性和数据隐私。DDNN通过在分布式计算层次结构中映射神经网络部分并进行联合训练,减少了通信成本,提高了精度。实验表明,DDNN比传统方法更节省通信资源,同时保持高精度,并具备容错性和隐私保护能力。
本文出自论文 Distributed Deep Neural Networks over the Cloud,the Edge and End Devices
,是一种分布式的深度神经网络,可以在本地终端设备、边缘和云端进行网络推理。
一、简介
分布式深度神经网络不仅能够允许在云端进行深度神经网络的推理,还允许在边缘和终端设备上使用神经网络的浅层部分进行快速、本地化推理。在可伸缩的分布式计算层次结构的支持下,DDNN可以在神经网络规模上进行扩展和在地理范围上扩展。由于分布式的性质,DDNNs增强了传感器融合、系统容错性和数据隐私性。在实现DDNN时,我们将DNN部分映射到分布式计算层次结构下。通过联合训练这些部分,我们最小化设备的通信和资源使用量,最大化利用云计算中提取的特性。DDNN可以利用传感器的地理多样性来提高目标识别的准确性和降低通信成本。在实验中,与传统的将原始传感器数据在云中进行处理的方法相比,DDNN局部处理终端设备上的大部分传感器数据,同时获得了较高的精度。
二、提出原因
- 目前机器学习系统在终端设备上的状态有着不太令人满意的选择:
(1)将输入传感器中的数据卸载到云端的大型神经网络模型中,并承担着相应的通信成本、延迟问题和隐私问题;
(2)使用简单的机器学习模型,如SVM,直接在终端设备上进行分类,会导致系统的精确度下降。因此,使用由云端、边缘和设备组成的分层分布式计算结构,对于基于地理分布式物理网设备的大规模智能任务,具有很多内在优势,例如:支持协调中心和本地决策、提供系统可扩展性。 - 这种分布式方法的一个例子是将终端设备的小型神经网络模型(参数数量较少)和云端中较大的神经网络模型(参数数量较多)进行结合。终端设备上的小型模型可以快速地进行初始特征提取,在模型可信的情况下还可以进行分类任务。然后,终端设备处理后的数据会传递到云端的大型网络模型中,进行下一步的特征处理和最终分类。这种方法与传统的神经网络模型相比,具有通信成本低、精确度高的优点。另外,传递到云端的数据已经被终端设备所处理过,不是原始的传感器数据,因此系统可以提供更好的隐私保护。
- 这种基于计算层次结构的分布式方法也具有挑战性:
(1)像嵌入式传感器节点这样的终端设备通常内存和电池预算有限,在满足所需精度和能量约束的设备上安装网络模型较为困难;
(2)在计算节点之间传输中间结果时,在计算层次上直接划分神经网络模型可能会产生很大的通信成本;
(3)当使用不同终端设备上的多个传感器输入时,需要将它们聚合在一起才能实现单个分类目标,一个好的神经网络结构将能够支持这样的传感器融合;
(4)在云端、边缘和设备上的多个模型需要联合学习,以便协调决策;
(5)一个分布式神经网络的逐层处理并不能直接为神经网络早期的快速推理(如终端设备)提供一种处理机制;
(6)在给定的分布式计算层下,需要在模型的准确性(以及相关的模型大小)和上一层的通信成本之间进行平衡。
三、总体方案
1. DDNN架构
一种新的DDNN框架和它将DNN的部分映射到分布式计算层次结构。在DDNN中,我们使用BNNs,eBNNs等来容纳终端设备,使它们可以与边缘和云中的神经网络层进行联合训练。在分布式神经网络中,退出点被放置在物理边界上(终端设备的最后一个神经网络层和分布式计算层次结构的接下来的较高层的第一个神经网络层之间)。能够被提前分类的样本在本地退出,从而实现较低的响应延迟,并将通信保存到下一个物理边界。
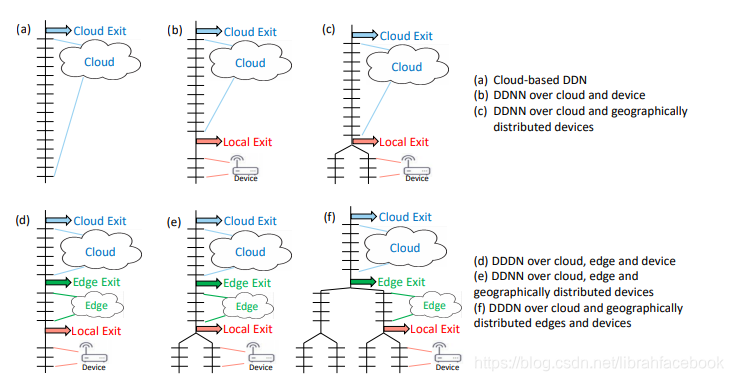
2. DDNN聚合方法
(1)最大池化(Max pooling),通过获取每个分量的最大值来聚合输入向量;
v ^ j = max 1 ⩽ i ⩽ n v i j \hat{v}_j=\max_{1\leqslant i \leqslant n} v_{ij} v^j=1⩽i⩽nmaxvij
(2)平均池化(Average pooling),通过获取每个分量的平均值来聚合输入向量;
v ^ j = ∑ i = 1 n v i j n \hat{v}_j=\sum_{i=1}^n \frac {v_{ij}}{n} v^j=i=1∑nn
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







