







celery是一个基于分布式消息传输的异步任务队列,它专注于实时处理,同时也支持任务调度。关于celery的更多介绍及例子,笔者可以参考文章[Python之celery的简介与使用]。
本文将介绍如何使用celery来加速爬虫。
本文爬虫的例子来自文章:[Python爬虫的N种姿势]。这里不再过多介绍,我们的项目结构如下:
项目结构
其中,app_test.py为主程序,其代码如下:
from celery import Celery
app = Celery('proj', include=['proj.tasks'])
app.config_from_object('proj.celeryconfig')
if __name__ == '__main__':
app.start()
tasks.py为任务函数,代码如下:
import re
import requests
from celery import group
from proj.app_test import app
@app.task(trail=True)
# 并行调用任务
def get_content(urls):
return group(C.s(url) for url in urls)()
@app.task(trail=True)
def C(url):
return parser.delay(url)
@app.task(trail=True)
# 获取每个网页的name和description
def parser(url):
req = requests.get(url)
html = req.text
try:
name = re.findall(r'<span class="wikibase-title-label">(.+?)</span>', html)[0]
desc = re.findall(r'<span class="wikibase-descriptionview-text">(.+?)</span>', html)[0]
if name is not None and desc is not None:
return name, desc
except Exception as err:
return '', ''
celeryconfig.py为celery的配置文件,代码如下:
BROKER_URL = 'redis://localhost' # 使用Redis作为消息代理
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0' # 把任务结果存在了Redis
CELERY_TASK_SERIALIZER = 'msgpack' # 任务序列化和反序列化使用msgpack方案
CELERY_RESULT_SERIALIZER = 'json' # 读取任务结果一般性能要求不高,所以使用了可读性更好的JSON
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 任务过期时间
CELERY_ACCEPT_CONTENT = ['json', 'msgpack'] # 指定接受的内容类型
最后是我们的爬虫文件,scrapy.py,代码如下:
import time
import requests
from bs4 import BeautifulSoup
from proj.tasks import get_content
t1 = time.time()
url = "http://www.wikidata.org/w/index.php?title=Special:WhatLinksHere/Q5&limit=500&from=0"
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, \
like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
# 发送HTTP请求
req = requests.get(url, headers=headers)
# 解析网页
soup = BeautifulSoup(req.text, "lxml")
# 找到name和Description所在的记录
human_list = soup.find(id='mw-whatlinkshere-list')('li')
urls = []
# 获取网址
for human in human_list:
url = human.find('a')['href']
urls.append('https://www.wikidata.org'+url)
#print(urls)
# 调用get_content函数,并获取爬虫结果
result = get_content.delay(urls)
res = [v for v in result.collect()]
for r in res:
if isinstance(r[1], list) and isinstance(r[1][0], str):
print(r[1])
t2 = time.time() # 结束时间
print('耗时:%s' % (t2 - t1))
在后台启动redis,并切换至proj项目所在目录,运行命令:
celery -A proj.app_test worker -l info
输出结果如下(只显示最后几行的输出):
......
['Antoine de Saint-Exupery', 'French writer and aviator']
['', '']
['Sir John Barrow, 1st Baronet', 'English statesman']
['Amy Johnson', 'pioneering English aviator']
['Mike Oldfield', 'English musician, multi-instrumentalist']
['Willoughby Newton', 'politician from Virginia, USA']
['Mack Wilberg', 'American conductor']
耗时:80.05160284042358
在rdm中查看数据,如下:
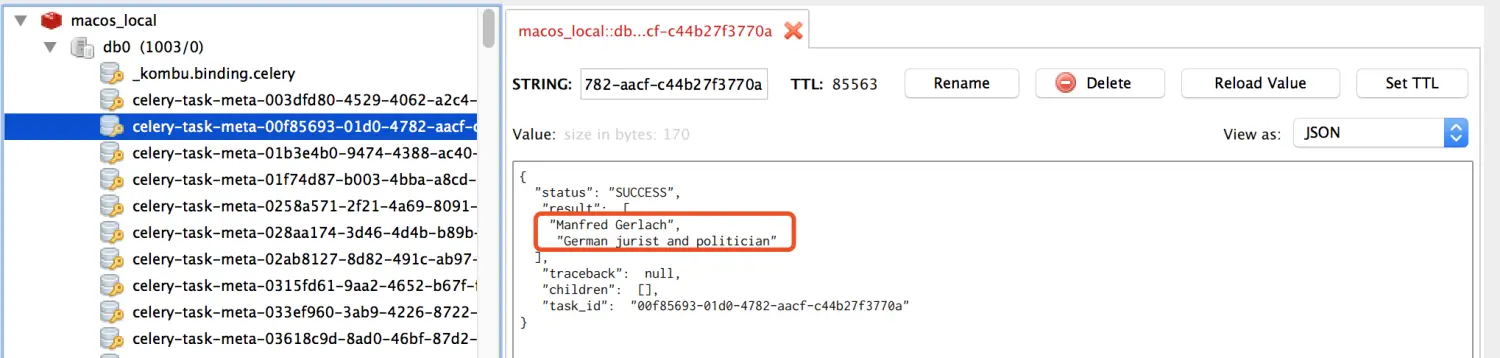
读者福利:知道你对Python感兴趣,便准备了这套python学习资料
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等习教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉100道Python练习题👈
检查学习结果。

👉面试刷题👈


👉python副业兼职与全职路线👈

上述这份完整版的Python全套学习资料已经上传优快云官方,朋友们如果需要可以微信扫描下方优快云官方认证二维码 即可领取↓↓↓


















 1713
1713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









